SpringCloud Sleuth链路追踪
1、概要
一般的,一个分布式服务跟踪系统,主要有三部分:
- 数据收集
- 数据存储
- 数据展示
然而这三个部分其实不都是由SpringCloud Sleuth(下面我简称为Sleuth)完成的,Sleuth负责数据的收集,而数据的存储和数据的展示由Zipkin完成
首先我们需要搞清楚,链路追踪功能由Sleuth(数据收集),Zipkin(数据存储、数据展示)这两个组件组合完成的。
下面我们对它们分别介绍
2、Sleuth
①产生原因
在微服务框架中,一个客户端的请求在后端系统中会经过多个不同的服务节点调用来协同产生最后的请求结果,每一个前端请求都会产生一个复杂的服务调用链路,链路中的任何一环出现高延迟或错误都会导致请求的失败
Springcloud考虑到这个问题,Sleuth即为长链路调用的链路跟踪监控组件
②简介
SpringCloud Sleuth官网:Spring Cloud Sleuth
这是SpringCloud Sleuth的概念图:
trace:一次完整的请求,从服务开始到执行完成
span:在一次trace中,每调用一个服务就会记录调用的信息和响应时间,这就是一个span
下图中,Trace全为X表示一次调用,其中每个服务调用都有一个span,不同服务调用span不同。
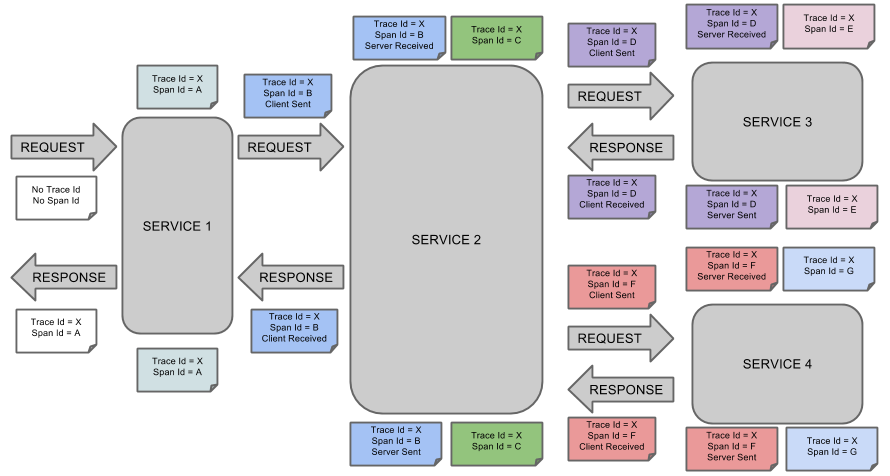
可见sleuth能够通过trace和span,追踪到一次调用经过了哪些服务,每个服务的耗费时间
3、Zipkin
①简介
Zipkin是一个开源的追踪系统,它负责收集,存储数据并展示给用户
这里说Zipkin的收集不同于Sleuth的收集,Sleuth是通过监控来实现信息的收集,而Zipkin的收集是将Sleuth采集的数据进行接收。
官网也表达的很清楚:
本文中,Sleuth负责数据的收集,Zipkin负责存储和展示
Zipkin提供了不同的数据存储方式:
- Merory(内存存储)
- Mysql(关系型数据库)
- Cassandra(非关系型数据库ps本人还没有接触过)
- Elasticsearch
4、搭建
