nodeJs 写个爬虫小玩意
内容
起一个服务,爬某个网站的数据(我这里爬了个夕阳红游戏交易网站的数据),页面看到我要爬的内容
代码
1 //引入内置的http包
2 var http = require('http');
3 const request = require("request");
4 const cheerio = require("cheerio");
5 //创建服务
6 var server = http.createServer(function(req, res) {
7 // res.end('111'); //注意这里 括号里不管是什么都要加上‘引号’
8 getInfo(res)
9 });
10
11 //端口监听
12 server.listen(8080);
13
14 /**
15 * 获取每一条的信息
16 */
17 const getInfo = (res) => {
18 res.writeHead(200, {'Content-type': 'text/html;charset=utf-8'})
19 request({
20 url: 'http://tl.cyg.changyou.com/goods/selling?world_id=0&have_chosen=&page_num=2#goodsTag',
21 method: 'get',
22 headers: {
23 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36',
24 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
25 // 这里巨坑!这里开启了gzip的话http返回来的是Buffer。
26 // 'Accept-Encoding': 'gzip, deflate',
27 'Accept-Language': 'zh-CN,zh;q=0.9',
28 'Cache-Control': 'no-cache',
29 },
30 // 想请求回来的html不是乱码的话必须开启encoding为null
31 encoding: null
32 }, (e, r, body) => {
33 // 这样就可以直接获取请求回来html了
34 // console.log('打印HTML', body.toString()); // <html>xxxx</html>
35 const $ = cheerio.load(body);
36 const $li = $('.pg-goods-list .role-item');
37 const list = []
38 $li.map((i, index) => {
39 let obj = {};
40 obj.link = $(index).children('dl').children('dt').children('a').attr('href');
41 list.push(obj);
42 res.write(obj.link)
43 res.write('<br/>')
44 });
45 res.write('<br/>')
46 res.end('爬完了') //注意这里 括号里不管是什么都要加上‘引号’
47 });
48 }
输出
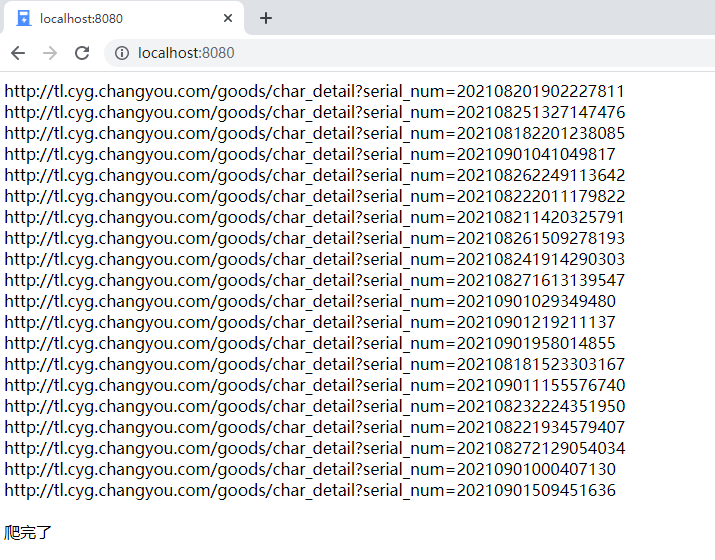
思路
本地起一个服务,然后打开页面,相当于调了一次请求,开始调取需要爬数据的网站的html,然后用cheerio相关的获取页面元素,类似jquery。然后把信息在页面上打印出来
nodeJs 写个爬虫小玩意的更多相关文章
- NodeJS写个爬虫,把文章放到kindle中阅读
这两天看了好几篇不错的文章,有的时候想把好的文章 down 下来放到 kindle 上看,便写了个爬虫脚本,因为最近都在搞 node,所以就很自然的选择 node 来爬咯- 本文地址:http://w ...
- 一次使用NodeJS实现网页爬虫记
前言 几个月之前,有同事找我要PHP CI框架写的OA系统.他跟我说,他需要学习PHP CI框架,我建议他学习大牛写的国产优秀框架QeePHP. 我上QeePHP官网,发现官方网站打不开了,GOOGL ...
- nodejs写的一个网页爬虫例子(坏链率)
因为工作需要,用nodejs写了个简单的爬虫例子,之前也没用过nodejs,连搭环境加写大概用了5天左右,so...要多简陋有多简陋,放这里给以后的自己看~~ 整体需求是:给一个有效的URL地址,返回 ...
