scrapy抓取国家社科基金项目数据库
1.明确任务
目标网站:http://fz.people.com.cn/skygb/sk/index.php/Index/seach
抓取任务:抓取近五年某关键词(例如"能源"、”大数据“等)的搜索结果,抓取内容包括项目编号、项目名称、学科分类等十一个字段。
2.网站分析
利用Fiddler工具分析,输入关键词,指定年份后,点击搜索,针对有多页码搜索结果点击下一页,发现此过程共包括一个POST请求和一个GET请求;其中,指定关键词和年份点击搜索的过程为POST请求,点击下一页的过程为GET请求。
POST请求参数:
formdata = {
'xmname': '',
'xktype': '',
'xmtype': '',
'cglevel': '',
'cbdate ': '',
'cgxs': '',
'lxtime': '',
'ssxt': '',
'zyzw': '',
'dwtype': '',
'jxdata': '',
'szdq': '',
'pznum': '',
'cgname': '',
'jxnum': '',
'cbs': '',
'xmleader': '',
'hj': '',
'gzdw': '',
'zz': ''
}
POST请求目标URL:http://fz.people.com.cn/skygb/sk/index.php/Index/seach
GET请求只需要指定参数p即可,因此构造GET请求url为:
n_url = self.url + '?' + 'xmname={}&p={}'.format(formdata['xmname'], self.page)
其中,xmname为搜索关键词,p为第几页的页码。
3.代码编写
3.1 创建scrapy爬虫项目
创建项目,名为ProSearch,使用命令:
scrapy startproject ProSearch http://fz.people.com.cn
3.2 明确抓取字段
创建爬虫项目后,编写items.py文件,明确待抓取的字段
# -*- coding: utf-8 -*-
import scrapy
class ProsearchItem(scrapy.Item): # 关键词
keyword = scrapy.Field()
# 项目编号
pronums = scrapy.Field()
# 项目类别
protype = scrapy.Field()
# 学科类别
subtype = scrapy.Field()
# 项目名称
proname = scrapy.Field()
# 立项时间
protime = scrapy.Field()
# 负责人
leaders = scrapy.Field()
# 工作单位
workloc = scrapy.Field()
# 单位类别
orgtype = scrapy.Field()
# 所在省市
provloc = scrapy.Field()
# 所属系统
systloc = scrapy.Field()
3.3 生成爬虫文件
在cmd窗口进入到ProSearch项目后,生成爬虫文件。使用命令:
scrapy genspider SearchPro
3.4 编写爬虫逻辑
生成爬虫文件后,来到spiders文件夹下的SearchPro.py文件,开始辨写爬虫逻辑。
# -*- coding: utf-8 -*-
import scrapy
from ProSearch.items import ProsearchItem class SearchproSpider(scrapy.Spider): name = 'SearchPro' # 爬虫名称
allowed_domains = ['fz.people.com.cn']
# start_urls = ['http://fz.people.com.cn/skygb/sk/index.php/Index/seach']
page = 1 # 指定检索关键词
keywords = ['可持续', '互联网', '大数据', '能源']
# 角标
index = 0
# 年份
years = 2018 # POST提交参数
formdata = {
'xmname': '',
'xktype': '',
'xmtype': '',
'cglevel': '',
'cbdate ': '',
'cgxs': '',
'lxtime': '',
'ssxt': '',
'zyzw': '',
'dwtype': '',
'jxdata': '',
'szdq': '',
'pznum': '',
'cgname': '',
'jxnum': '',
'cbs': '',
'xmleader': '',
'hj': '',
'gzdw': '',
'zz': ''
} # 参数提交的url
url = "http://fz.people.com.cn/skygb/sk/index.php/Index/seach" def start_requests(self):
"""
POST请求实现一般是重写start_requests函数,指定第一个关键词为默认检索关键词
:return:
"""
self.formdata['xmname'] = '可持续'
self.formdata['lxtime'] = str(self.years)
yield scrapy.FormRequest(
url=self.url,
formdata=self.formdata,
callback=self.parse,
meta={'formdata': self.formdata}
) def parse(self, response):
"""
解析数据
:param response:
:return:
"""
if response.meta['formdata']:
formdata = response.meta['formdata'] # 每行数据所在节点
try:
node_list = response.xpath("//div[@class='jc_a']/table/*")[1:]
except:
print("关键词‘{}’无搜索结果!".format(formdata['xmname']))
for node in node_list:
# 提取数据
item = ProsearchItem()
