王树森Transformer学习笔记
Transformer
Transformer是完全由Attention和Self-Attention结构搭建的深度神经网络结构。
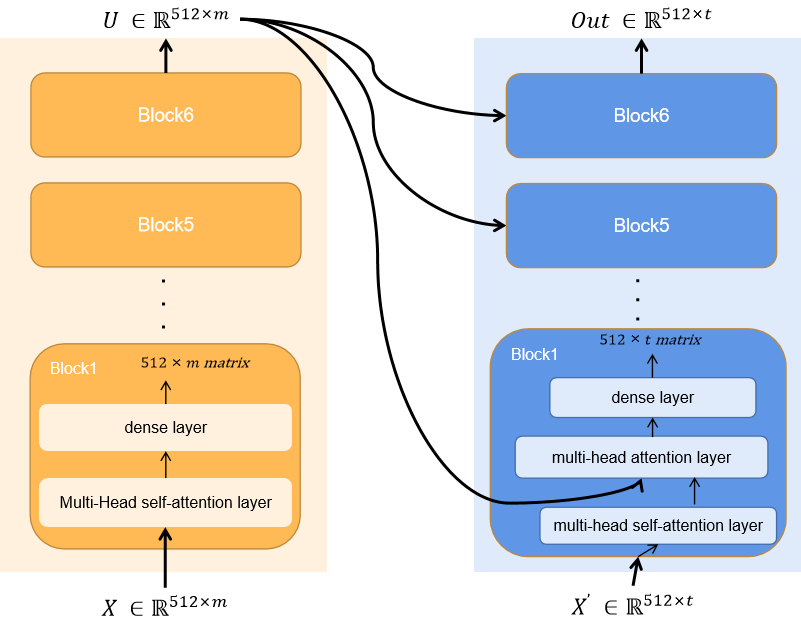
其中最为重要的就是Attention和Self-Attention结构。
Attention结构
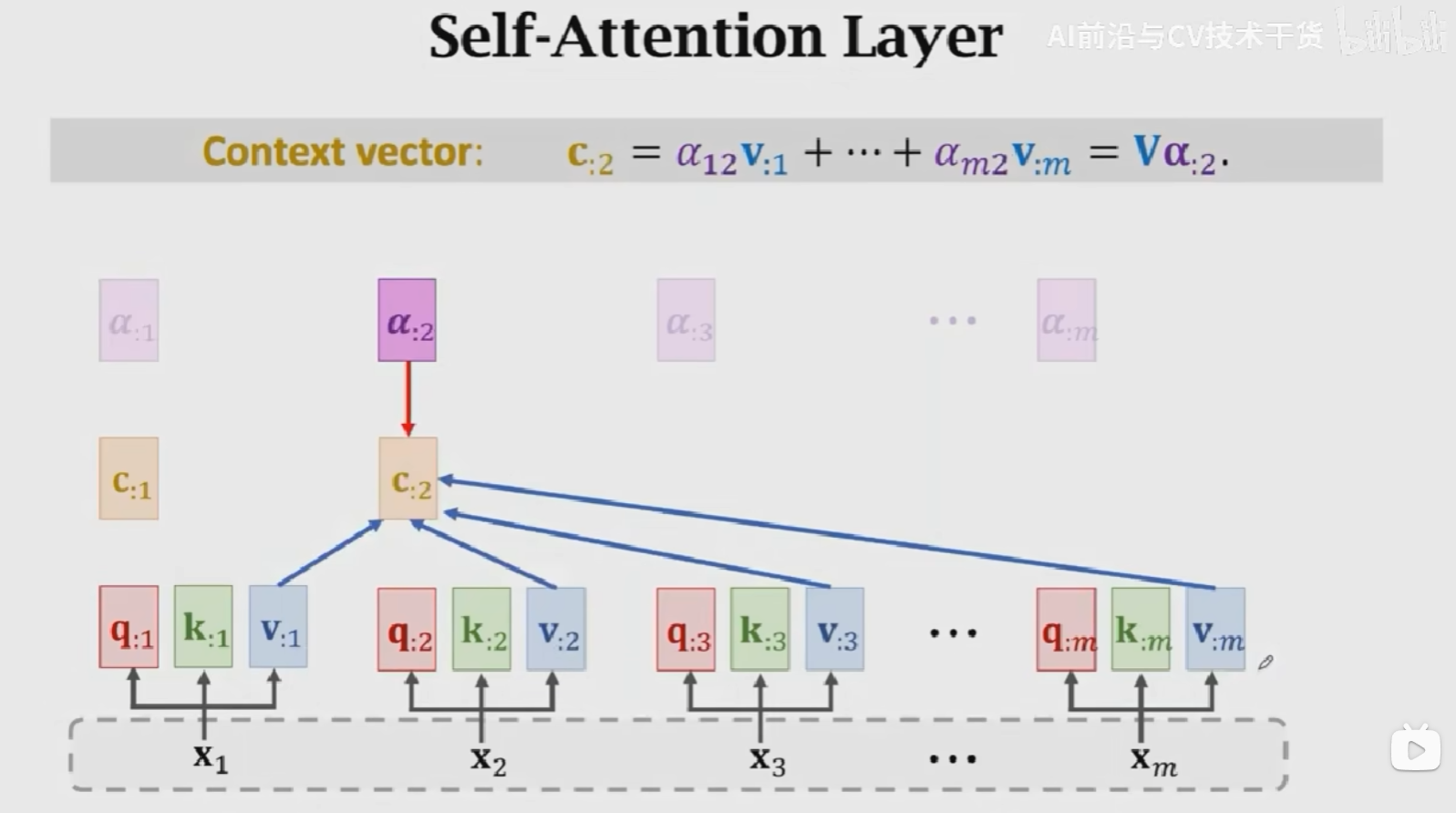
Attention Layer接收两个输入\(X = [x_1, x_2, x_3, ..., x_m]\),Decoder的输入为 \(X' = [x_1^{'}, x_2^{'}, x_3^{'}, ...,x_t^{'}]\),得到一个输出\(C = [c_1, c_2, c_3, ..., c_t]\),包含三个参数:\(W_Q, W_K, W_V\)。
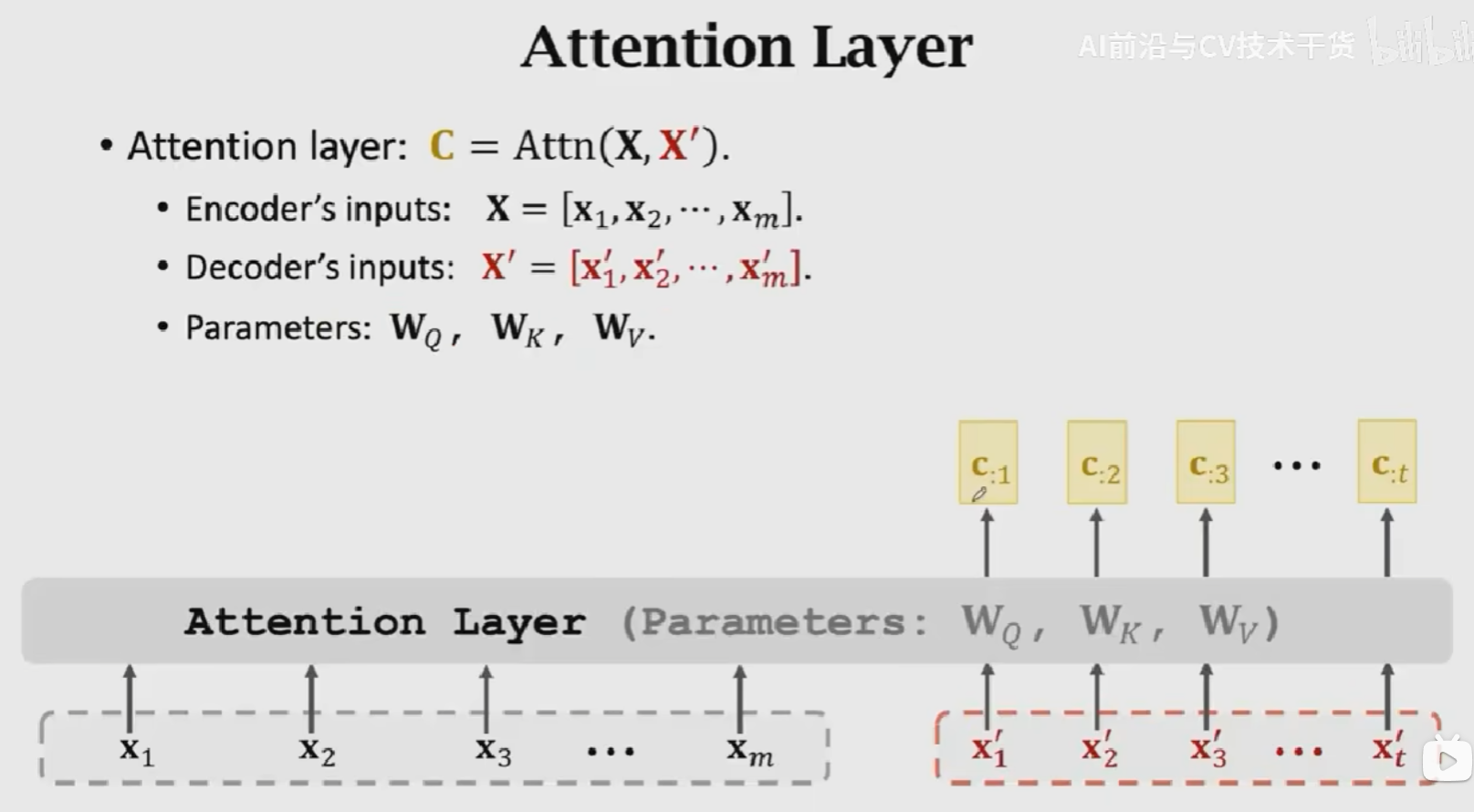
具体的计算流程为:
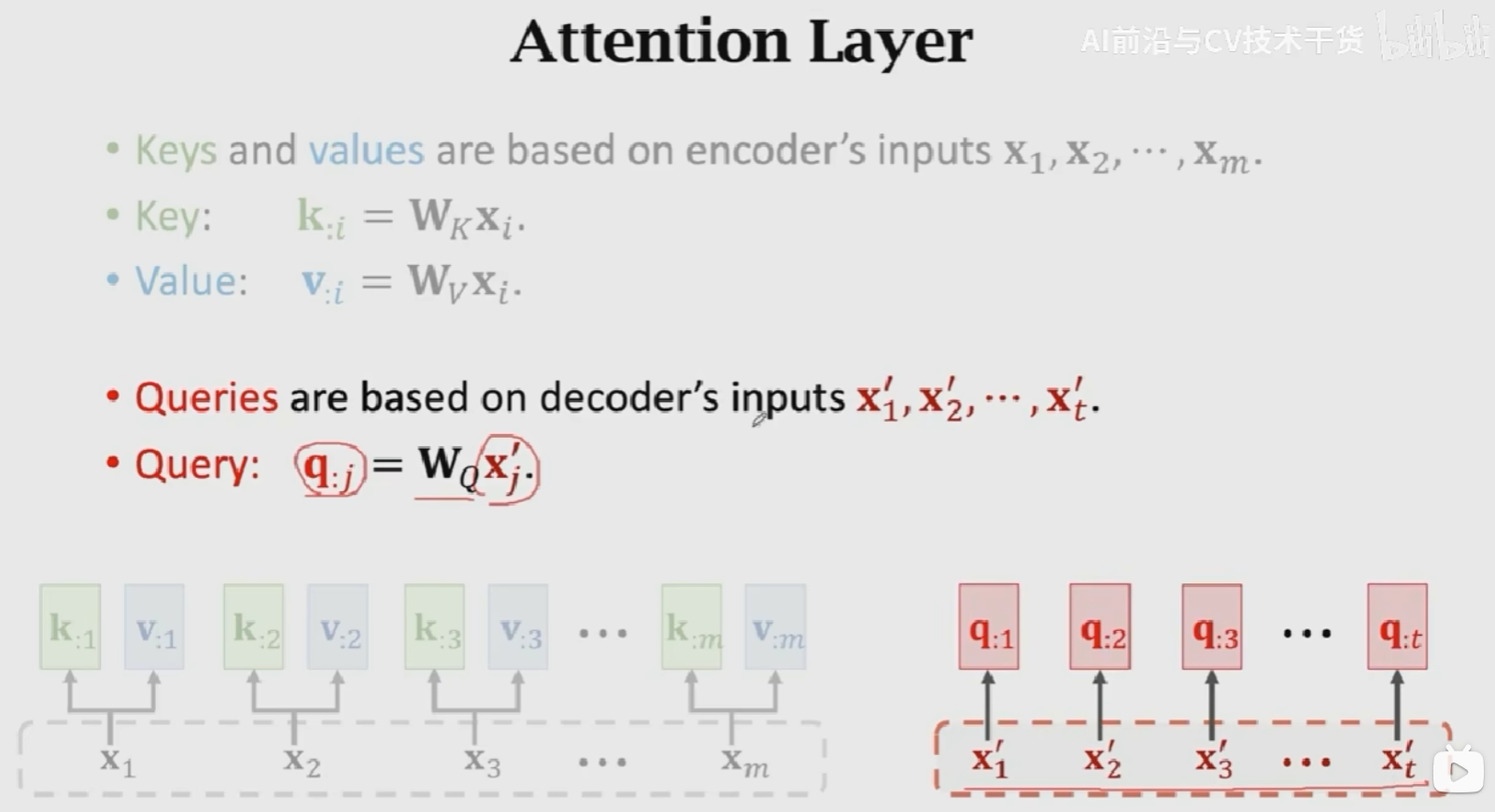
- 首先,使用Encoder的输入来计算Key和Value向量,得到m个k向量和v向量:\(k_{:i} = W_Kx_{:i}, v_{:i} = W_vx_{:i}\)
- 然后,对Decoder的输入做线性变换,得到t个q向量:\(q_{:j} = W_Qx_{:j}^{'}\)
