#Python 文本包含函数,pandas库 Series.str.contains 函数
一:基础的函数组成
’’‘Series.str.contains(pat,case = True,flags = 0,na = nan,regex = True)’’'
测试pattern或regex是否包含在Series或Index的字符串中。
返回布尔值系列或索引,具体取决于给定模式或正则表达式是否包含在系列或索引的字符串中。
pat : str类型
字符序列或正则表达式。
case : bool,默认为True
如果为True,区分大小写。
flags : int,默认为0(无标志)
标志传递到re模块,例如re.IGNORECASE。
na : 默认NaN
填写缺失值的值。
regex : bool,默认为True
如果为True,则假定pat是正则表达式。
如果为False,则将pat视为文字字符串。
二:示例应用
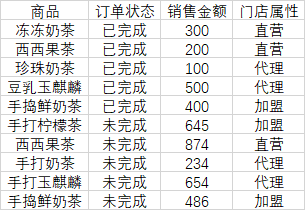
2.1 数据源展示
模拟一个奶茶销售表,包含商品名称,订单状态,销售金额,门店属性四个维度。
2.2 条件筛选(多列)
假设需求:目前需要直营门店、已完成状态的销售表
#模块导入
import pandas as pd
import numpy as np
#路径设置
source_data = r"E:/360MoveData/Users/B/Desktop/pandas_test.xlsx"
out_put = r"E:/360MoveData/Users/B/Desktop/output_data.xlsx"
#筛选条件设置
t1 = data1["门店属性"].str.contains("直营")
t2 = data1["订单状态"].str.contains("已完成")
#根据筛选条件返回成表
result = data1[t1&t2]
#输出成表
print(result)
#导出
result.to_excel(out_put)
输出结果,如下。

通过函数我们可以同时控制多个列的筛选条件,并输出成表。
2.3 文本筛选(同一列)
仍旧使用前文的数据源
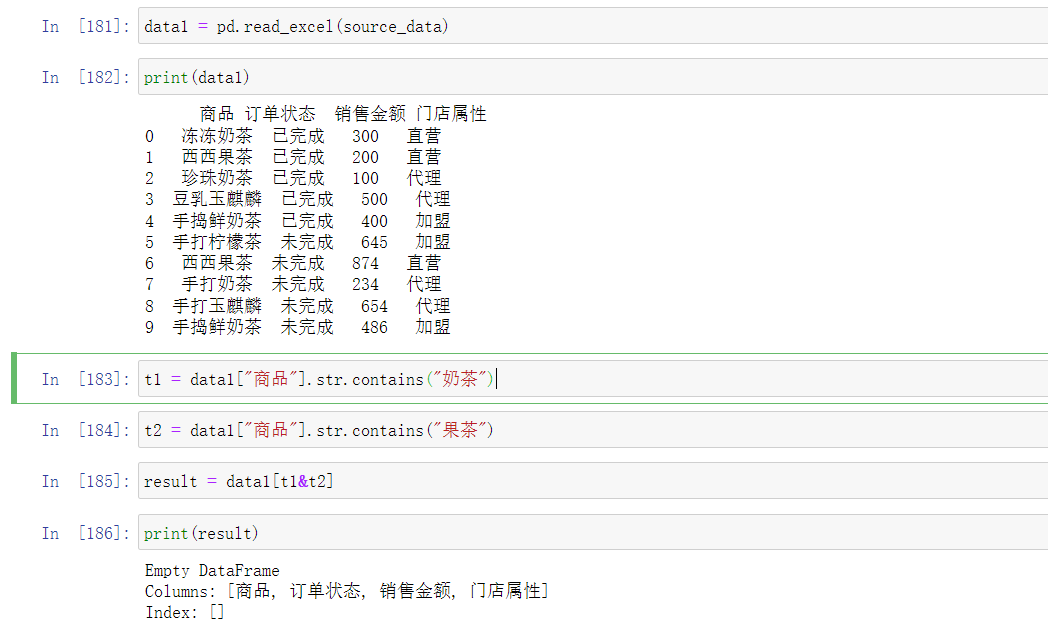
现在我们假设需求:商品品名中含有"奶茶",或者"果茶"的商品销售表
首先,我们来试试上一种方式,可以看到,这里的输出并不是我们想要的表
这里,我们换一个方式来实现。
data1.loc[data1["商品"].str.contains("奶茶|果茶",na = False),"订单判断"] = "目标订单"
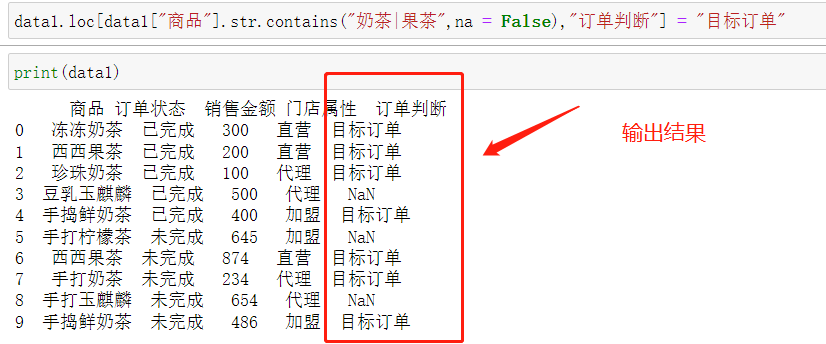
可以看到,商品这一列中含有奶茶、果茶的商品被标记了。
3:总结
利用str.contains,我们可以筛选同一列,不同列的数据,对于活动清洗、订单清洗等数据清洗环节,可以更快的标记对应的订单。
我是simone,期待下次的分享。
#Python 文本包含函数,pandas库 Series.str.contains 函数的更多相关文章
- Python数据分析工具:Pandas之Series
Python数据分析工具:Pandas之Series Pandas概述Pandas是Python的一个数据分析包,该工具为解决数据分析任务而创建.Pandas纳入大量库和标准数据模型,提供高效的操作数 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用python进行数据分析之pandas库的应用(二)
本节介绍Series和DataFrame中的数据的基本手段 重新索引 pandas对象的一个重要方法就是reindex,作用是创建一个适应新索引的新对象 >>> from panda ...
