论文解读(GGD)《Rethinking and Scaling Up Graph Contrastive Learning: An Extremely Efficient Approach with Group Discrimination》
论文信息
论文标题:Rethinking and Scaling Up Graph Contrastive Learning: An Extremely Efficient Approach with Group Discrimination
论文作者:Yizhen Zheng, Shirui Pan, Vincent Cs Lee, Yu Zheng, Philip S. Yu
论文来源:2022,NeurIPS
论文地址:download
论文代码:download
1 Introduction
GCL 需要大量的 Epoch 在数据集上训练,本文的启发来自 GCL 的代表性工作 DGI 和 MVGRL,因为 Sigmoid 函数存在的缺陷,因此,本文提出 Group Discrimination (GD) ,并基于此提出本文的模型 Graph Group Discrimination (GGD)。
Graph ContrastiveLearning 和 Group Discrimination 的区别:
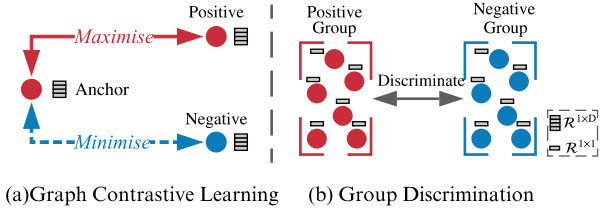
- GD directly discriminates a group of positive nodes from a group of negative nodes.
- GCL maximise the mutual information (MI) between an anchor node and its positive counterparts, sharing similar semantic information while doing the opposite for negative counterparts.
贡献:
- 1) We re-examine existing GCL approaches (e.g., DGI and MVGRL), and we introduce a novel and efficient self-supervised GRL paradigm, namely, Group Discrimination (GD).
- 2) Based on GD, we propose a new self-supervised GRL model, GGD, which is fast in training and convergence, and possess high scalability.
- 3) We conduct extensive experiments on eight datasets, including an extremely large dataset, ogbn-papers100M with billion edges.
2 Rethinking Representative GCL Methods
本节以经典的 DGI 、MVGRL 为例子,说明了互信息最大化并不是对比学习的贡献因素,而是一个新的范式,群体歧视(group discrimination)。
2.1 Rethinking GCL Methods
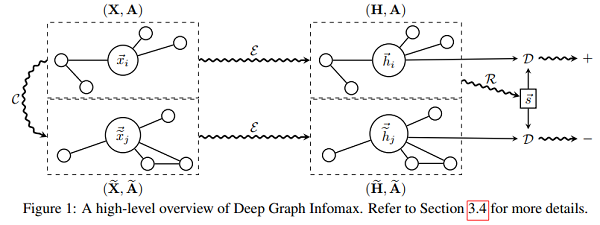
回顾一下 DGI :
代码:


class DGI(nn.Module):
def __init__(self, g, in_feats, n_hidden, n_layers, activation, dropout):
super(DGI, self).__init__()
self.encoder = Encoder(g, in_feats, n_hidden, n_layers, activation, dropout)
self.discriminator = Discriminator(n_hidden)
self.loss = nn.BCEWithLogitsLoss() def forward(self, features):
positive = self.encoder(features, corrupt=False)
negative = self.encoder(features, corrupt=True)
summary = torch.sigmoid(positive.mean(dim=0))