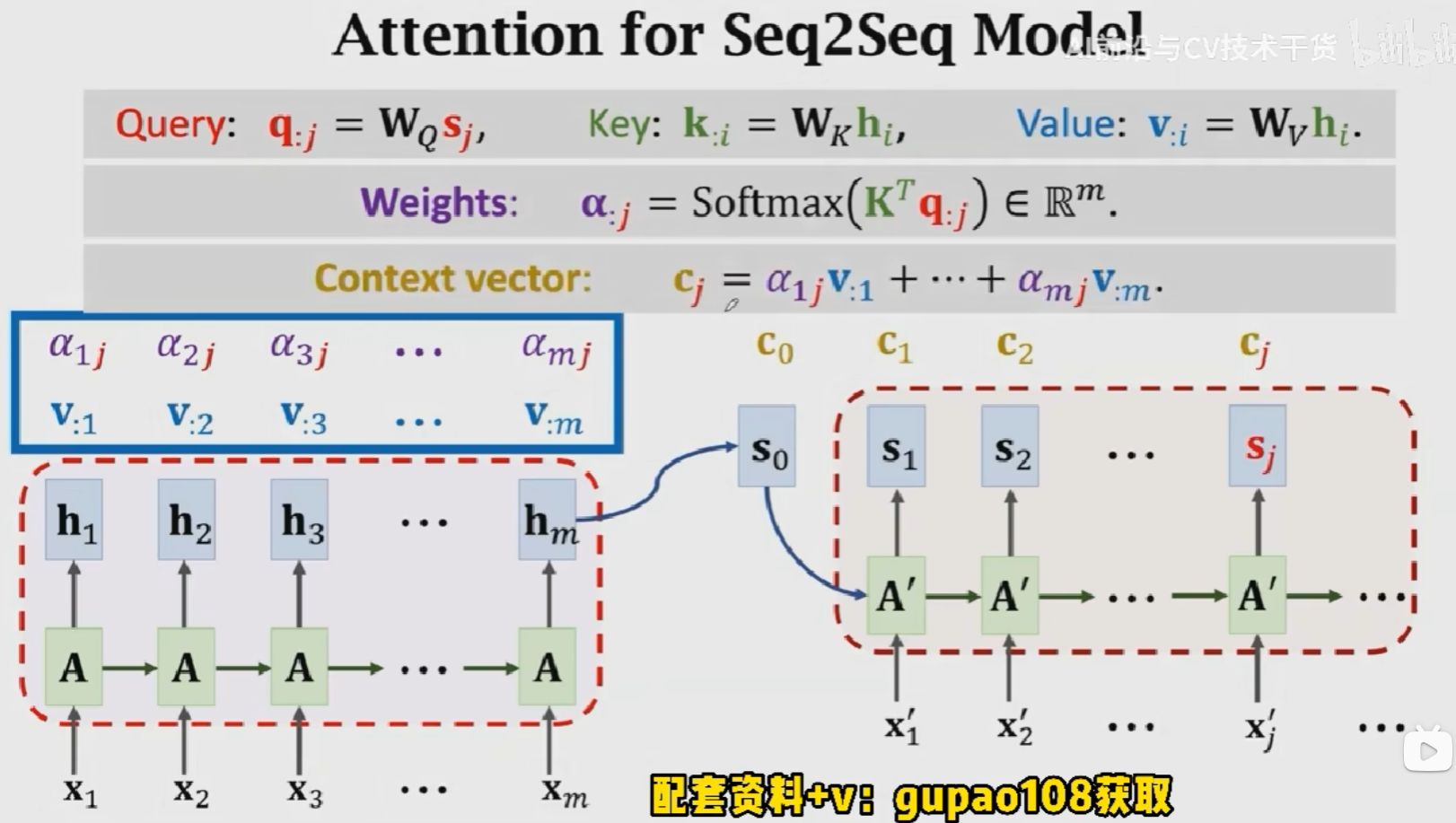
- 计算权重:\(\alpha_{:1} = Softmax(K^Tq_{:1})\)
- 计算Context vector:\(c_{:1} = \alpha_{11}v_{:1} + \alpha_{21}v_{:2} + ...\alpha_{m1}v_{:m} = V\alpha_{:1} = VSoftmax(K^Tq_{:1})\)
- 用相同的方式计算\(c_2, c_3, ..., c_t\),得到\(C = [c_1, c_2, ..., c_t]\)
Key:表示待匹配的值,Query表示查找值,这m个\(\alpha_{:j}\)就说明是query(\(q_j\))和所有key(\([k_{:1}, k_{:2}, ..., k_{:m}]\))之间的匹配程度。匹配程度越高,权重越大。V是对输入的一个线性变化,使用权重对其进行加权平均得到相关矩阵\(C\)。在Attention+RNN的结构中,是对输入状态进行加权平均,这里\(V\)相当于对\([h_1, h_2, ..., h_m]\)进行线性变换。
Self-Attention结构
Attention结构接收两个输入得到一个输出,Self-Attention结构接收一个输入得到一个输出,如下图所示。中间的计算过程与Attention完全一致。
