数组还是HashSet?
我记得大约在半年前,有个朋友问我一个问题,现在有一个选型:
一个性能敏感场景,有一个集合,需要确定某一个元素在不在这个集合中,我是用数组直接
Contains还是使用HashSet<T>.Contains?

大家肯定想都不用想,都选使用HashSet<T>,毕竟HashSet<T>的时间复杂度是O(1),但是后面又附加了一个条件:
这个集合的元素很少,就4-5个。
那这时候就有一些动摇了,只有4-5个元素,是不是用数组Contains或者直接遍历会不会更快一些?当时我也觉得可能元素很少,用数组就够了。
而最近在编写代码时,又遇到了同样的场景,我决定来做一下实验,看看元素很少的情况下,是不是使用数组优于HashSet<T>。
测试
我构建了一个测试,分别尝试在不同的容量下,查找一个元素,使用数组和HashSet的区别,代码如下所示:
[GcForce(true)]
[MemoryDiagnoser]
[Orderer(SummaryOrderPolicy.FastestToSlowest)]
public class BenchHashSet
{
private HashSet<string> _hashSet;
private string[] _strings;
[Params(1,2,4,64,512,1024)]
public int Size { get; set; }
[GlobalSetup]
public void Setup()
{
_strings = Enumerable.Range(0, Size).Select(s => s.ToString()).ToArray();
_hashSet = new HashSet<string>(_strings);
}
[Benchmark(Baseline = true)]
public bool EnumerableContains() => _strings.Contains("8192");
[Benchmark]
public bool HashSetContains() => _hashSet.Contains("8192");
}
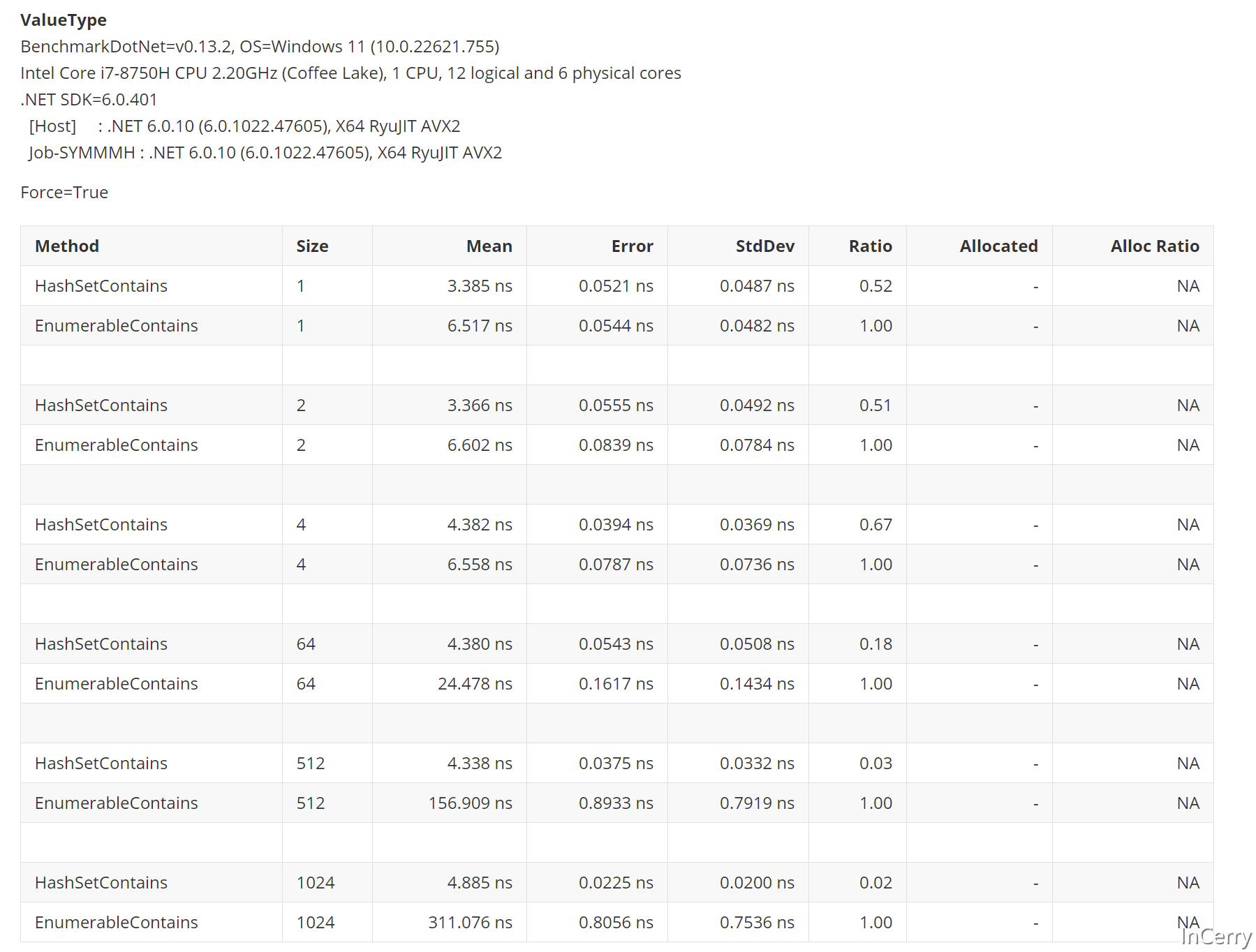