positive = self.discriminator(positive, summary)
negative = self.discriminator(negative, summary)
l1 = self.loss(positive, torch.ones_like(positive))
l2 = self.loss(negative, torch.zeros_like(negative))
return l1 + l2
本文研究 DGI 结论:一个 Sigmoid 函数不适用于权重被 Xavier 初始化的 GNN 生成的 summary vector,且 summary vector 中的元素非常接近于相同的值。
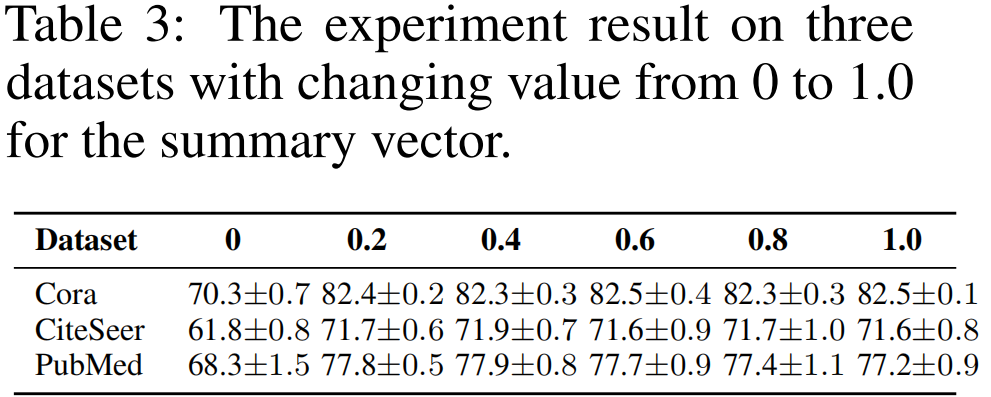
接着尝试将 Summary vector 中的数值变换成不同的常量 (from 0 to 1):
结论:
- 将 summary vector 中的数值变成 0,求解相似度时导致所有的 score 变成 0,也就是 postive 项的损失函数变成 负无穷,无法优化;
- summary vector 设置其他值,导致 数值不稳定;
DGI 的简化:
① 将 summary vector 设置为 单位向量(缩放对损失不影响);
② 去掉 Discriminator (Bilinear :先做线性变换,再求内积相似度)的权重向量;【双线性层的 $W$ 其实就是一个线性变换层】
$\begin{aligned}\mathcal{L}_{D G I} &=\frac{1}{2 N}\left(\sum\limits _{i=1}^{N} \log \mathcal{D}\left(\mathbf{h}_{i}, \mathbf{s}\right)+\log \left(1-\mathcal{D}\left(\tilde{\mathbf{h}}_{i}, \mathbf{s}\right)\right)\right) \\&\left.=\frac{1}{2 N}\left(\sum\limits_{i=1}^{N} \log \left(\mathbf{h}_{i} \cdot \mathbf{s}\right)+\log \left(1-\tilde{\mathbf{h}}_{i} \cdot \mathbf{s}\right)\right)\right) \\&=\frac{1}{2 N}\left(\sum\limits_{i=1}^{N} \log \left(\operatorname{sum}\left(\mathbf{h}_{i}\right)\right)+\log \left(1-\operatorname{sum}\left(\tilde{\mathbf{h}}_{i}\right)\right)\right)\end{aligned} \quad\quad\quad(1)$
Bilinear :
$\mathcal{D}\left(\mathbf{h}_{i}, \mathbf{s}\right)=\sigma_{s i g}\left(\mathbf{h}_{i} \cdot \mathbf{W} \cdot \mathbf{s}\right)\quad\quad\quad(2)$
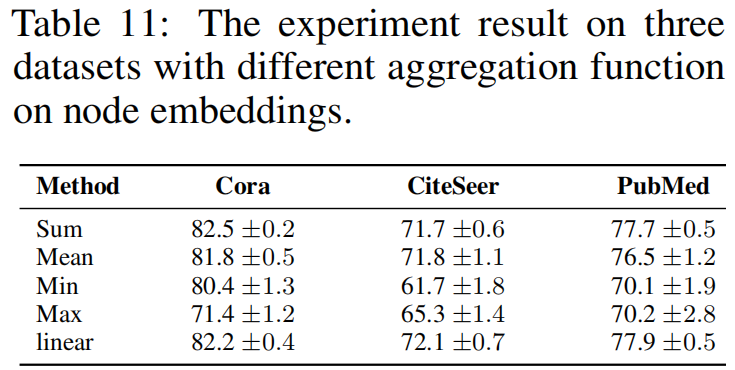
实验:替换 $\text{Eq.1}$ 中的 aggregation function ,即 sum 函数
替换形式为:
$\mathcal{L}_{B C E}=-\frac{1}{2 N}\left(\sum\limits _{i=1}^{2 N} y_{i} \log \hat{y}_{i}+\left(1-y_{i}\right) \log \left(1-\hat{y}_{i}\right)\right)\quad\quad\quad(3)$
其中,$\hat{y}_{i}=\operatorname{agg}\left(\mathbf{h}_{i}\right)$ ,$y_{i} \in \mathbb{R}^{1 \times 1}$ ,$\hat{y}_{i} \in \mathbb{R}^{1 \times 1}$。论文中阐述 $y_{i}$ 和 $\hat{y}_{i}$ 分别代表 node $i$ 是否是 postive sample ,及其预测输出。Q :当 aggregation function 采用 $\text{mean}$ 的时候,对于 postive sample $i$ ,$\hat{y}_{i}$ 值会趋于 $1$ 么?