Multi-head Self-Attention
上述的Self-Attention结构被称为单头Self-Attention(Single-Head Self-Attention)结构,Multi-Head Self-Attention就是将多个Single-Head Self-Attention的结构进行堆叠,结果Concatenate到一块儿。
假如有\(l\)个Single-Head Self-Attention组成一个Multi-Head Self-Attention,Single-Head Self-Attention的输入为\(X = [x_{:1}, x_{:2}, x_{:3}, ..., x_{:m}]\),输出为\(C = [c_{:1}, c_{:2}, c_{:3}, ..., c_{:m}]\)维度为\(dm\),
则,Multi-Head Self-Attention的输出维度为\((ld)*m\),参数量为\(l\)个\(W_Q, W_K, W_V\)即\(3l\)个参数矩阵。
Multi-Head Attention操作一致,就是进行多次相同的操作,将结果Concatenate到一块儿。
BERT:Bidirectional Encoder Representations from Transformers
BERT的提出是为了预训练Transformer的Encoder网络【BERT[4] is for pre-training Transformer's[3] encoder.】,通过两个任务(1)预测被遮挡的单词(2)预测下一个句子,这两个任务不需要人工标注数据,从而达到使用海量数据训练超级大模型的目的。
BERT有两种任务:
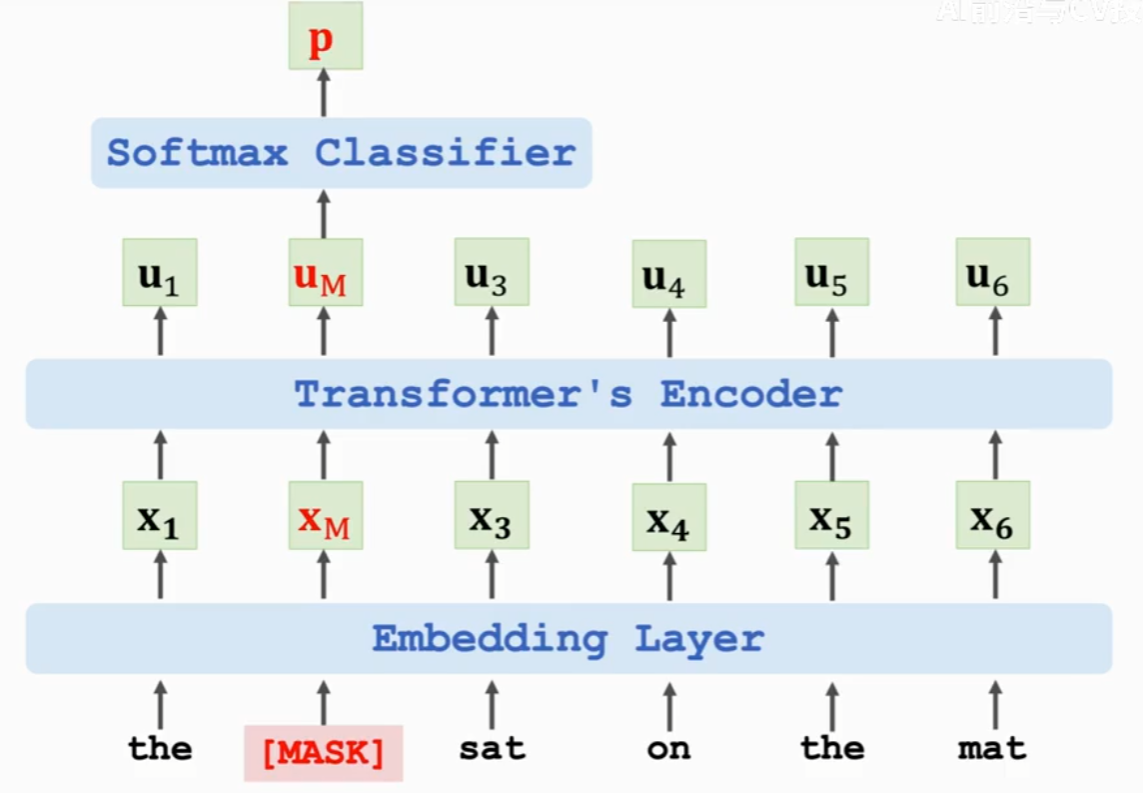
- Task 1: Predict the masked word,预测被遮挡的单词
输入:the [MASK] sat on the mat
groundTruth:cat
损失函数:交叉熵损失
- Task 2: Predict the next sentence,预测下一个句子,判断两句话在文中是否真实相邻
输入:[CLS, first sentence, SEP, second sentence]
输出:true or false
损失函数:交叉熵损失
这样做二分类可以让Encoder学习并强化句子之间的相关性。
好处:
- BERT does not need manually labeled data. (Nice, Manual labeling is expensive.)
- Use large-scale data, e.g., English Wikipedia (2.5 billion words)
- task 1: Randomly mask works(with some tricks)
