Focal and Global Knowledge Distillation for Detectors
一. 概述
论文地址:链接
代码地址:链接
论文简介:
- 此篇论文是在CGNet上增加部分限制loss而来
- 核心部分是将gt框变为mask进行蒸馏
注释:仅为阅读论文和代码,未进行试验,如有漏错请不吝指出。文章的疑惑和假设仅代表个人想法。
二. 详细
2.1 Focal Distillation
2.1.1 mask计算
此篇文章在目标检测蒸馏中对FPN层进行限制,正常的操作如下公式(1)所示:
\]
此篇文章将gt的mask引入到蒸馏中:
如下公式(2),目标为1,背景为0,获得mask矩阵\(M_{i,j}\)
\]
但是会出现一个问题,小目标的mask区域太小,比例严重失调会导致小目标的蒸馏效果比较差,解决方法是进行归一化操作,如下公式(3)所示,引用一个尺度(缩放)量\(S_{i,j}\) , 前景尺度目标大小倒数,目标越大mask越大,但数值越小。背景为mask=0的倒数。也就是每个gt数值和为1,全部背景为1。
疑惑一: 假设前景gt为10,那么前景数值和为10,背景和为1,会不会导致比例失调?
S_{i, j}= \begin{cases}\frac{1}{H_{r} W_{r}}, & \text { if }(i, j) \in r \\
\frac{1}{N_{b g}}, & \text { Otherwise }\end{cases} \\
N_{b g}=\sum_{i=1}^{H} \sum_{j=1}^{W}\left(1-M_{i, j}\right)
\end{gathered}
\]
假设一: 假设修改为前景和为1,背景和也为1。前景每个gt数值和相同。如下公式(4)所示,\(N_{gt}\) 为gt的数量
S_{i, j}= \begin{cases}\frac{1}{H_{r} W_{r} N_{gt}}, & \text { if }(i, j) \in r \\
\frac{1}{N_{b g}}, & \text { Otherwise }\end{cases} \\
N_{b g}=\sum_{i=1}^{H} \sum_{j=1}^{W}\left(1-M_{i, j}\right)
\end{gathered}
\]
2.1.2 注意力特征计算
这部分参考attention机制,蒸馏也要针对性的对channel和spatial进行学习
以下公式(5)是针对上面两个注意力的计算方式,注意得加绝对值!没有可解释的,就是基础操作。
G^{S}(F)=\frac{1}{C} \cdot \sum_{c=1}^{C}\left|F_{c}\right| \\
G^{C}(F)=\frac{1}{H W} \cdot \sum_{i=1}^{H} \sum_{j=1}^{W}\left|F_{i, j}\right|
\end{gathered}
\]
A^{S}(F)=H \cdot W \cdot \operatorname{softmax}\left(G^{S}(F) / T\right) \\
A^{C}(F)=C \cdot \operatorname{softmax}\left(G^{C}(F) / T\right)
\end{gathered}
\]
2.1.3 loss融合
直接看下面的公式(7),前景和背景分开进行监督,公式比较简单,\(M_{i,j}\)表示mask,\(S_{i,j}\) 表示mask的尺度,\(A_{i,j}^S/A_k^C\) 表示teacher的注意力特征。
&L_{f e a}=\alpha \sum_{k=1}^{C} \sum_{i=1}^{H} \sum_{j=1}^{W} M_{i, j} S_{i, j} A_{i, j}^{S} A_{k}^{C}\left(F_{k, i, j}^{T}-f\left(F_{k, i, j}^{S}\right)\right)^{2} +\beta \sum_{k=1}^{C} \sum_{i=1}^{H} \sum_{j=1}^{W}\left(1-M_{i, j}\right) S_{i, j} A_{i, j}^{S} A_{k}^{C}\left(F_{k, i, j}^{T}-f\left(F_{k, i, j}^{S}\right)\right)^{2}
\end{aligned}
\]
疑惑二: 将上面的公式合并,明显看出 \(\alpha/\beta\) 就表示前景和背景的比例,这明显印证了疑惑一的问题。再从论文图表(7)中调参发现,这两个参数对实际的精度影响不大 \(\pm0.3\) 的精度差异,是否可直接使用假设一的方案,直接去除此两个参数。
由于公式(7)仅对teacher的注意力特征进行了使用,并未对student的注意力特征进行监督,所以引出下面的公式(8)直接监督
\]
疑惑三: 为什么公式(7)需要使用teature注意力特征而不使用student的注意力特征?论文没有给出答案,issue上作者也没有给出答案。
假设三:
- 公式(7)中直接去除 \(A_{i,j}^S/A_k^C\) 是否合适?
