requests模块之post请求传参json和data区别
post请求参数到底是传data还是json,此时要看请求头里的content-type类型
请求头中content-type为application/json, 为json形式,post请求使用json参数
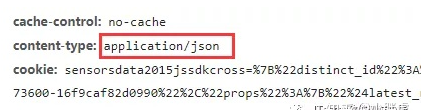
请求头中content-type为application/x-www-form-urlencoded为表单形式,post请求时使用使用data参数
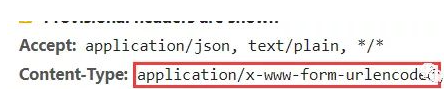
当前接口的请求类型为application/x-www-form-urlencoded,data形式发送post请求
#导入requests模块
import requests
#请求url
url="http://127.0.0.1:8000/user/login"
#请求参数
payload={
"mobilephone":"1530272****",
"pwd":"123456"}
form表单形式,参数用data
res=requests.post(url,data=payload)
print(res.text)
当前接口的请求类型为application/json,json形式发送post请求
import requests
url='http://127.0.0.1:8000/user/login/'
headers={"content-type":"application/json"}
payload={"username":"vivi","password":"123456"}
res=requests.post(url,json=payload,headers=headers)
print(res.text)
当前接口的请求类型为application/json,简单点用json形式发送post请求,但也可通过data发送需将字典类型转化为json字符串
import requests
import json
payload={"username":"vivi","password":"123456"}
header={"content-type":"application/json"}
#字典转化为json串
data=json.dumps(payload)
url='http://127.0.0.1:8000/user/login/'
res=requests.post(url,data=data,headers=header)
print(res.text)
requests模块之post请求传参json和data区别的更多相关文章
- scrapy模块之分页处理,post请求,cookies处理,请求传参
一.scrapy分页处理 1.分页处理 如上篇博客,初步使用了scrapy框架了,但是只能爬取一页,或者手动的把要爬取的网址手动添加到start_url中,太麻烦接下来介绍该如何去处理分页,手动发起分 ...
- 13.scrapy框架的日志等级和请求传参
今日概要 日志等级 请求传参 如何提高scrapy的爬取效率 今日详情 一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是s ...
- requests中get和post传参
get请求 get(url, params=None, **kwargs) requests实现get请求传参的两种方式 方式一: import requests url = 'http://www. ...
- scrapy框架的日志等级和请求传参
日志等级 请求传参 如何提高scrapy的爬取效率 一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息 ...
- scrapy框架的日志等级和请求传参, 优化效率
目录 scrapy框架的日志等级和请求传参, 优化效率 Scrapy的日志等级 请求传参 如何提高scripy的爬取效率 scrapy框架的日志等级和请求传参, 优化效率 Scrapy的日志等级 在使 ...
- 12 Scrapy框架的日志等级和请求传参
一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息. - 日志信息的种类: ERROR : 一般错误 ...
- [转]ASP.NET MVC学习系列(二)-WebAPI请求 传参
[转]ASP.NET MVC学习系列(二)-WebAPI请求 传参 本文转自:http://www.cnblogs.com/babycool/p/3922738.html ASP.NET MVC学习系 ...
- scrapy框架之日志等级和请求传参-cookie-代理
一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息. - 日志信息的种类: ERROR : 一般错误 ...
- Scrapy的日志等级和请求传参
日志等级 日志信息: 使用命令:scrapy crawl 爬虫文件 运行程序时,在终端输出的就是日志信息: 日志信息的种类: ERROR:一般错误: WARNING:警告: INFO:一般的信息: ...
- 爬虫开发10.scrapy框架之日志等级和请求传参
今日概要 日志等级 请求传参 今日详情 一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息. - 日志 ...
随机推荐
- php curl方法封装
/** * @desc 获取设备的监控项实时值 * * @return url请求地址 * @return method 请求方法(POST,GET,PUT)等 * @return postfiel ...
- c#笔记(四)——switch
---恢复内容开始--- using UnityEngine; using System.Collections; public class Script1 : MonoBehaviour { ...
- Linux基本概念
目录 1. 内核.内核态和用户态 2. 用户和组 3. 文件和文件系统 4. I/O模型 5. 程序.进程.线程和协程 6. shell.终端和会话 1. 内核.内核态和用户态 内核是指管理和分配 ...
- vue-vite-ts 新版
Vue 后台管理系统 一.系统创建 1.1.环境检测 $ node -v v18.10.0 $ npm -v 9.1.2 ## 若没有该命令 需要用 npm install -g pnpm 安装 $ ...
- 理解cpu过高的逻辑思维与分析方法
工作经常碰到负载过高,cpu占有太高,系统变慢,运维通常做的第一件事就是通过top或者uptime命令来了解系统负载的情况 通常uptime后会出现三个小数,就是平均负载值,那真正的了解这个平均负载值 ...
- Uncaught ReferenceError: Vue is not defined(之二)
背景最近开发的一个项目,前段时间开发过程中还好好的,最近一次打包部署后,浏览器访问一直是打不开: 打开控制台,看到的一个报错如下: 作为一个前端不太熟练的后端研发,我在网上根据关键字:Vue is n ...
- C#如何将光标定位到文本框末尾(最后一位)
代码如下:private void Movetoend(){//让文本框获取焦点this.TextBox1.Focus();//设置光标的位置到文本尾this.TextBox1.Select(this ...
- maven本地安装jar包
mvn install:install-file -Dfile=cs-pay-client-2.0.0.jar -DgroupId=com.test.pay -DartifactId=gh-epay- ...
- 某个灰产远程调用的script源码
访问一个老域名,可能是释放了被所灰产的的注册了,跳转简单扒下他们的源码. 主要是三段script代码,第一段是百度自动推送代码,第二段是站长统计代码,第三段则是远程调用断码. <html xml ...
- (jmeter笔记)jmeter监控服务器资源
jmeter版本:5.2.1 jdk版本:1.8.0_191 监控服务器的CPU/memory.IO.硬盘等信息 1.下载jmeter-plugins-manager-1.4.jar 插件,解压之后把 ...