- 【Python学习笔记】Pandas库之DataFrame
1 简介 DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表. 或许说它可能有点像matlab的矩阵,但是matlab的矩阵只能放数值型值(当然matla ...
- 用python做数据分析4|pandas库介绍之DataFrame基本操作
原文地址 怎样删除list中空字符? 最简单的方法:new_list = [ x for x in li if x != '' ] 今天是5.1号. 这一部分主要学习pandas中基于前面两种数据结构 ...
- pandas库Series类型与基本操作
pandas读取excel的类型是dataFrame,然后提取每一列是一个Series类型 Series类型包括index和values两部分 a = pd.Series({'a':1,'b':5}) ...
- 利用python进行数据分析之pandas库的应用(一)
一.pandas的数据结构介绍 Series Series是由一种类似于一维数组的对象,它由一组数据以及一组与之相关的数据索引构成.仅由一组数据可产生最简单的Series. obj=Series([4 ...
- 数据分析之pandas库--series对象
1.Series属性及方法 Series是Pandas中最基本的对象,Series类似一种一维数组. 1.生成对象.创建索引并赋值. s1=pd.Series() 2.查看索引和值. s1=Serie ...
- 【转】Pandas的Apply函数——Pandas中最好用的函数
转自:https://blog.csdn.net/qq_19528953/article/details/79348929 import pandas as pd import datetime #用 ...
随机推荐
- windows 查看 tcp 连接表
netstat -ant|find /I "192.168.1.1" netstat -na -p tcp| findstr 80 | find "ESTABLISH&q ...
- .bat 脚本替换文件内容
rem 定义变量延迟环境,关闭回显 @echo off&setlocal enabledelayedexpansion rem 读取a.txt所有内容 for /f "eol=* t ...
- boost编译指定python版本号
1.执行如下 bootstrap 语句,会在目录下生成 project-config.jam 文件 .\bootstrap --with-python="C:\Users\yzy\Anaco ...
- MathJax使用
转载网址: http://t.zoukankan.com/Dean0731-p-12881872.html
- AI 脸部美容,一键让你变瘦变美变老变年轻
目录 项目效果 项目安装 安装环境 项目使用 项目效果 随着 AI 技术的发展,你不仅随时可以看到自己的老了之后的样子,还能看到自己童年的样子 随着这部分技术的开源,会有越来越多的应用,当然我觉得前景 ...
- Spring--依赖注入:setter注入和构造器注入
依赖注入:描述了在容器中建立Bean于Bean之间依赖关系的过程 setter注入 在本来已经在service里面引用了bean的相关方法的基础上,再引用之前已经写过的userDao的对象,即在ser ...
- 最近写了一个demo,想看看java和go语言是怎么写的
最近写了一个demo:demo的github地址 一. 简单介绍 1. Server端 它是一个WebApi服务,把它当成一个黑盒就行了. 2. MiddleServer端 是重点,它是一个WebAp ...
- 机器学习(二):感知机+svm习题 感知机手工推导参数更新 svm手推求解二维坐标超平面直线方程
作业1: 输入: 训练数据集 \(T = {(x1; y1); (x2; y2),..., (xN; yN)}\) 其中,\(x \in R^n\), \(y \in Y = \{+1, -1\}\) ...
- redis.clients.jedis.exceptions.JedisConnectionException: Failed connecting to "xxxxx"
Java 连接 Redis所遇问题 1. 检查Linux是否关闭防火墙,或对外开放redis默认端口6379 关闭防火墙. systemctl stop firewalld 对外开放端口.firewa ...
- 剑指 offer 第 3 天
第 3 天 字符串(简单) 剑指 Offer 05. 替换空格 请实现一个函数,把字符串 s 中的每个空格替换成"%20". 示例 1: 输入:s = "We are h ...