论文解读(GGD)《Rethinking and Scaling Up Graph Contrastive Learning: An Extremely Efficient Approach with Group Discrimination》
论文信息
论文标题:Rethinking and Scaling Up Graph Contrastive Learning: An Extremely Efficient Approach with Group Discrimination
论文作者:Yizhen Zheng, Shirui Pan, Vincent Cs Lee, Yu Zheng, Philip S. Yu
论文来源:2022,NeurIPS
论文地址:download
论文代码:download
1 Introduction
GCL 需要大量的 Epoch 在数据集上训练,本文的启发来自 GCL 的代表性工作 DGI 和 MVGRL,因为 Sigmoid 函数存在的缺陷,因此,本文提出 Group Discrimination (GD) ,并基于此提出本文的模型 Graph Group Discrimination (GGD)。
Graph ContrastiveLearning 和 Group Discrimination 的区别:
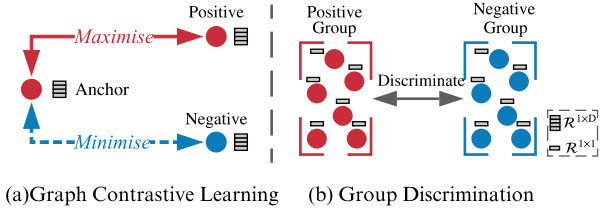
- GD directly discriminates a group of positive nodes from a group of negative nodes.
- GCL maximise the mutual information (MI) between an anchor node and its positive counterparts, sharing similar semantic information while doing the opposite for negative counterparts.
贡献:
- 1) We re-examine existing GCL approaches (e.g., DGI and MVGRL), and we introduce a novel and efficient self-supervised GRL paradigm, namely, Group Discrimination (GD).
- 2) Based on GD, we propose a new self-supervised GRL model, GGD, which is fast in training and convergence, and possess high scalability.
- 3) We conduct extensive experiments on eight datasets, including an extremely large dataset, ogbn-papers100M with billion edges.
2 Rethinking Representative GCL Methods
本节以经典的 DGI 、MVGRL 为例子,说明了互信息最大化并不是对比学习的贡献因素,而是一个新的范式,群体歧视(group discrimination)。
2.1 Rethinking GCL Methods
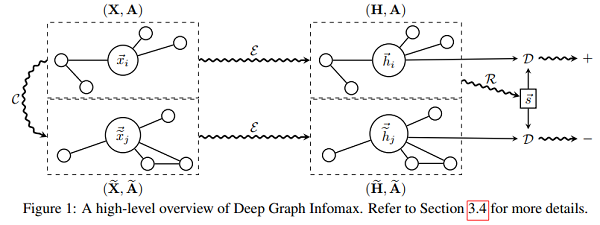
回顾一下 DGI :
代码:


class DGI(nn.Module):
def __init__(self, g, in_feats, n_hidden, n_layers, activation, dropout):
super(DGI, self).__init__()
self.encoder = Encoder(g, in_feats, n_hidden, n_layers, activation, dropout)
self.discriminator = Discriminator(n_hidden)
self.loss = nn.BCEWithLogitsLoss() def forward(self, features):
positive = self.encoder(features, corrupt=False)
negative = self.encoder(features, corrupt=True)
summary = torch.sigmoid(positive.mean(dim=0))