①安装zipkin
下载地址:
运行:
java -jar zipkin-server-2.12.9-exec.jar
进入控制台:
http://localhost:9411/zipkin/
②Provider
在之前的工程cloud-provider-payment8001上进行修改
添加依赖:
<!--包含了sleuth+zipkin-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
添加配置:
spring:
zipkin:
base-url: http://localhost:9411 #zipkin Server的地址
sleuth:
sampler:
probability: 1 #采样率值介于0到1之间,1则表示全部采集(一般不为1,不然高并发性能会有影响)
在Controller中添加方法:
@GetMapping("/payment/zipkin")
public String paymentZipkin(){
return "paymentZipkin...";
}
③Consumer
在之前的工程cloud-consumer-order80(服务消费者)上进行更改
添加依赖:
<!--包含了sleuth+zipkin-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
添加配置:
spring:
zipkin:
base-url: http://localhost:9411 #zipkin Server的地址
sleuth:
sampler:
probability: 1 #采样率值介于0到1之间,1则表示全部采集(一般不为1,不然高并发性能会有影响)
在Controller中添加方法:
@GetMapping("/consumer/payment/zipkin")
public String paymentZipkin(){
String result = restTemplate.getForObject("http://localhost:8001" + "/payment/zipkin", String.class);
return result;
}
④测试
前面已经启动了zipkin Server了
启动Eureka注册中心7001,Order80,Payment8001
调用Order接口,Order接口调用了Payment的接口:
http://localhost/consumer/payment/zipkin
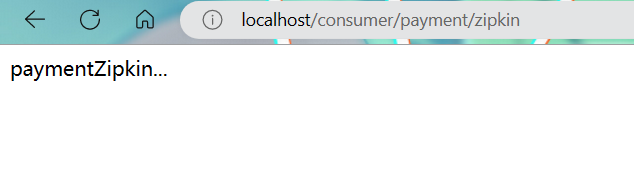
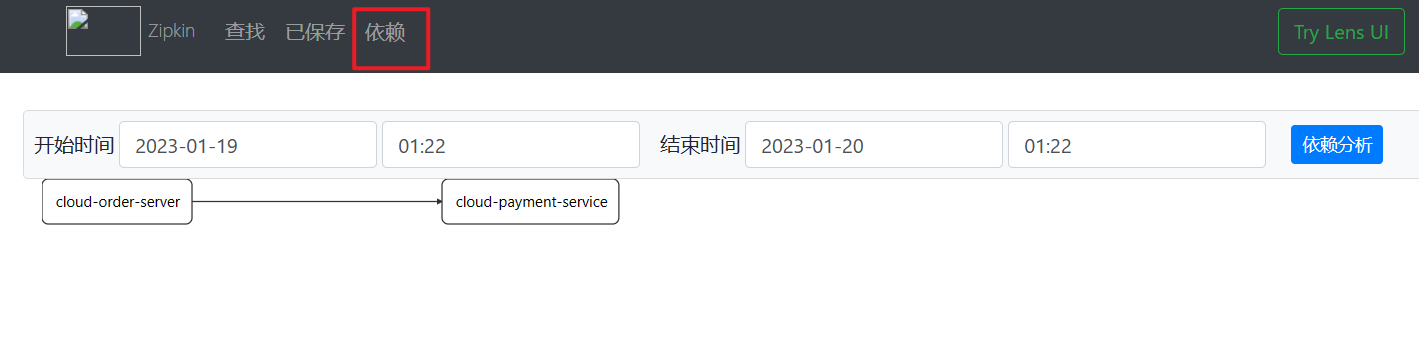
进入Zipkin面板查看:
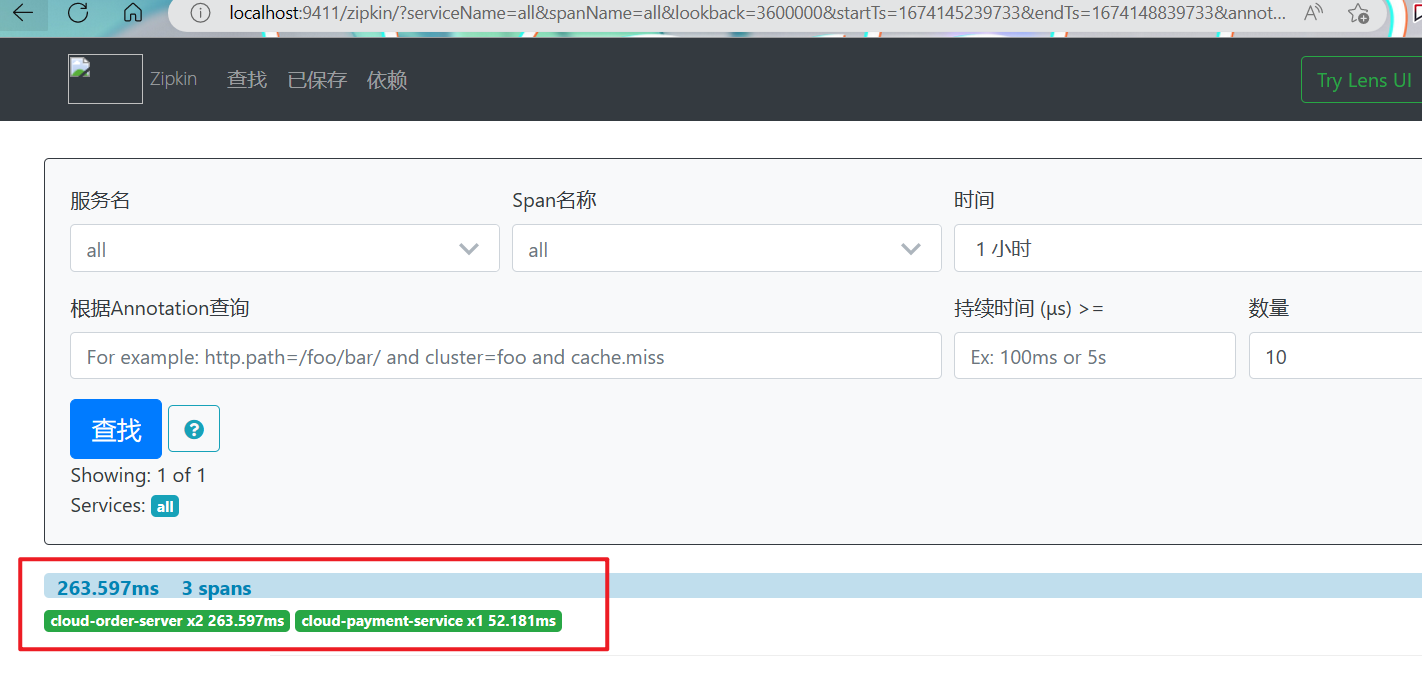
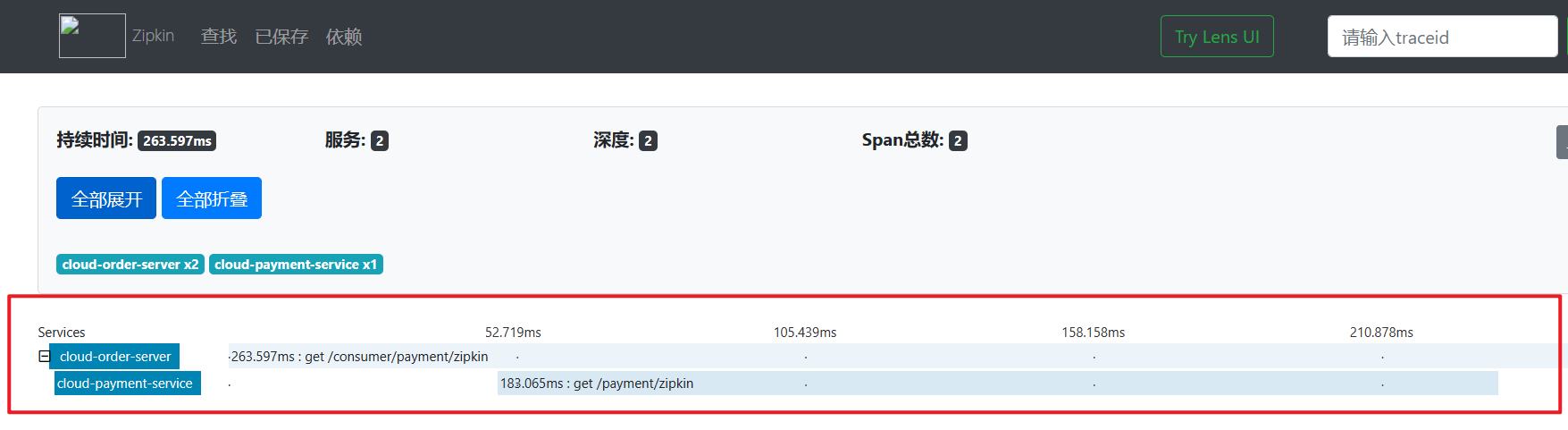
查看服务依赖:
SpringCloud Sleuth链路追踪的更多相关文章
- Spring Cloud 系列之 Sleuth 链路追踪(二)
本篇文章为系列文章,未读第一集的同学请猛戳这里:Spring Cloud 系列之 Sleuth 链路追踪(一) 本篇文章讲解 Sleuth 基于 Zipkin 存储链路追踪数据至 MySQL,Elas ...
- Spring Cloud 系列之 Sleuth 链路追踪(三)
本篇文章为系列文章,未读前几集的同学请猛戳这里: Spring Cloud 系列之 Sleuth 链路追踪(一) Spring Cloud 系列之 Sleuth 链路追踪(二) 本篇文章讲解 Sleu ...
- Spring-Cloud之Sleuth链路追踪-8
一.Spring Cloud Sleuth 是Spring Cloud 的一个组件,它的主要功能是在分布式系统中提供服务链路追踪的解决方案. 二.为什么需要Spring Cloud Sleuth? 微 ...
- SpringCloud之链路追踪整合Sleuth(十三)
前言 SpringCloud 是微服务中的翘楚,最佳的落地方案. 在一个完整的微服务架构项目中,服务之间的调用是很复杂的,当其中某一个服务出现了问题或者访问超时,很 难直接确定是由哪个服务引起的,所以 ...