大家猜猜结果怎么样,就算Size只为1,那么HashSet也比数组Contains遍历快40%。

那么故事就这么结束了吗?所以无论如何场景我们都直接无脑使用HashSet就行了吗?大家看滑动条就知道,故事没有这么简单。
刚刚我们是引用类型的比较,那值类型怎么样?结论就是一样的结果,就算只有1个元素也比数组的Contains快。
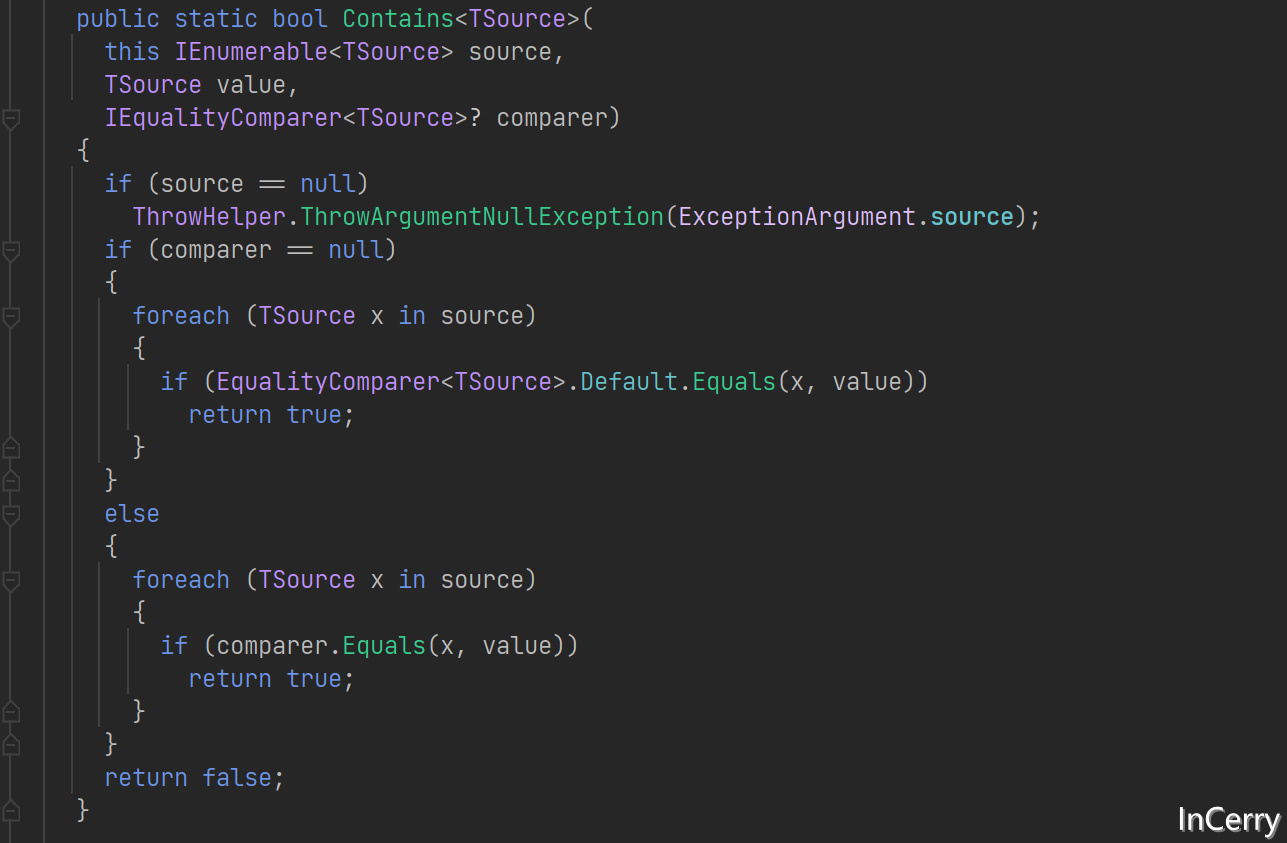
那么问题出在哪里?点进去看一下数组Contains方法的实现就清楚了,这个东西使用的是Enumerable迭代器匹配。
那么我们直接来个原始的,Array.IndexOf匹配和for循环匹配试试,于是有了如下代码:
[GcForce(true)]
[MemoryDiagnoser]
[Orderer(SummaryOrderPolicy.FastestToSlowest)]
public class BenchHashSetValueType
{
private HashSet<int> _hashSet;
private int[] _arrays;