# 关键词
item['keyword'] = formdata['xmname']
# 项目编号
item['pronums'] = node.xpath('./td[1]/span/text()').extract_first()
# 项目类别
item['protype'] = node.xpath('./td[2]/span/text()').extract_first()
# 学科类别
item['subtype'] = node.xpath('./td[3]/span/text()').extract_first()
# 项目名称
item['proname'] = node.xpath('./td[4]/span/text()').extract_first()
# 立项时间
item['protime'] = node.xpath('./td[5]/span/text()').extract_first()
# 负责人
item['leaders'] = node.xpath('./td[6]/span/text()').extract_first()
# 工作单位
item['workloc'] = node.xpath('./td[8]/span/text()').extract_first()
# 单位类别
item['orgtype'] = node.xpath('./td[9]/span/text()').extract_first()
# 所属省市
item['provloc'] = node.xpath('./td[10]/span/text()').extract_first()
# 所属系统
item['systloc'] = node.xpath('./td[11]/span/text()').extract_first()
yield item # 匹配下一页的数据
if '下一页' in response.xpath("//div[@class='page clear']/a").extract():
self.page += 1
n_url = self.url + '?' + 'xmname={}&p={}'.format(formdata['xmname'], self.page)
yield scrapy.Request(url=n_url, callback=self.parse, meta={'formdata': formdata}) # 匹配其他年份的数据
searcy_year = int(formdata['lxtime'])
if not searcy_year <= 2014:
searcy_year -= 1
formdata['lxtime'] = str(searcy_year)
print("检索关键词:{}!".format(formdata['xmname']))
yield scrapy.FormRequest(
url=self.url,
formdata=formdata,
callback=self.parse,
meta={'formdata': formdata}
)
# 其他关键词搜索
else:
self.index += 1
if not self.index > len(self.keywords)-1:
keyword = self.keywords[self.index]
print("更新检索关键词为:{}".format(keyword)) formdata['xmname'] = keyword
formdata['lxtime'] = str(self.years) yield scrapy.FormRequest(
url=self.url,
formdata=formdata,
callback=self.parse,
meta={'formdata': formdata}
)
3.5 编写数据保存逻辑
本项目用excel对数据进行保存。在pipelines.py文件中编写数据保存的逻辑。
# -*- coding: utf-8 -*-
from openpyxl import Workbook class ProsearchPipeline(object): def __init__(self):
# 创建excel表格保存数据
self.workbook = Workbook()
self.booksheet = self.workbook.active
self.booksheet.append(['关键词', '项目编号', '项目类别', '学科类别', '项目名称', '立项时间', '负责人', '工作单位', '单位类别', '所在省市', '所属系统']) def process_item(self, item, spider): DATA = [
item['keyword'], item['pronums'], item['protype'], item['subtype'], item['proname'], item['protime'], item['leaders'], item['workloc'], item['orgtype'], item['provloc'], item['systloc']
] self.booksheet.append(DATA)
self.workbook.save('./data/ProSearch.xls')
return item
3.6 其他细节
到此基本内容完成,设置一下settings.py文件对细节进行处理基本爬虫就可以运行了。
处理一:打开pipline通道
处理二:添加随机请求头并打开下载中间件
处理三:添加重拾、延时、log级别等
处理四:编写脚本main.py文件
scrapy默认使用命令行进行创建、生成、爬去等任务,可尝试在整个项目下编写一个main.py文件,将爬去命令添加到py文件中,直接在编辑器中F5运行。
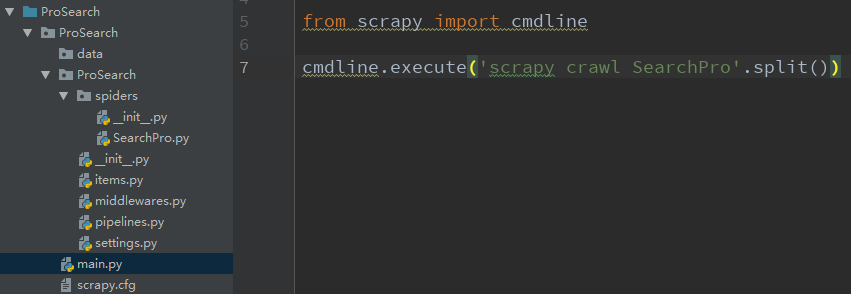
下次每次运行main.py文件就可以直接运行了。
4.完整代码
scrapy抓取国家社科基金项目数据库的更多相关文章
- 通过Scrapy抓取QQ空间
毕业设计题目就是用Scrapy抓取QQ空间的数据,最近毕业设计弄完了,来总结以下: 首先是模拟登录的问题: 由于Tencent对模拟登录比较讨厌,各个防备,而本人能力有限,所以做的最简单的,手动登录后 ...