- 将公式(8)合并到公式(7)中,比如下式的公式(9)所示,当然可以有其他形式
\]
2.2 Global Distillation
此部分来自于CGNet,不做过多介绍,理解较为容易
三. 题外话
3.1 一些可能的笔误
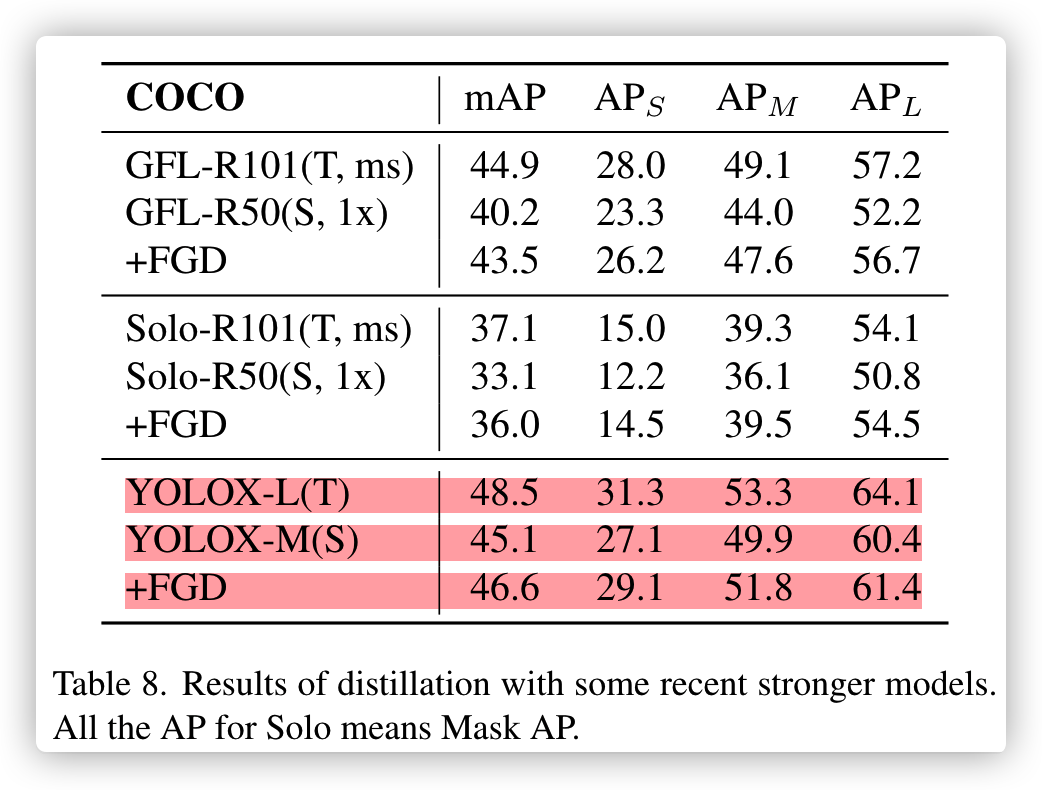
此论文的开源项目基于mmdetection实现,其中试验的YOLOX蒸馏试验有点瑕疵:
- 第一个问题
以下是此论文的项目readme,YOLOX-m的baseline是45.9,但实际YOLOX官方精度是46.9,差一个点已经是非常大了。
作者说用mmdet跑出来YOLOX-m就是这个精度,本人比较怀疑,因为之前跑的YOLOX-S/nano都没问题,YOLOX-m正在试验下周一出结果。
结果: 确实像作者说的达不到官方的精度,本人替换focus到conv,其它未改变,mAP45.2比作者的还低0.7
| Student | Teacher | Baseline(mAP) | +FGD(mAP) | config | weight | code |
|---|---|---|---|---|---|---|
| YOLOX-m | YOLOX-l | 45.9 | 46.6 | config | baidu | af9g |
- 第二个问题
论文中YOLOX-m和repo中的精度不一致,论文45.1,repo是45.9,论文是笔误?
YOLOX-L的精度mmdet已经试验为49.4,为啥这里是48.5?这也是笔误?