positive = self.discriminator(positive, summary)
negative = self.discriminator(negative, summary)
l1 = self.loss(positive, torch.ones_like(positive))
l2 = self.loss(negative, torch.zeros_like(negative))
return l1 + l2
本文研究 DGI 结论:一个 Sigmoid 函数不适用于权重被 Xavier 初始化的 GNN 生成的 summary vector,且 summary vector 中的元素非常接近于相同的值。
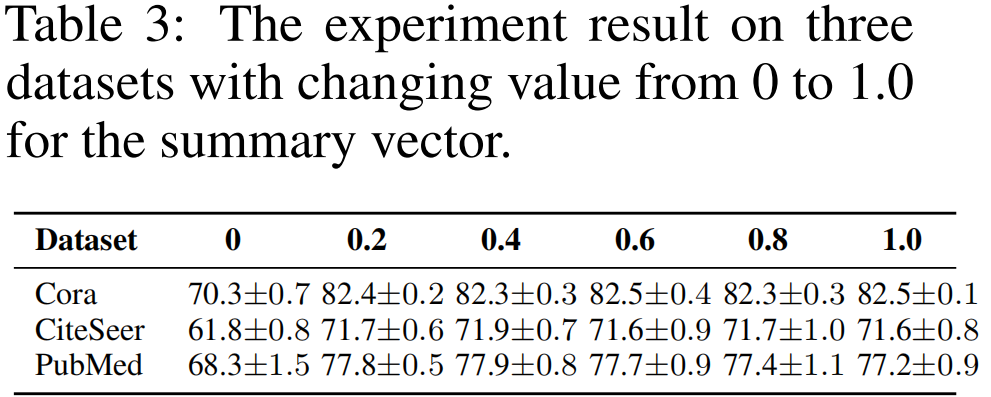
接着尝试将 Summary vector 中的数值变换成不同的常量 (from 0 to 1):
结论:
- 将 summary vector 中的数值变成 0,求解相似度时导致所有的 score 变成 0,也就是 postive 项的损失函数变成 负无穷,无法优化;
- summary vector 设置其他值,导致 数值不稳定;
DGI 的简化:
① 将 summary vector 设置为 单位向量(缩放对损失不影响);
② 去掉 Discriminator (Bilinear :先做线性变换,再求内积相似度)的权重向量;【双线性层的 $W$ 其实就是一个线性变换层】
$\begin{aligned}\mathcal{L}_{D G I} &=\frac{1}{2 N}\left(\sum\limits _{i=1}^{N} \log \mathcal{D}\left(\mathbf{h}_{i}, \mathbf{s}\right)+\log \left(1-\mathcal{D}\left(\tilde{\mathbf{h}}_{i}, \mathbf{s}\right)\right)\right) \\&\left.=\frac{1}{2 N}\left(\sum\limits_{i=1}^{N} \log \left(\mathbf{h}_{i} \cdot \mathbf{s}\right)+\log \left(1-\tilde{\mathbf{h}}_{i} \cdot \mathbf{s}\right)\right)\right) \\&=\frac{1}{2 N}\left(\sum\limits_{i=1}^{N} \log \left(\operatorname{sum}\left(\mathbf{h}_{i}\right)\right)+\log \left(1-\operatorname{sum}\left(\tilde{\mathbf{h}}_{i}\right)\right)\right)\end{aligned} \quad\quad\quad(1)$
Bilinear :
$\mathcal{D}\left(\mathbf{h}_{i}, \mathbf{s}\right)=\sigma_{s i g}\left(\mathbf{h}_{i} \cdot \mathbf{W} \cdot \mathbf{s}\right)\quad\quad\quad(2)$
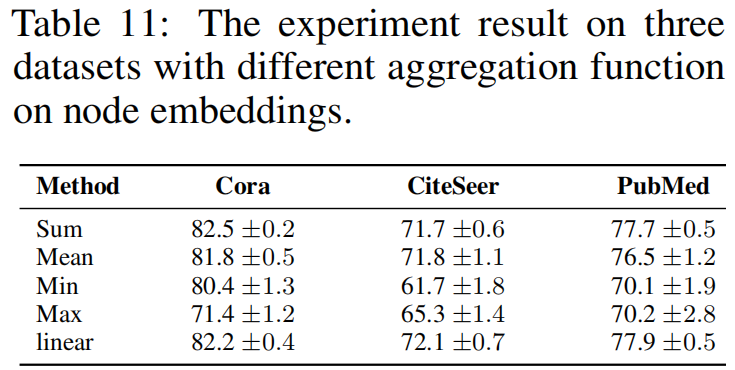
实验:替换 $\text{Eq.1}$ 中的 aggregation function ,即 sum 函数
替换形式为:
$\mathcal{L}_{B C E}=-\frac{1}{2 N}\left(\sum\limits _{i=1}^{2 N} y_{i} \log \hat{y}_{i}+\left(1-y_{i}\right) \log \left(1-\hat{y}_{i}\right)\right)\quad\quad\quad(3)$
其中,$\hat{y}_{i}=\operatorname{agg}\left(\mathbf{h}_{i}\right)$ ,$y_{i} \in \mathbb{R}^{1 \times 1}$ ,$\hat{y}_{i} \in \mathbb{R}^{1 \times 1}$。论文中阐述 $y_{i}$ 和 $\hat{y}_{i}$ 分别代表 node $i$ 是否是 postive sample ,及其预测输出。Q :当 aggregation function 采用 $\text{mean}$ 的时候,对于 postive sample $i$ ,$\hat{y}_{i}$ 值会趋于 $1$ 么?