[Params(1,4,16,32,64)]
public int Size { get; set; }
[GlobalSetup]
public void Setup()
{
_arrays = Enumerable.Range(0, Size).ToArray();
_hashSet = new HashSet<int>(_arrays);
}
[Benchmark(Baseline = true)]
public bool EnumerableContains() => _arrays.Contains(42);
[Benchmark]
public bool ArrayContains() => Array.IndexOf(_arrays,42) > -1;
[Benchmark]
public bool ForContains()
{
for (int i = 0; i < _arrays.Length; i++)
{
if (_arrays[i] == 42) return true;
}
return false;
}
[Benchmark]
public bool HashSetContains() => _hashSet.Contains(42);
}
接下来结果就和我们预想的差不多了,在数组元素小的时候,使用原始的for循环比较会快,然后HashSet就变为最快的了,在更多元素的场景中Array.IndexOf会比for更快:
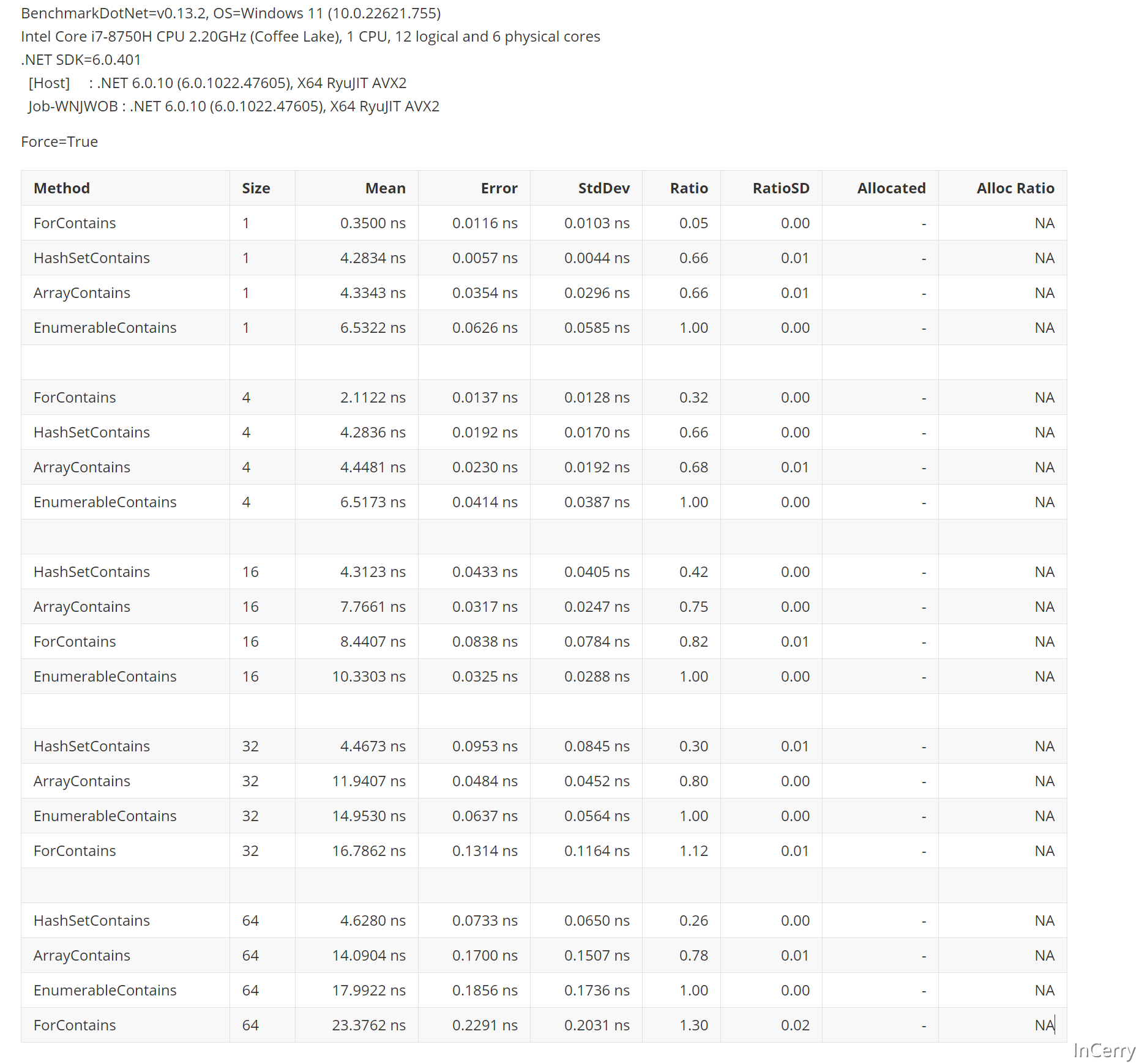
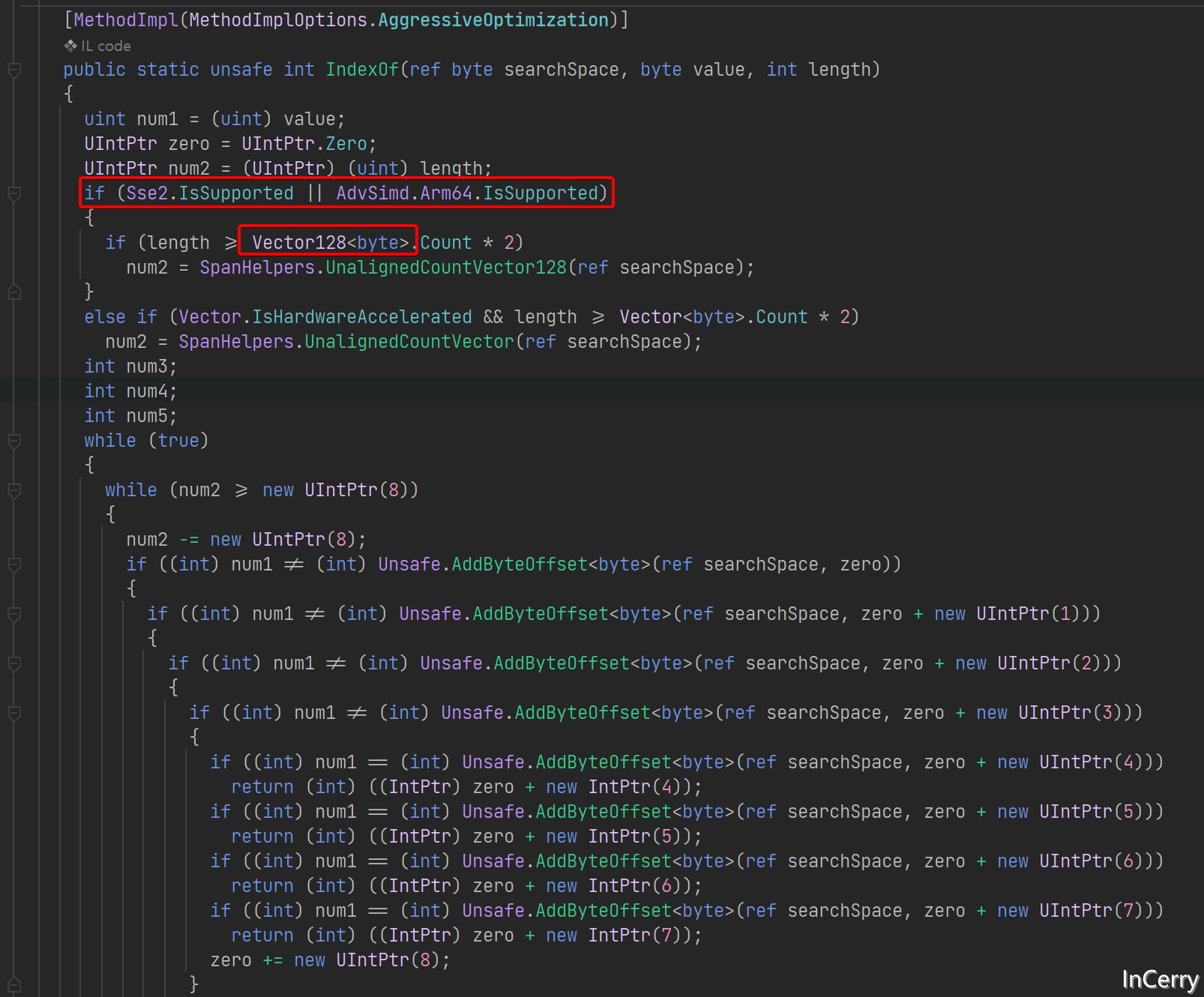
至于为什么在元素多的情况Array.IndexOf会比for更快,那是因为Array.IndexOf底层使用了SIMD来优化,在之前的文章中,我们多次提到了SIMD,这里就不赘述了。
既然如此我们再来确认一下,到底多少个元素以内用for会更快,可以看到16个元素以内,for循环会快于HashSet:
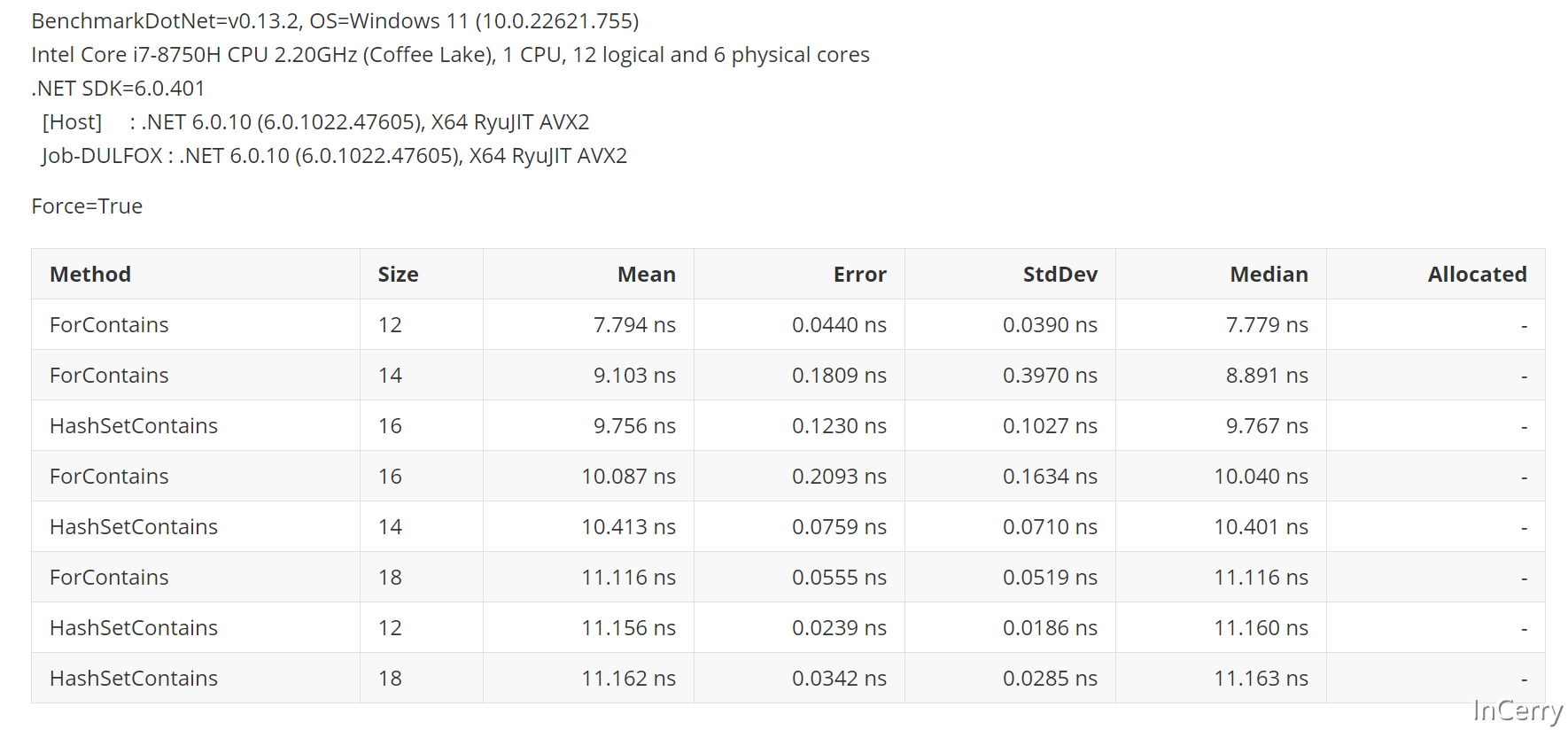
总结
所以我们应该选择HashSet<T>还是数组呢?这个就需要分情况简单的总结一下:
- 在小于16个元素场景,使用
for循环匹配会比较快。 - 16-32个元素的场景,速度最快是
HashSet<T>然后是Array.IndexOf、for、IEnumerable.Contains。 - 大于32个元素的场景,速度最快是
HashSet<T>然后是Array.IndexOf、IEnumerable.Contains、for。
从这个上面来看,大于32个元素就不合适直接用for比较了。不过这些差别都很小,除非是性能非常敏感的场景,可以忽略不计,本文解决了笔者的一些困扰,简单记录一下。
数组还是HashSet?的更多相关文章
- 2. 三数之和(数组、hashset)
思路及算法: 该题与第一题的"两数之和"相似,三数之和为0,不就是两数之和为第三个数的相反数吗?因为不能重复,所以,首先进行了一遍排序:其次,在枚举的时候判断了本次的第三个数的值是 ...
- C# 数组、HashSet等内存耗尽的解决办法
在C#中,如果数据量太大,就会出现 'System.OutOfMemoryException' 异常. 解决办法来自于Stack Overflow和MSDN https://docs.micro ...