- task 2: 50% of the next sentences are real. (the other 50% are fake.)
- BERT将上述两个任务结合起来预训练Transformer模型
- 想法简单且非常有效
消耗极大【普通人玩不起,但是BERT训练出来的模型参数是公开的,可以拿来使用】:
- BERT Base
- 110M parameters
- 16 TPUs, 4 days of training
- BERT Large
- 235M parameters
- 64 TPUs, 4days of training
Summary
Transformer:
- Transformer is a Seq2Seq model, it has an encoder and a decoder
- Transformer model is not RNN
- Transfomer is purely based on attention and dense layers(全连接层)
- Transformer outperforms all the state-of-the-art RNN models
Attention的发展:
- Attention was originally developed for Seq2Seq RNN models[1].
- Self-Attention: attention for all the RNN models(not necessarily for Seq2Seq models)[2].
- Attention can be used without RNN[3].
Reference
王树森的Transformer模型
[1] Bahdanau, Cho, & Bengio, Neural machine translation by jointly learning to align and translate. In ICLR, 2015.
[2] Cheng, Dong, & Lapata. Long Short-Term Memory-Networks for Machine Reading. In EMNLP, 2016.
[3] Vaswani et al. Attention Is All You Need. In NIPS, 2017.
[4] Devlin, Chang, Lee, and Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In ACL, 2019.
王树森Transformer学习笔记的更多相关文章
- 20135316王剑桥Linux内核学习笔记
王剑桥Linux内核学习笔记 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 计算机是如何工作的 个人理 ...