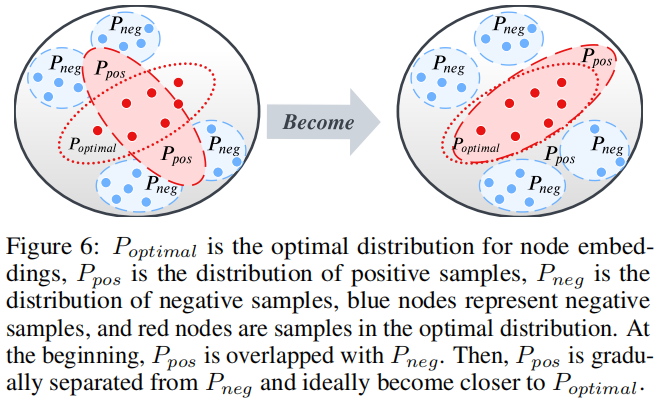
DGI 真正所做的是区分正确拓扑生成的一组节点和损坏拓扑生成的节点,如 Figure 1 所示。可以这么理解,DGI 是使用一个固定的向量 $s$ 去区分两组节点嵌入矩阵(postive and negative)。
Note:方差大的稍微大一点的 method ,就是容易被诋毁。
3 Methodology
整体框架:
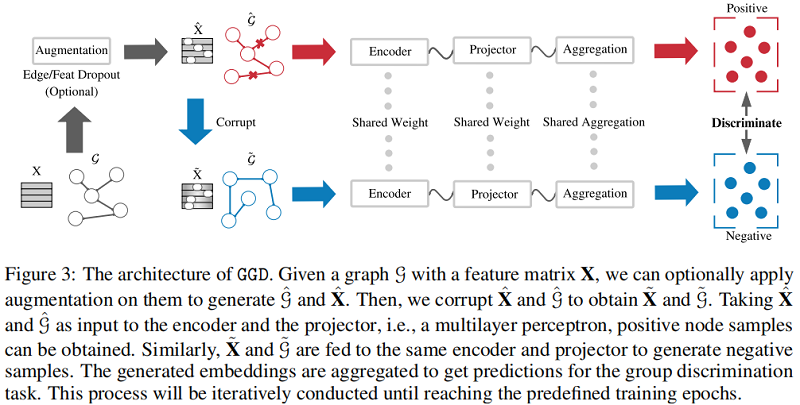
组成部分:
- Siamese Network :模仿 MVGRL 的架构;
- Data Augmentation :提供相似意义信息,带来的是时间成本;【dropout edge、feature mask】
- Loss function : $\text{Eq.3}$;
首先:固定 GNN encoder、MLP predict 的参数,获得初步的节点表示 $\mathbf{H}_{\theta}$;
其次:MVGRL 多视图对比工作给本文深刻的启发,所以考虑引入全局信息 :$ \mathbf{H}_{\theta}^{\text {global }}=\mathbf{A}^{n} \mathbf{H}_{\theta}$;
最后:得到局部表示和全局表示的聚合 $\mathbf{H}=\mathbf{H}_{\theta}^{\text {global }}+\mathbf{H}_{\theta}$ ;
4 Experiments
4.1 Datasets
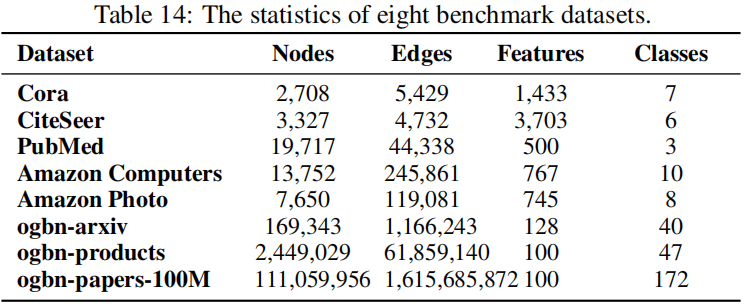