- 2.请介绍一下List和ArrayList的区别,ArrayList和HashSet区别
第一问: List是接口,ArrayList实现了List接口. 第二问: ArrayList实现了List接口,HashSet实现了Set接口,List和Set都是继承Collection接口. A ...
- HashSet非常的消耗空间,TreeSet因为有排序功能,因此资源消耗非常的高,我们应该尽量少使用
注:HashMap底层也是用数组,HashSet底层实际上也是HashMap,HashSet类中有HashMap属性(我们如何在API中查属性).HashSet实际上为(key.null)类型的Has ...
- 5.秋招复习简单整理之请介绍一下List和ArrayList的区别,arrayList和HashSet区别?
第一问:List是接口,ArrayList是List的实现类. 第二问:ArrayList是List的实现类,HashSet是Set的实现类,List和Set都实现了Collection接口. Arr ...
- JAVA的面向对象编程--------课堂笔记
面向对象主要针对面向过程. 面向过程的基本单元是函数. 什么是对象:EVERYTHING IS OBJECT(万物皆对象) 所有的事物都有两个方面: 有什么(属性):用来描述对象. 能够做什么 ...
- Java琐碎知识点
jps命令是JDK1.5提供的一条显示当前用户的所有java进程pid的指令,类似Linux上的ps命令简化版,Windows和linux/unix平台都可以用比较常用的参数:-q:只显示pid,不显 ...
- linkin大话数据结构--Map
Map 映射关系,也有人称为字典,Map集合里存在两组值,一组是key,一组是value.Map里的key不允许重复.通过key总能找到唯一的value与之对应.Map里的key集存储方式和对应的Se ...
- java库中的具体的集合
1.ArrayList 一种可以动态增长和缩减的索引序列:速度较慢适合用于不修改太多的元素 采用的数组 2.LinkEdList 一种可以在任何位置进行高效的插入和删除操作的有序序列,适合于 ...
随机推荐
- 字符串KMP——用途广泛的字符串匹配算法 + 扩展KMP——特殊定义的字符串匹配
引 入 引入 引入 " SY 和 WYX 在看毛片.(几 毛 钱买到的动作 片,毛 片) WYX 突然想回味一个片段,但是只记得台词里面有一句挺长的 " ∗ ∗ ∗ ∗ **** ...
- mysql_唯一索引数据重复问题总结
CREATE TABLE `tt_transfer_assemble_diffuse_plan_info` ( `id` bigint(20) unsigned NOT NULL AUTO_INCRE ...
- Hive的基本知识与操作
Hive的基本知识与操作 目录 Hive的基本知识与操作 Hive的基本概念 为什么使用Hive? Hive的特点: Hive的优缺点: Hive应用场景 Hive架构 Client Metastor ...
- torch.stack()与torch.cat()
torch.stack():http://www.45fan.com/article.php?aid=1D8JGDik5G49DE1X torch.stack()个人理解:属于先变形再cat的操作,所 ...
- torch.meshgrid
1:https://blog.csdn.net/weixin_39504171/article/details/106356977 2: https://pytorch.org/docs/stable ...
- haodoop企业优化
MapReduce 跑的慢的原因 MapReduce程序效率的瓶颈在于两点 计算机性能 CPU,内存,磁盘健康,网络 I/O操作优化 数据倾斜 Map和Reduce数设置不合理 Map运行时间太长,导 ...
- SonarQube支持Gitlab授权登录
部署好SonarQube之后,由于我们内部使用的是自建的Gitlab仓库,即每个开发同学都有Gitlab账号,SonarQube我们就可以使用上Gitlab登录,这样就不需要再维护一套用户体系了. S ...
- Elasticsearch:跨集群复制 Cross-cluster replication(CCR)
- 利用curl命令访问Kubernetes API server
kubectl 通过访问 Kubernetes API 来执行命令.我们也可以通过对应的TLS key, 使用curl 或是 golang client做同样的事. API 请求必须使用 JSON 格 ...
- netstat -lnp |grep XXX后不显示进程
netstat -lnp |grep XXX后不显示进程,不一定是没有进程,可能是这个命令不好使,换成 ps -ef | grep XXX