- nodejs的简单爬虫
闲聊 好久没写博客了,前几天小颖在朋友的博客里看到了用nodejs的简单爬虫.所以小颖就自己试着做了个爬博客园数据的demo.嘻嘻...... 小颖最近养了条泰日天,自从养了我家 ...
- nodejs http小爬虫
本课程用nodejs写一个http小爬虫,首先科普一下,爬虫就是把网上的网页代码给弄下来,然后纳为己用.目前最大的爬虫:百度快照等的. 下面直接上代码 示例一: var http = require( ...
- nodejs eggjs框架 爬虫 readhub.me
最近做了一款 高仿ReadHub小程序 微信小程序 canvas 自动适配 自动换行,保存图片分享到朋友圈 https://gitee.com/richard1015/News 具体代码已被开源, ...
- 读书笔记汇总 --- 用Python写网络爬虫
本系列记录并分享:学习利用Python写网络爬虫的过程. 书目信息 Link 书名: 用Python写网络爬虫 作者: [澳]理查德 劳森(Richard Lawson) 原版名称: web scra ...
- [原创]手把手教你写网络爬虫(4):Scrapy入门
手把手教你写网络爬虫(4) 作者:拓海 摘要:从零开始写爬虫,初学者的速成指南! 封面: 上期我们理性的分析了为什么要学习Scrapy,理由只有一个,那就是免费,一分钱都不用花! 咦?怎么有人扔西红柿 ...
- [原创]手把手教你写网络爬虫(5):PhantomJS实战
手把手教你写网络爬虫(5) 作者:拓海 摘要:从零开始写爬虫,初学者的速成指南! 封面: 大家好!从今天开始,我要与大家一起打造一个属于我们自己的分布式爬虫平台,同时也会对涉及到的技术进行详细介绍.大 ...
- [原创]手把手教你写网络爬虫(7):URL去重
手把手教你写网络爬虫(7) 作者:拓海 摘要:从零开始写爬虫,初学者的速成指南! 封面: 本期我们来聊聊URL去重那些事儿.以前我们曾使用Python的字典来保存抓取过的URL,目的是将重复抓取的UR ...
随机推荐
- org.springframework.web.filter.CharacterEncodingFilter cannot be cast to javax.servlet.Filter异常
转:https://blog.csdn.net/u010670689/article/details/40301043 使用maven开发web应用程序, 启动的时候报错: jar not loade ...
- 不花钱几分钟让你的站点也支持https
前言 现在,免费SSL证书已经很普遍了,但是,申请和配置SSL证书仍然是一件较为繁琐的事,修改web服务配置在所难免,且不同的web服务配置方法不一样,不具备通用性.本文介绍一种通用的快速配置方法,w ...
- Opengl ES之踩坑记
前因 最近在尝试使用Opengl ES实现一些LUT滤镜效果,在实现这些滤镜效果的时候遇到一些兼容性的坑,踩过这些坑后我希望把这几个坑分享给读者朋友们, 希望同在学习Opengl ES的朋友们能少走弯 ...
- 样本熵(SampEn)的C/C++代码实现与优化
正文 本文不介绍什么是样本熵,具体推荐看此文https://blog.csdn.net/Cratial/article/details/79742363,写的很好,里面的示例也被我拿来测试代码写的对不 ...
- 多重背包问题 II
有 NN 种物品和一个容量是 VV 的背包. 第 ii 种物品最多有 sisi 件,每件体积是 vivi,价值是 wiwi. 求解将哪些物品装入背包,可使物品体积总和不超过背包容量,且价值总和最大.输 ...
- dotnet总结
初衷: 搞了几年.Net ,一直没在博客园做过系统的总结,并打算按照下面的结构来写 语言层面 类型系统 [查看]: https://www.cnblogs.com/francisXu/p/136027 ...
- vue api封装 request.js
import axios from 'axios' import { Message, MessageBox } from 'element-ui' import store from '../sto ...
- springboot跳转页面404的问题
今天测试的时候出现了这个问题: Cannot forward to error page for request [/] as the response has already been commit ...
- HTML+js页面横向分栏效果
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- 后台Mysql存储过程调用
https://blog.csdn.net/weixin_43695211/article/details/127883536