- python scrapy 抓取脚本之家文章(scrapy 入门使用简介)
老早之前就听说过python的scrapy.这是一个分布式爬虫的框架,可以让你轻松写出高性能的分布式异步爬虫.使用框架的最大好处当然就是不同重复造轮子了,因为有很多东西框架当中都有了,直接拿过来使用就 ...
- scrapy抓取淘宝女郎
scrapy抓取淘宝女郎 准备工作 首先在淘宝女郎的首页这里查看,当然想要爬取更多的话,当然这里要查看翻页的url,不过这操蛋的地方就是这里的翻页是使用javascript加载的,这个就有点尴尬了,找 ...
- scrapy抓取拉勾网职位信息(一)——scrapy初识及lagou爬虫项目建立
本次以scrapy抓取拉勾网职位信息作为scrapy学习的一个实战演练 python版本:3.7.1 框架:scrapy(pip直接安装可能会报错,如果是vc++环境不满足,建议直接安装一个visua ...
- scrapy抓取的中文结果乱码解决办法
使用scrapy抓取的结果,中文默认是Unicode,无法显示中文. 中文默认是Unicode,如: \u5317\u4eac\u5927\u5b66 在setting文件中设置: FEED_EXPO ...
- 分布式爬虫:使用Scrapy抓取数据
分布式爬虫:使用Scrapy抓取数据 Scrapy是Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘. ...
- 解决Scrapy抓取中文网页保存为json文件时中文不显示而是显示unicode的问题
注意:此方法跟之前保存成json文件的写法有少许不同之处,注意区分 情境再现: 使用scrapy抓取中文网页,得到的数据类型是unicode,在控制台输出的话也是显示unicode,如下所示 {'au ...
- scrapy抓取中国新闻网新闻
目标说明 利用scrapy抓取中新网新闻,关于自然灾害滑坡的全部国内新闻:要求主题为滑坡类新闻,包含灾害造成的经济损失等相关内容,并结合textrank算法,得到每篇新闻的关键词,便于后续文本挖掘分析 ...
- scrapy抓取斗鱼APP主播信息
如何进行APP抓包 首先确保手机和电脑连接的是同一个局域网(通过路由器转发的网络,校园网好像还有些问题). 1.安装抓包工具Fiddler,并进行配置 Tools>>options> ...
随机推荐
- 自闭版节奏大C
1,2,3,4打碟 #include <bits/stdc++.h> #include <conio.h> #include <windows.h> using n ...
- [考试反思]0926csp-s模拟测试52:审判
也好. 该来的迟早会来. 反思再说吧. 向下跳过直到另一条分界线 %%%cbx也拿到了他的第一个AK了呢. 我的还是遥不可及. 我恨你,DeepinC. 我恨透你了.你亲手埋葬所有希望,令我无比气愤. ...
- RocketMQ 主从同步若干问题答疑
目录 1.初识主从同步 2.提出问题 3.原理探究 3.1 RocketMQ主从读写分离机制 3.2 消息消费进度同步机制 4.总结 温馨提示:建议参考代码RocketMQ4.4版本,4.5版本引入了 ...
- 开源跳板机(堡垒机)系统 Jumpserver安装教程(带图文)
环境 系统: CentOS 7 IP: 192.168.244.144 关闭 selinux 和防火墙 # CentOS 7 $ setenforce 0 # 可以设置配置文件永久关闭 $ syste ...
- python_day1(初始Python)
1.编码 ASCII (英文1字节,没中文)=> GB => GBK =>uncoode (中英文都2字节) => utf-8 (可变长字节储存,中文3字节,英文1字节) 2. ...
- javascript监听手机返回键
javascript监听手机返回键 <pre> if (window.history && window.history.pushState) { $(window).on ...
- HTML创建图像映射,布局,表单
来源: 实验楼 创建图像映射 在这之前我们动手试验过将图片作为链接来使用,触发链接的方式就是点击图片的任何地方都可以链接到跳转地址,有时我们需要实现,点击图片的不同地方跳转到不同的地方.意思就是,一张 ...
- 树莓派debian配置lamp[解决Apache不显示php网页]
Apache + MySql + Php. 1.安装Apache Apache可以用下面的命令来安装 sudo apt-get install apache2 Apache默认路径是/var/www/ ...
- Mssql 查询某记录前后N条
Sqlserver 查询指定记录前后N条,包括当前数据 条件 [ID] 查询 [N]条 select * from [Table] where ID in (select top ([N]+1) ID ...
- mongodb基本命令,mongodb集群原理分析
mongodb基本命令,mongodb集群原理分析 集合: 1.集合没有固定数据格式. 2. 数据: 时间类型: Date() 当前时间(js时间) new Date() 格林尼治时间(object) ...