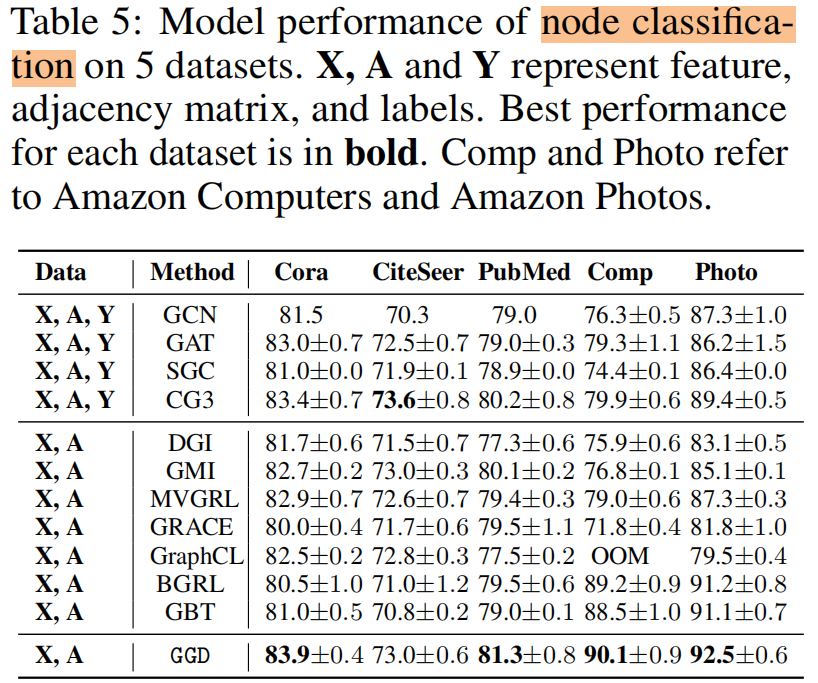
4.2 Result
节点分类
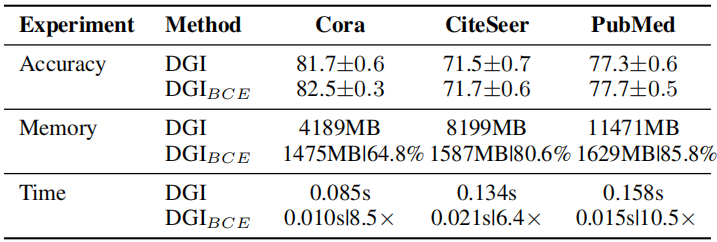
训练时间 和 内存消耗

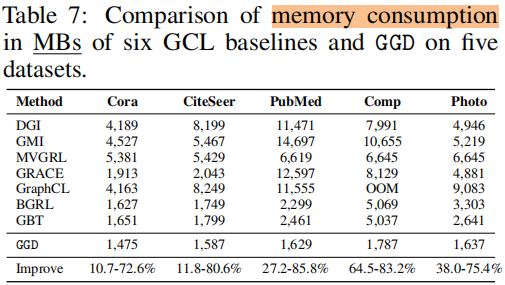
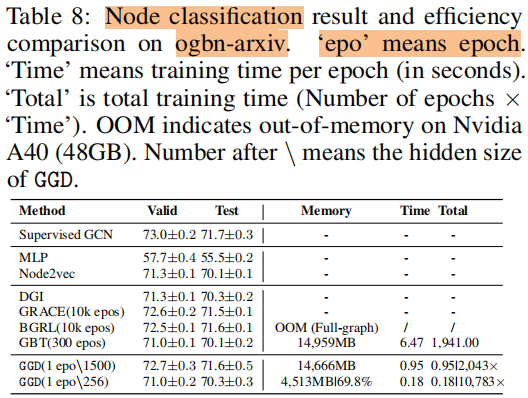
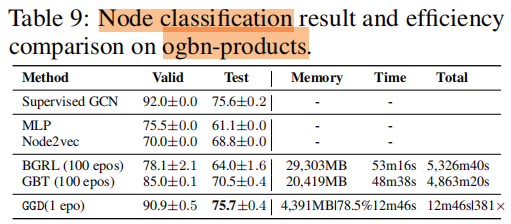

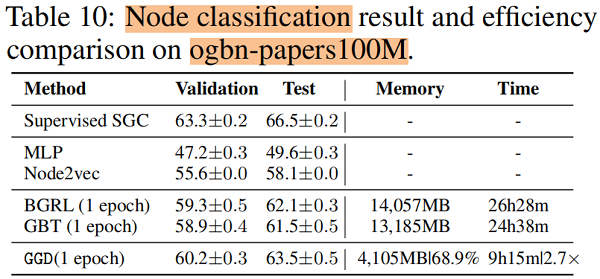
5 Future Work
For example, can we extend the current binary Group Discrimination scheme (i.e., classifying nodes generated with different topology) to discrimination among multiple groups?
论文解读(GGD)《Rethinking and Scaling Up Graph Contrastive Learning: An Extremely Efficient Approach with Group Discrimination》的更多相关文章
- 论文解读(MLGCL)《Multi-Level Graph Contrastive Learning》
论文信息 论文标题:Structural and Semantic Contrastive Learning for Self-supervised Node Representation Learn ...