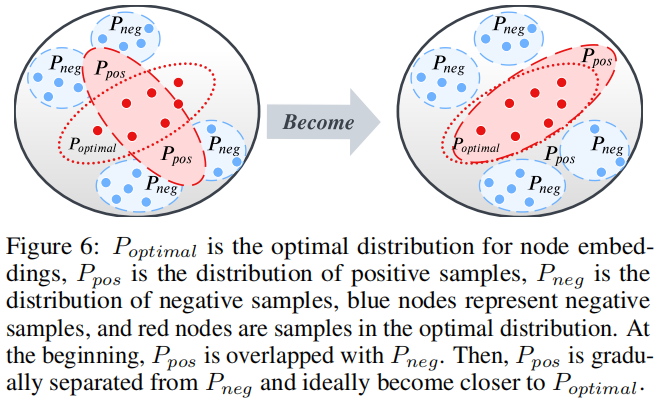
DGI 真正所做的是区分正确拓扑生成的一组节点和损坏拓扑生成的节点,如 Figure 1 所示。可以这么理解,DGI 是使用一个固定的向量 $s$ 去区分两组节点嵌入矩阵(postive and negative)。
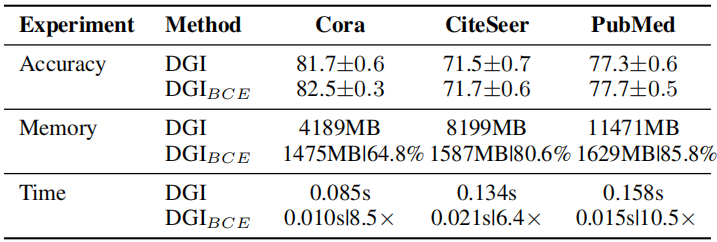
Note:方差大的稍微大一点的 method ,就是容易被诋毁。
3 Methodology
整体框架:
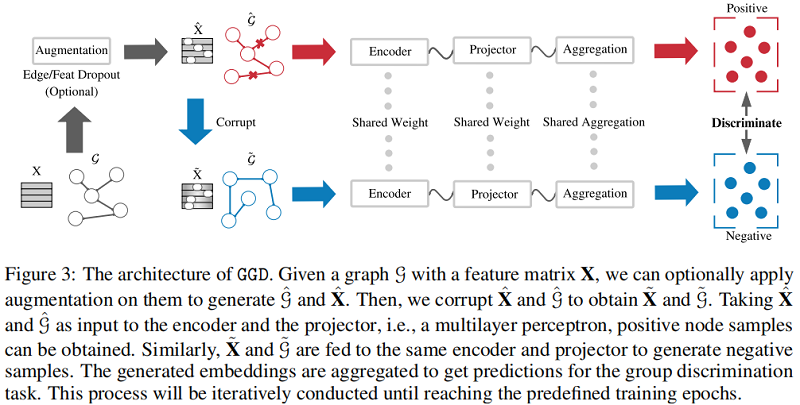
组成部分:
- Siamese Network :模仿 MVGRL 的架构;
- Data Augmentation :提供相似意义信息,带来的是时间成本;【dropout edge、feature mask】
- Loss function : $\text{Eq.3}$;
首先:固定 GNN encoder、MLP predict 的参数,获得初步的节点表示 $\mathbf{H}_{\theta}$;
其次:MVGRL 多视图对比工作给本文深刻的启发,所以考虑引入全局信息 :$ \mathbf{H}_{\theta}^{\text {global }}=\mathbf{A}^{n} \mathbf{H}_{\theta}$;
最后:得到局部表示和全局表示的聚合 $\mathbf{H}=\mathbf{H}_{\theta}^{\text {global }}+\mathbf{H}_{\theta}$ ;
4 Experiments
4.1 Datasets
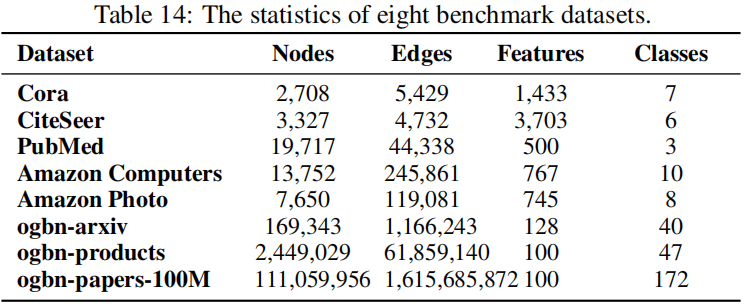
4.2 Result
节点分类
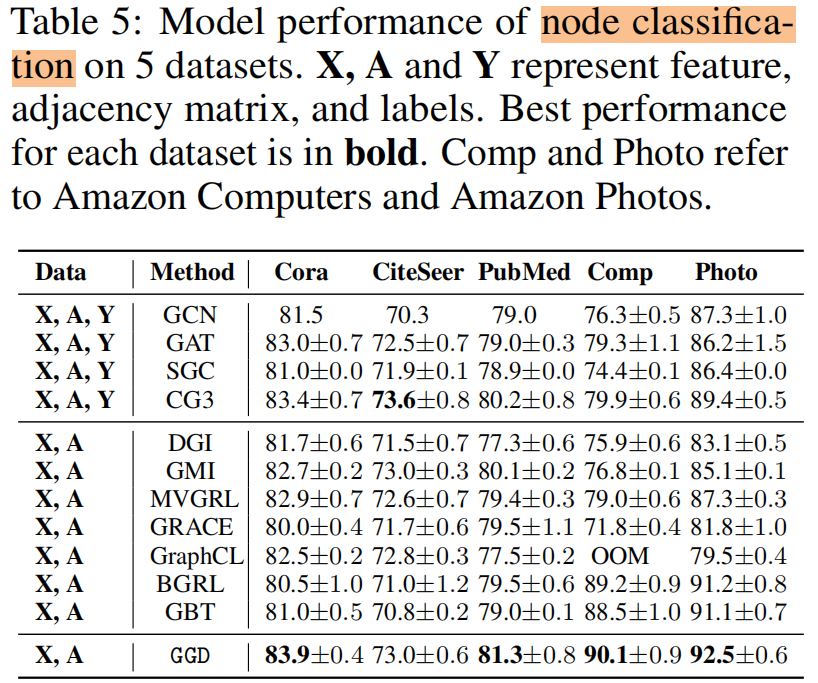