- 珂朵莉树(Chtholly Tree)学习笔记
珂朵莉树(Chtholly Tree)学习笔记 珂朵莉树原理 其原理在于运用一颗树(set,treap,splay......)其中要求所有元素有序,并且支持基本的操作(删除,添加,查找......) ...
- 20135316王剑桥Linux内核学习笔记第四周
20135316王剑桥 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC 1000029000 1.内核态:在高执行级别,代码可 ...
- 树链剖分学习笔记 By cellur925
先%一发机房各路祖传树剖大师%%%. 近来总有人向我安利树剖求LCA,然鹅我还是最爱树上倍增.然鹅又发现近年一些题目(如天天爱跑步.运输计划等在树上进行操作的题目),我有把树转化为一条链求解的思路,但 ...
- Unity3D行为树插件Behave学习笔记
Behave1.4行为树插件 下载地址:http://pan.baidu.com/s/1i4uuX0L 安装插件和使用 我们先来看看插件的安装和基本使用方法,新建一个Unity3D项目,这里我使用的是 ...
- BZOJ 2595: [Wc2008]游览计划 [DP 状压 斯坦纳树 spfa]【学习笔记】
传送门 题意:略 论文 <SPFA算法的优化及应用> http://www.cnblogs.com/lazycal/p/bzoj-2595.html 本题的核心就是求斯坦纳树: Stein ...
- 20135316王剑桥Linux内核学习笔记第三周
20135316王剑桥 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC 1000029000 三个法宝:存储程序计算机.函数调 ...
- 字典树(Trie)的学习笔记
按照一本通往下学,学到吐血了... 例题1 字典树模板题吗. 先讲讲字典树: 给出代码(太简单了...)! #include<cstdio> #include<cstring> ...
- 浅谈树套树(线段树套平衡树)&学习笔记
0XFF 前言 *如果本文有不好的地方,请在下方评论区提出,Qiuly感激不尽! 0X1F 这个东西有啥用? 树套树------线段树套平衡树,可以用于解决待修改区间\(K\)大的问题,当然也可以用 ...
- BA--关于江森的学习笔记
机房功率密度:“每机架”功耗 数据中心效率:平均 PUE 2.5,百度是1.36,苹果是1.06 绿色数据中心:PUE<1.58 机房环境:空气质量,配电,UPS,空气处理系统,发电机,江森OD ...
随机推荐
- 06 Spark SQL 及其DataFrame的基本操作
1.Spark SQL出现的 原因是什么? Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个叫作Data Frame的编程抽象结构数据模型(即带有Schema信息的RDD),S ...
- ethcat开发记录 二
SOEM移植到stm32f407+LAN8720硬件上的注意点 1.LAN8720的PHY地址问题. 2.LAN8720芯片在上电后要对复位引脚操作. 3.使能LAN8720的混杂模式,在新的HAL库 ...
- 项目实训 DAY14
今天修改了一下PNN使之可以运行直接生成图片,而不是敲两段命令行.首先是使用python中subprocess启动新进程来达到命令行输命令的效果,即生成xx.pdf:再用os.unlink将中间品删除 ...
- 常用的CSS效果(1)
单行省略 overflow: hidden; text-overflow: ellipsis; white-space: nowrap; 多行省略 display:-webkit-box; overf ...
- maven资源导出问题
<!--在build中配置resources,来防止我们资源导出失败的问题--> <build> <resources> <resource> < ...
- Yarn API
Yarn API: 1. 查询整个yarn集群指标: GET http://{cluster_domain_name}|{rm_ip:8088}/ws/v1/metrics 2. 查看指定队列的所有任 ...
- n-Queens(n皇后)问题的简单回溯
package com.main; import java.util.LinkedList; public class NoQueue { public LinkedList<Node> ...
- 使用Microsoft Network Monitor 抓包分析文件上传
Microsoft 自己提供了一个官方的抓包工具,可以比较方便的在windows平台抓包,并可以提供协议关键字正则.安装包位置:\\192.168.10.248\public\ghw\tools\MN ...
- jsp第4个作业(2)
<%@ page language="java" import="java.util.*" pageEncoding="utf-8"% ...
- Ubuntu常用命令(二)
clash 启动 #.clash -d . sudo /home/lizhenyun/clash/clash -d /home/lizhenyun/clash/ deb包安装 sudo dpkg -i ...