spark 源码分析之三 -- LiveListenerBus介绍
LiveListenerBus
官方说明如下:
Asynchronously passes SparkListenerEvents to registered SparkListeners.
即它的功能是异步地将SparkListenerEvent传递给已经注册的SparkListener,这种异步的机制是通过生产消费者模型来实现的。
首先,它定义了 4 个 消息堵塞队列,队列的名字分别为shared、appStatus、executorManagement、eventLog。队列的类型是 org.apache.spark.scheduler.AsyncEventQueue#AsyncEventQueue,保存在 queues 变量中。每一个队列上都可以注册监听器,如果队列没有监听器,则会被移除。
它有启动和stop和start两个标志位来指示 监听总线的的启动停止状态。 如果总线没有启动,有事件过来,先放到 一个待添加的可变数组中,否则直接将事件 post 到每一个队列中。
其直接依赖类是 AsyncEventQueue, 相当于 LiveListenerBus 的多事件队列是对 AsyncEventQueue 进一步的封装。
AsyncEventQueue
其继承关系如下:
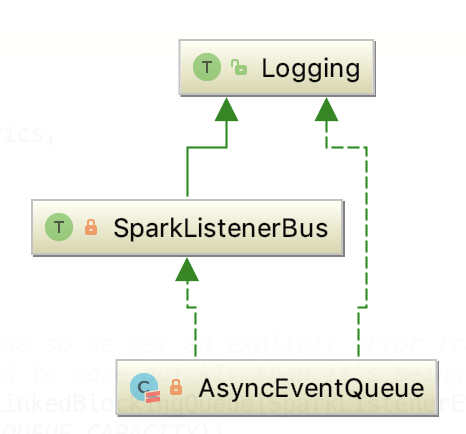
它有启动和stop和start两个标志位来指示 监听总线的的启动停止状态。
其内部维护了listenersPlusTimers 主要就是用来保存注册到这个总线上的监听器对象的。
post 操作将事件放入内部的 LinkedBlockingQueue中,默认大小是 10000。
有一个事件分发器,它不停地从 LinkedBlockingQueue 执行 take 操作,获取事件,并将事件进一步分发给所有的监听器,由org.apache.spark.scheduler.SparkListenerBus#doPostEvent 方法实现事件转发,具体代码如下:
1 protected override def doPostEvent(
2 listener: SparkListenerInterface,
3 event: SparkListenerEvent): Unit = {
4 event match {
5 case stageSubmitted: SparkListenerStageSubmitted =>
6 listener.onStageSubmitted(stageSubmitted)
7 case stageCompleted: SparkListenerStageCompleted =>
8 listener.onStageCompleted(stageCompleted)
9 case jobStart: SparkListenerJobStart =>
10 listener.onJobStart(jobStart)
11 case jobEnd: SparkListenerJobEnd =>
12 listener.onJobEnd(jobEnd)
13 case taskStart: SparkListenerTaskStart =>
14 listener.onTaskStart(taskStart)
15 case taskGettingResult: SparkListenerTaskGettingResult =>
16 listener.onTaskGettingResult(taskGettingResult)
17 case taskEnd: SparkListenerTaskEnd =>
18 listener.onTaskEnd(taskEnd)
19 case environmentUpdate: SparkListenerEnvironmentUpdate =>
20 listener.onEnvironmentUpdate(environmentUpdate)
21 case blockManagerAdded: SparkListenerBlockManagerAdded =>
22 listener.onBlockManagerAdded(blockManagerAdded)
23 case blockManagerRemoved: SparkListenerBlockManagerRemoved =>
24 listener.onBlockManagerRemoved(blockManagerRemoved)
25 case unpersistRDD: SparkListenerUnpersistRDD =>
26 listener.onUnpersistRDD(unpersistRDD)
27 case applicationStart: SparkListenerApplicationStart =>
28 listener.onApplicationStart(applicationStart)
29 case applicationEnd: SparkListenerApplicationEnd =>
30 listener.onApplicationEnd(applicationEnd)
31 case metricsUpdate: SparkListenerExecutorMetricsUpdate =>
32 listener.onExecutorMetricsUpdate(metricsUpdate)
33 case executorAdded: SparkListenerExecutorAdded =>
34 listener.onExecutorAdded(executorAdded)
35 case executorRemoved: SparkListenerExecutorRemoved =>
36 listener.onExecutorRemoved(executorRemoved)
37 case executorBlacklistedForStage: SparkListenerExecutorBlacklistedForStage =>
38 listener.onExecutorBlacklistedForStage(executorBlacklistedForStage)
39 case nodeBlacklistedForStage: SparkListenerNodeBlacklistedForStage =>
40 listener.onNodeBlacklistedForStage(nodeBlacklistedForStage)
41 case executorBlacklisted: SparkListenerExecutorBlacklisted =>
42 listener.onExecutorBlacklisted(executorBlacklisted)
43 case executorUnblacklisted: SparkListenerExecutorUnblacklisted =>
44 listener.onExecutorUnblacklisted(executorUnblacklisted)
45 case nodeBlacklisted: SparkListenerNodeBlacklisted =>
46 listener.onNodeBlacklisted(nodeBlacklisted)
47 case nodeUnblacklisted: SparkListenerNodeUnblacklisted =>
48 listener.onNodeUnblacklisted(nodeUnblacklisted)
49 case blockUpdated: SparkListenerBlockUpdated =>
50 listener.onBlockUpdated(blockUpdated)
51 case speculativeTaskSubmitted: SparkListenerSpeculativeTaskSubmitted =>
52 listener.onSpeculativeTaskSubmitted(speculativeTaskSubmitted)
53 case _ => listener.onOtherEvent(event)
54 }
55 }
然后去调用 listener 的相对应的方法。
就这样,事件总线上的消息事件被监听器消费了。
spark 源码分析之三 -- LiveListenerBus介绍的更多相关文章
- Spark源码分析之三:Stage划分
继上篇<Spark源码分析之Job的调度模型与运行反馈>之后,我们继续来看第二阶段--Stage划分. Stage划分的大体流程如下图所示: 前面提到,对于JobSubmitted事件,我 ...