训练时间 和 内存消耗

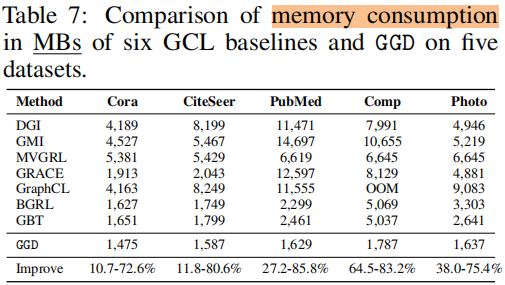
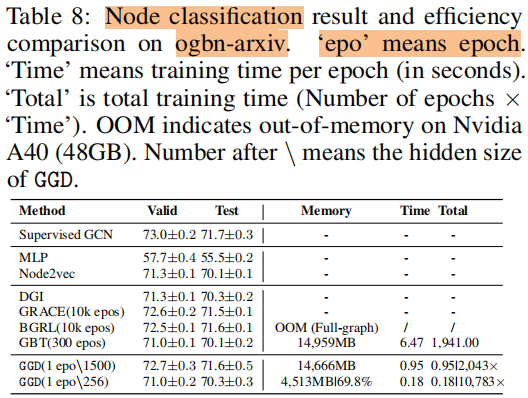
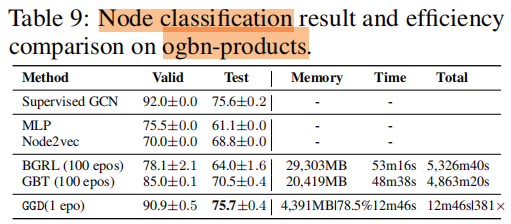

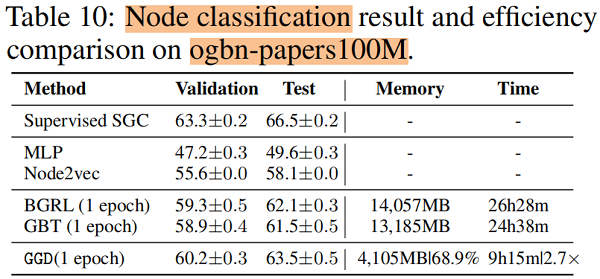
5 Future Work
For example, can we extend the current binary Group Discrimination scheme (i.e., classifying nodes generated with different topology) to discrimination among multiple groups?
论文解读(GGD)《Rethinking and Scaling Up Graph Contrastive Learning: An Extremely Efficient Approach with Group Discrimination》的更多相关文章
- 论文解读(MLGCL)《Multi-Level Graph Contrastive Learning》
论文信息 论文标题:Structural and Semantic Contrastive Learning for Self-supervised Node Representation Learn ...
- 论文解读(GRACE)《Deep Graph Contrastive Representation Learning》
Paper Information 论文标题:Deep Graph Contrastive Representation Learning论文作者:Yanqiao Zhu, Yichen Xu, Fe ...