- SpringCloud(七)之SpringCloud的链路追踪组件Sleuth实战,以及 zipkin 的部署和使用
一.前言 Spring Cloud Sleuth 主要功能就是在分布式系统中提供追踪解决方案 ,并且兼容了zipkin,提供了REST API接口来辅助我们查询跟踪数据以实现对分布式系统的监控程序 . ...
- Zipkin+Sleuth 链路追踪整合
1.Zipkin 是一个开放源代码分布式的跟踪系统 它可以帮助收集服务的时间数据,以解决微服务架构中的延迟问题,包括数据的收集.存储.查找和展现 每个服务向zipkin报告计时数据,zipkin会根据 ...
- Spring Cloud 系列之 Sleuth 链路追踪(一)
随着微服务架构的流行,服务按照不同的维度进行拆分,一次请求往往需要涉及到多个服务.互联网应用构建在不同的软件模块集上,这些软件模块,有可能是由不同的团队开发.可能使用不同的编程语言来实现.有可能布在了 ...
- 十一、springcloud之链路追踪Sleuth
一.背景 随着微服务的数量增长,一个业务接口涉及到多个微服务的交互,在出错的情况下怎么能够快速的定位错误 二.简介 Spring Cloud Sleuth 主要功能就是在分布式系统中提供追踪解决方案, ...
- 学习一下 SpringCloud (五)-- 配置中心 Config、消息总线 Bus、链路追踪 Sleuth、配置中心 Nacos
(1) 相关博文地址: 学习一下 SpringCloud (一)-- 从单体架构到微服务架构.代码拆分(maven 聚合): https://www.cnblogs.com/l-y-h/p/14105 ...
- 分布式链路追踪系统Sleuth和ZipKin
1.微服务下的链路追踪讲解和重要性 简介:讲解什么是分布式链路追踪系统,及使用好处 进行日志埋点,各微服务追踪. 2.SpringCloud的链路追踪组件Sleuth 1.官方文档 http://cl ...
随机推荐
- [linux]非root账户 sudo cd 无法切换目录解决办法
在Centos上有个账户A(非root),有sudo权限(权限比较大),想要用 cd 命令切换到 B账号的 /home/B 下的目录,结果没作用 [liuzz ~]$ sudo cd /home/xi ...
- gdb不能使用mac
先说问题:1.gdb不能使用,重新用homebrew install 了gdb 2.brew装的gdb可以用了,但是等start调试的时候报这些错误: dyld: Library not ...
- Linux *.service文件详解
什么是systemd service? systemd service是一种以.service 结尾的配置文件,是一个专用于Linux操作系统的系统与服务管理器.简单来说,用于后台以守护精灵(daem ...
- ArrayList中的ConcurrentModificationException,并发修改异常,fail-fast机制。
一:什么时候出现? 当我们用迭代器循环list的时候,在其中用list的方法新增/删除元素,就会出现这个错误. package com.sinitek.aml; import java.util.Ar ...
- 14 STL-常用算法
重新系统学习c++语言,并将学习过程中的知识在这里抄录.总结.沉淀.同时希望对刷到的朋友有所帮助,一起加油哦! 每一次学习都是为了追求智慧! 写在前面,本篇章主要介绍STL中常用算法. 算法主要由 ...
- python读入中文文本编码错误
python读入中文文本编码错误 python读入中文txt文本: #coding:utf-8 def readFile(): fp = open('emotion_dict//neg//neg_al ...
- RFN-Nest_ An end-to-end residual fusion network for infrared and visible images 论文解读
RFN-Nest 2021 研究 图像融合分为三步:特征提取,融合策略,图像重建. 当前端到端的图像融合方法:基于GAN的.还有本文提出的 研究背景:当前设计的融合策略在为特定任务生成融合图像方面是比 ...
- 秒级查询之开源分布式SQL查询引擎Presto实操-上
@ 目录 概述 定义 概念 架构 优缺点 连接器 部署 集群安装 常用配置说明 资源管理安装模式 安装命令行界面 基于Tableau Web 连接器 使用优化 数据存储 查询SQL优化 无缝替换Hiv ...
- django中如何开启事务
一:django中如何开启事务 1.事务的四大特征 ACID A: 原子性 每个事务都是不可分割的最小单位(同一个事物内的多个操作要么同时成功要么同时失败) C: 一致性 事物必须是使数据库从一个一致 ...
- VSCode编辑器极简使用入门
VSCode(Visual Studio Code)是一款开源.跨平台.轻量级的代码编辑器,具有非常丰富的插件生态.他本身就是JavaScript + Electron ( /ɪˈlektrɒn/电子 ...