- spark 源码分析之十九 -- Stage的提交
引言 上篇 spark 源码分析之十九 -- DAG的生成和Stage的划分 中,主要介绍了下图中的前两个阶段DAG的构建和Stage的划分. 本篇文章主要剖析,Stage是如何提交的. rdd的依赖 ...
- Spark 源码分析系列
如下,是 spark 源码分析系列的一些文章汇总,持续更新中...... Spark RPC spark 源码分析之五--Spark RPC剖析之创建NettyRpcEnv spark 源码分析之六- ...
- spark源码分析以及优化
第一章.spark源码分析之RDD四种依赖关系 一.RDD四种依赖关系 RDD四种依赖关系,分别是 ShuffleDependency.PrunDependency.RangeDependency和O ...
- Spark源码分析(三)-TaskScheduler创建
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3879151.html 在SparkContext创建过程中会调用createTaskScheduler函 ...
- 【转】Spark源码分析之-deploy模块
原文地址:http://jerryshao.me/architecture/2013/04/30/Spark%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%E4%B9%8B- ...
- Spark源码分析:多种部署方式之间的区别与联系(转)
原文链接:Spark源码分析:多种部署方式之间的区别与联系(1) 从官方的文档我们可以知道,Spark的部署方式有很多种:local.Standalone.Mesos.YARN.....不同部署方式的 ...
- Spark源码分析之九:内存管理模型
Spark是现在很流行的一个基于内存的分布式计算框架,既然是基于内存,那么自然而然的,内存的管理就是Spark存储管理的重中之重了.那么,Spark究竟采用什么样的内存管理模型呢?本文就为大家揭开Sp ...
- Spark源码分析之八:Task运行(二)
在<Spark源码分析之七:Task运行(一)>一文中,我们详细叙述了Task运行的整体流程,最终Task被传输到Executor上,启动一个对应的TaskRunner线程,并且在线程池中 ...
随机推荐
- VM中linux和windows主机进行串口通信
最近在做关于AIS的内容.为了对AIS电文进行解码,串口收发. 数据有PC机模拟发送,为了调试方便,不用次次将程序放到开发板上运行,所以利用pc主机和虚拟机进行串口通信模拟该过程. 首先需要用到一个软 ...
- Codility---MaxProductOfThree
Task description A non-empty zero-indexed array A consisting of N integers is given. Theproduct of t ...
- windows pyspider WEB显示框太小解决方法
环境:windows7 + chrome + pyspider 解决方法: WEB预览框过小的原因在于页面元素的css属性height被替换为60px: CSS文件所在地方:C:\Users\Admi ...
- java垃圾回收机制整理
一.垃圾回收器和finalize() java垃圾回收器只负责回收无用对象占据的内存资源.但是如果你的对象不是通过 new 创建的(所有的new 对象都往堆中开辟资源,在一个地方,方便清理/管理资源) ...
- 补习系列(21)-SpringBoot初始化之7招式
目录 背景 1. @PostConstruct 注解 2. InitializingBean 接口 3. @Bean initMethod方法 4. 构造器注入 5. ApplicationListe ...
- 阿里云ECS发送企业邮件
<?phpuse PHPMailer\PHPMailer\PHPMailer;require '../vendor/autoload.php'; $mail = new PHPMailer(tr ...
- php实现redis锁机制
<?php class Redis_lock { public static function getRedis() { $redis = new redis(); $redis->con ...
- SSM(六)JDK动态代理和Cglib动态代理
1.Cglib动态代理 目标类: package cn.happy.proxy.cglib; public class Service { public Service() { System.out. ...
- BZOJ 1085:[SCOI2005]骑士精神(A*算法)
题目链接 题意 中文题意. 思路 首先找到空白的格子,因为空白的格子可以和其他的骑士换.从空白的点开始搜索,每次和其他点交换.因为最多只有十五步,可以做16次搜索,搜索的时候,记录走过的步数和至少剩余 ...
- POJ 2449:Remmarguts' Date(A* + SPFA)
题目链接 题意 给出n个点m条有向边,源点s,汇点t,k.问s到t的第k短路的路径长度是多少,不存在输出-1. 思路 A*算法是启发式搜索,通过一个估价函数 f(p) = g(p) + h(p) ,其 ...