- 论文解读(GRACE)《Deep Graph Contrastive Representation Learning》
Paper Information 论文标题:Deep Graph Contrastive Representation Learning论文作者:Yanqiao Zhu, Yichen Xu, Fe ...
- 论文解读(GCC)《GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training》
论文信息 论文标题:GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training论文作者:Jiezhong Qiu, Qibi ...
- 论文解读(GCA)《Graph Contrastive Learning with Adaptive Augmentation》
论文信息 论文标题:Graph Contrastive Learning with Adaptive Augmentation论文作者:Yanqiao Zhu.Yichen Xu3.Feng Yu4. ...
- 论文解读(GROC)《Towards Robust Graph Contrastive Learning》
论文信息 论文标题:Towards Robust Graph Contrastive Learning论文作者:Nikola Jovanović, Zhao Meng, Lukas Faber, Ro ...
- 论文解读(SimGRACE)《SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation》
论文信息 论文标题:SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation论文作者: ...
- 论文解读(AGC)《Attributed Graph Clustering via Adaptive Graph Convolution》
论文信息 论文标题:Attributed Graph Clustering via Adaptive Graph Convolution论文作者:Xiaotong Zhang, Han Liu, Qi ...
- 论文解读(SelfGNN)《Self-supervised Graph Neural Networks without explicit negative sampling》
论文信息 论文标题:Self-supervised Graph Neural Networks without explicit negative sampling论文作者:Zekarias T. K ...
- 论文解读《Momentum Contrast for Unsupervised Visual Representation Learning》俗称 MoCo
论文题目:<Momentum Contrast for Unsupervised Visual Representation Learning> 论文作者: Kaiming He.Haoq ...
随机推荐
- 最近公共祖先(LCA)学习笔记 | P3379 【模板】最近公共祖先(LCA)题解
研究了LCA,写篇笔记记录一下. 讲解使用例题 P3379 [模板]最近公共祖先(LCA). 什么是LCA 最近公共祖先简称 LCA(Lowest Common Ancestor).两个节点的最近公共 ...
- BTDetect用户手册和技术支持
BTDetect用户手册和技术支持 1. 程序主要功能 BTDetect是BT(BioTechnology) Detect 生物科技检测的缩写.本程序将根据用户的回答推断其两大基因类型.以及具体的小分 ...
- 成为 Apache 贡献者,So easy!
点击上方蓝字关注 Apache DolphinScheduler Apache DolphinScheduler(incubating),简称"DS", 中文名 "海豚调 ...
- BZOJ3732 (Kruskal重构树)
Kruskal重构树上\(x\)和\(v\)的\(lca\)的权值即为它们最长路最小值 #include <cstdio> #include <iostream> #inclu ...
- LuoguP3377 左偏树 (左偏树)
TLE but corrct in most cases. inline int Find(int x){ //be careful with the way used for finding you ...
- Spring源码 03 IOC原理
参考源 https://www.bilibili.com/video/BV1tR4y1F75R?spm_id_from=333.337.search-card.all.click https://ww ...
- 使用dotnet-monitor分析在Kubernetes的应用程序:Sidecar模式
dotnet-monitor可以在Kubernetes中作为Sidecar运行,Sidecar是一个容器,它与应用程序在同一个Pod中运行,利用Sidecar模式使我们可以诊断及监控应用程序. 如下图 ...
- Python自学教程2:大牛们怎么写注释
在还没开始学代码前,就要先学会写注释.不会写注释的程序员会遭到鄙视和唾弃,甚至在工作中会被人穿小鞋.注释也不是随便写一下就行,用好注释还是有点讲究的. 注释有什么用? 注释(Comments)主要是向 ...
- CSP-S 2020 T4 贪吃蛇 (双队列模拟)
题面 题解 先看数据,T<=10,用平衡树或优先队列是可以拿70分的,大体思路和正解思路是一样的,每次直接修改,然后模拟. 我们模拟的时候,主要是在过程中算出最终被吃的有选择权的蛇的最后选择时刻 ...
- 【Swift】从零开始的Swift语言学习笔记-1:前言&Hello World
该系列分为两个大的部分. Swift基本语法 使用Xcode编写iOS应用程式 两个部分会双线并行更新. 本人的学习资料大多为Apple Develop官方上的生肉,难免会有疏漏,望斧正. 另外该系列 ...