- 论文解读(GCC)《GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training》
论文信息 论文标题:GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training论文作者:Jiezhong Qiu, Qibi ...
- 论文解读(GCA)《Graph Contrastive Learning with Adaptive Augmentation》
论文信息 论文标题:Graph Contrastive Learning with Adaptive Augmentation论文作者:Yanqiao Zhu.Yichen Xu3.Feng Yu4. ...
- 论文解读(GROC)《Towards Robust Graph Contrastive Learning》
论文信息 论文标题:Towards Robust Graph Contrastive Learning论文作者:Nikola Jovanović, Zhao Meng, Lukas Faber, Ro ...
- 论文解读(SimGRACE)《SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation》
论文信息 论文标题:SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation论文作者: ...
- 论文解读(AGC)《Attributed Graph Clustering via Adaptive Graph Convolution》
论文信息 论文标题:Attributed Graph Clustering via Adaptive Graph Convolution论文作者:Xiaotong Zhang, Han Liu, Qi ...
- 论文解读(SelfGNN)《Self-supervised Graph Neural Networks without explicit negative sampling》
论文信息 论文标题:Self-supervised Graph Neural Networks without explicit negative sampling论文作者:Zekarias T. K ...
- 论文解读《Momentum Contrast for Unsupervised Visual Representation Learning》俗称 MoCo
论文题目:<Momentum Contrast for Unsupervised Visual Representation Learning> 论文作者: Kaiming He.Haoq ...
随机推荐
- 从零开始Blazor Server(5)--权限验证
序 之前我们一直使用的是微软自带的身份验证方式,即使用[Authorize]标签来做. 但是这种方式十分不灵活,微软推荐的方式是加Policy,但是这种方式对我们来说还是不够灵活. 所以本节我们用完全 ...
- 从零开始Blazor Server(6)--基于策略的权限验证
写这个的原因 现在BootstrapBlazor处于大更新时期,Menu组件要改为泛型模式. 本来我们的这一篇应该是把Layout改了,但是改Layout肯定要涉及到菜单,如果现在写了呢,就进入一个发 ...
- pat甲级考试+pat1051+1056
同上一篇博客: 贪心题目我已经刷了将近30道了,由于那几天考驾照就没写,以后有空的时候补过来吧,都在codeblock里 pat的题也刷了点,acwing 的题也刷了点,基本都攒下了.以后也会慢慢补过 ...
- 技术分享 | MySQL数据误删除的总结
欢迎来到 GreatSQL社区分享的MySQL技术文章,如有疑问或想学习的内容,可以在下方评论区留言,看到后会进行解答 内容提要 用delete语句 使用drop.truncate删除表以及drop删 ...
- 数据库运维之路——关于tempdb暴增实战案例
转眼间,2021年的第一个季度已经到了最后一个月了,由于疫情原因,最近一段时间一直在北京,基本上没有出差,每天上班下班的日子感觉时间过的好快,新的一年继续努力奋斗啊. 仔细回想一下,自己踏入到sql ...
- mysql存储过程的创建和调用
描述:存储过程就是具有名字的一段代码,用来完成一个特定的功能.创建的存储过程保存在数据库的数据词典中. --创建一个名为GreetWorld的存储过程,拼接两个值 CREATE PROCEDURE G ...
- 一次客户需求引发的K8S网络探究
前言 在本次案例中,我们的中台技术工程师遇到了来自客户提出的打破k8s产品功能限制的特殊需求,面对这个极具挑战的任务,攻城狮最终是否克服了重重困难,帮助客户完美实现了需求?且看本期K8S技术案例分享! ...
- Little Girl and Problem on Trees
题意 给定一棵无边权的树,最多只有一个点度数超过2,有两种操作 1)(0 u x d)将距离u节点d距离之内的节点的值加上x 2)(1 u)询问u节点的值 n<=100000,q<=100 ...
- 记一次血淋淋的MySQL崩溃修复案例
摘要:今天给大家带来一篇MySQL数据库崩溃的修复案例 本文分享自华为云社区<记一次MySQL崩溃修复案例,再也不用删库跑路了>,作者: 冰 河. 问题描述 研究MySQL源代码,调试并压 ...
- KingbaseES V8R6 维护管理案例之---Kstudio在CentOS 7启动故障
案例说明: 在CentOS 7上安装KingbaseES V8R6C006数据库后,启动Kstudio图形界面启动失败,gtk动态库加载失败,安装gtk相关动态库后,问题解决. 适用版本: Kin ...