3.2 论文观后感
之前见过类似的做法,用作弱监督中。但未看到将mask用作蒸馏之内,这让我开眼界了。
刚开始看论文的效果确实不错,因为本人对YOLOX较为熟悉,所以仔细看了一下这部分,发现上述问题,作者也没重视。。。
以后实际项目尝试一下,这次仅仅作为阅读论文
Focal and Global Knowledge Distillation for Detectors的更多相关文章
- (转)Awesome Knowledge Distillation
Awesome Knowledge Distillation 2018-07-19 10:38:40 Reference:https://github.com/dkozlov/awesome-kno ...
- 2017年最有价值的IT认证——From Global Knowledge
- Feature Fusion for Online Mutual Knowledge Distillation (CVPR 2019)
一.解决问题 如何将特征融合与知识蒸馏结合起来,提高模型性能 二.创新点 支持多子网络分支的在线互学习 子网络可以是相同结构也可以是不同结构 应用特征拼接.depthwise+pointwise,将特 ...
- ICCV 2017论文分析(文本分析)标题词频分析 这算不算大数据 第一步:数据清洗(删除作者和无用的页码)
IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017. IEE ...
- CVPR 2017 Paper list
CVPR2017 paper list Machine Learning 1 Spotlight 1-1A Exclusivity-Consistency Regularized Multi-View ...
- 基于COCO数据集验证的目标检测算法天梯排行榜
基于COCO数据集验证的目标检测算法天梯排行榜 AP50 Rank Model box AP AP50 Paper Code Result Year Tags 1 SwinV2-G (HTC++) 6 ...
- The Brain as a Universal Learning Machine
The Brain as a Universal Learning Machine This article presents an emerging architectural hypothesis ...
- Classifying plankton with deep neural networks
Classifying plankton with deep neural networks The National Data Science Bowl, a data science compet ...
- ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
https://blog.csdn.net/y80gDg1/article/details/81463731 感谢阅读腾讯AI Lab微信号第34篇文章.当地时间 7 月 10-15 日,第 35 届 ...
随机推荐
- 什么是 spring 的内部 bean?
只有将 bean 用作另一个 bean 的属性时,才能将 bean 声明为内部 bean. 为了定义 bean,Spring 的基于 XML 的配置元数据在 <property> 或 &l ...
- 利用 ps 怎么显示所有的进程? 怎么利用 ps 查看指定进 程的信息?
ps -ef (system v 输出) ps -aux bsd 格式输出 ps -ef | grep pid
- memcached 和 MySQL 的 query ?
cache 相比,有什么优缺点? 把 memcached 引入应用中,还是需要不少工作量的.MySQL 有个使用方便的 query cache,可以自动地缓存 SQL 查询的结果,被缓存的 SQL 查 ...
- 快如闪电,触控优先。新一代的纯前端控件集 WijmoJS发布新版本了
全球最大的控件提供商葡萄城宣布,新一代纯前端控件 WijmoJS 发布2018 v1 版本,进一步增强产品功能,并支持在 Npm 上的安装和发布,极大的提升了产品的易用性. WijmoJS 是用 Ty ...
- 【Android开发】分割字符串工具类
public class TextUtils { public static String[] results; /** * 分隔符:"." * * @param resource ...
- java——封装
java--封装 java--封装1 封装的理解和好处2 封装的事项实现步骤3 将构造器和setXx结合4 this和super区分 1 封装的理解和好处 隐藏实现细节:[方法(连接数据库)<- ...
- phpstorm配置xdebug 3.0最新教程!!!配置不成功的快看!
前言 之前2月份就开始配置xdebug,始终没有成功. 今天看到一篇写得挺详细的文章,心血来潮又折腾了下,可惜没成功. 验证始终说我配置错误 后面去阅读官方的文档,修改了些配置,居然搞成功了!! ni ...
- Struts2封装获取表单数据方式
一.属性封装 1.创建User实体类` package cn.entity; public class User { private String username; private String p ...
- linux磁盘分区fdisk命令操作(实践)
写这篇的目的,还是要把整个过程完整的记录下来,特别是小细节的地方,通常很多情况是一知半解,平时不实践操作只凭看是没有用的,所以做这个行业就是要多动手,多学习,多思考慢慢你的思路也会打开.练就自己的学习 ...
- DFS与N皇后问题
DFS与N皇后问题 DFS 什么是DFS DFS是指深度优先遍历也叫深度优先搜索. 它是一种用来遍历或搜索树和图数据结构的算法 注:关于树的一些知识可以去看<树的概念及基本术语>这篇文章 ...