NLP实践!文本语法纠错模型实战,搭建你的贴身语法修改小助手 ⛵

作者:韩信子@ShowMeAI
深度学习实战系列:https://www.showmeai.tech/tutorials/42
自然语言处理实战系列:https://www.showmeai.tech/tutorials/45
本文地址:https://showmeai.tech/article-detail/399
声明:版权所有,转载请联系平台与作者并注明出处
收藏ShowMeAI查看更多精彩内容
自然语言处理(NLP)技术可以完成文本数据上的分析挖掘,并应用到各种业务当中。例如:
- 机器翻译(Machine Translation),接收一种语言的输入文本并返回目标语言的输出文本(包含同样的含义)。
- 情感分析(Sentiment Analysis),接收文本数据,判定文本是正面的、负面的还是中性的等。
- 文本摘要(Text Summarization),接收文本输入并将它们总结为更精炼的文本语言输出。
输入文本的质量会很大程度影响这些业务场景的模型效果。因此,在这些文本数据到达机器翻译、情感分析、文本摘要等下游任务之前,我们要尽量保证输入文本数据的语法正确性。
语法纠错(Grammatical Error Correction)是一个有非常广泛使用的应用场景,有2种典型的模型方法:
- ① 序列到序列(seq2seq)模型:它最早被使用在机器翻译引擎中,将给定语言翻译成同一种语言,这种映射方法同样可以用来做语法纠错(例如Yuan 和 Briscoe,2014)。
- ② 序列标注模型:输入文本被标注然后映射回更正的内容(例如Malmi 等人,2019)。
虽然 seq2seq 神经机器翻译方法已被证明可以实现最先进的性能(例如Vaswani 等人,2017 年),但它仍然存在某些缺点,例如:1)推理和生成输出需要很长时间;2)训练需要大量数据;3)与非神经架构相比,模型的神经架构使得对结果的解释具有挑战性(例如Omelianchuk 等人,2020 年)等。为了克服这些缺点,我们在本文中讨论并应用更新的方法:使用 Transformer 编码器的序列标注器。
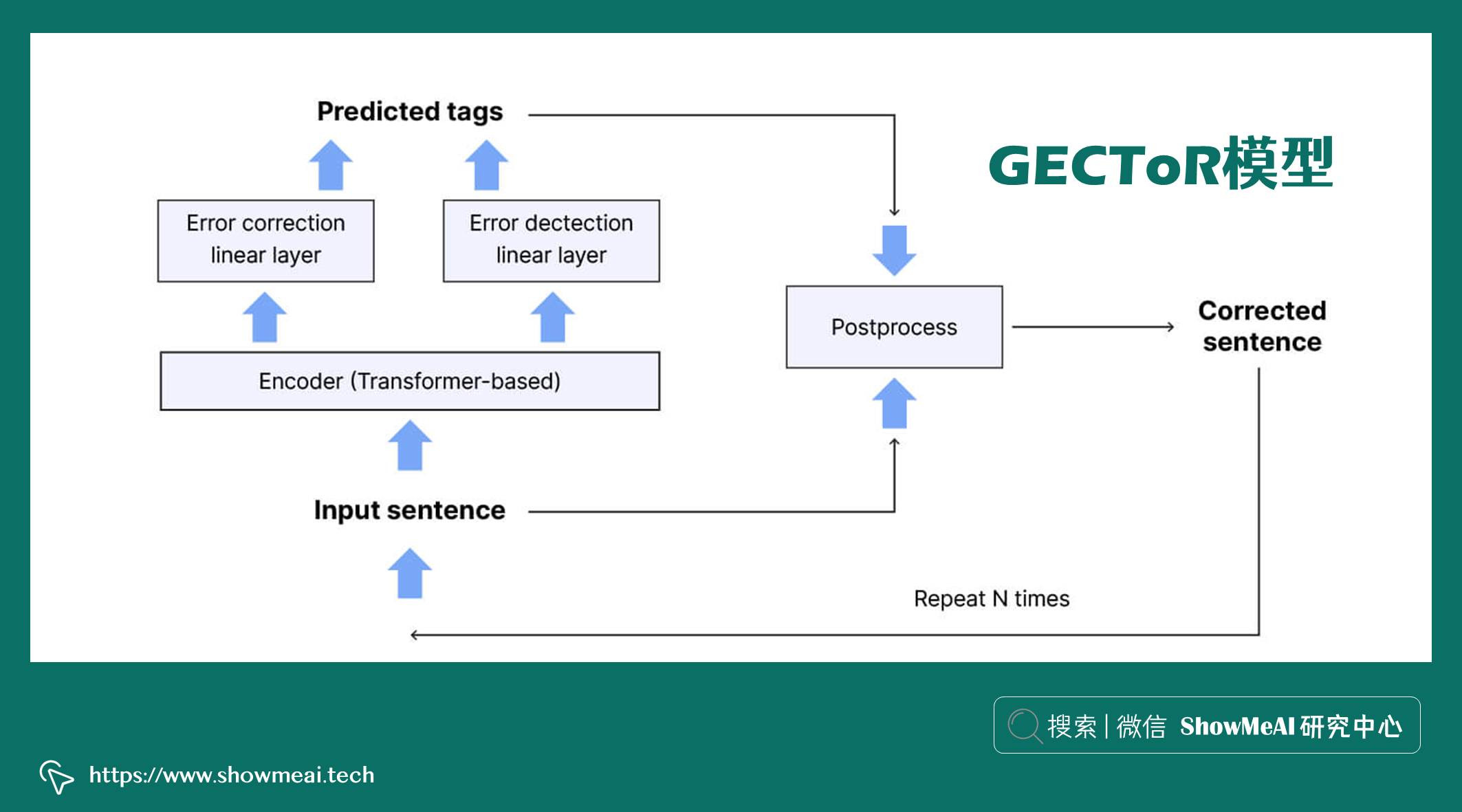
Omelianchuk, et al., 2020中提出的 GECToR 模型,是非常优秀的文本纠错模型。它对 Transformer seq2seq 进行微调,Transformer 的引入极大改善了 seq2seq 模型的推理时间问题,并且可以在较小的训练数据的情况下实现更好的效果。
在后续的内容中,ShowMeAI将演示使用这个库来实现纠正给定句子中语法错误的方案,我们还会创建一个可视化用户界面来将这个AI应用产品化。
语法纠错代码全实现
整个语法纠错代码实现包含3个核心步骤板块:
- 准备工作:此步骤包括工具库设定、下载预训练模型、环境配置。
- 模型实践:实现并测试语法纠错模型。
- 用户界面:创建用户界面以产品化和提高用户体验
准备工作
我们先使用以下命令将 GitHub 中的代码复制到我们本地,这是 GECToR 模型对应的实现:
git clone https://github.com/grammarly/gector.git
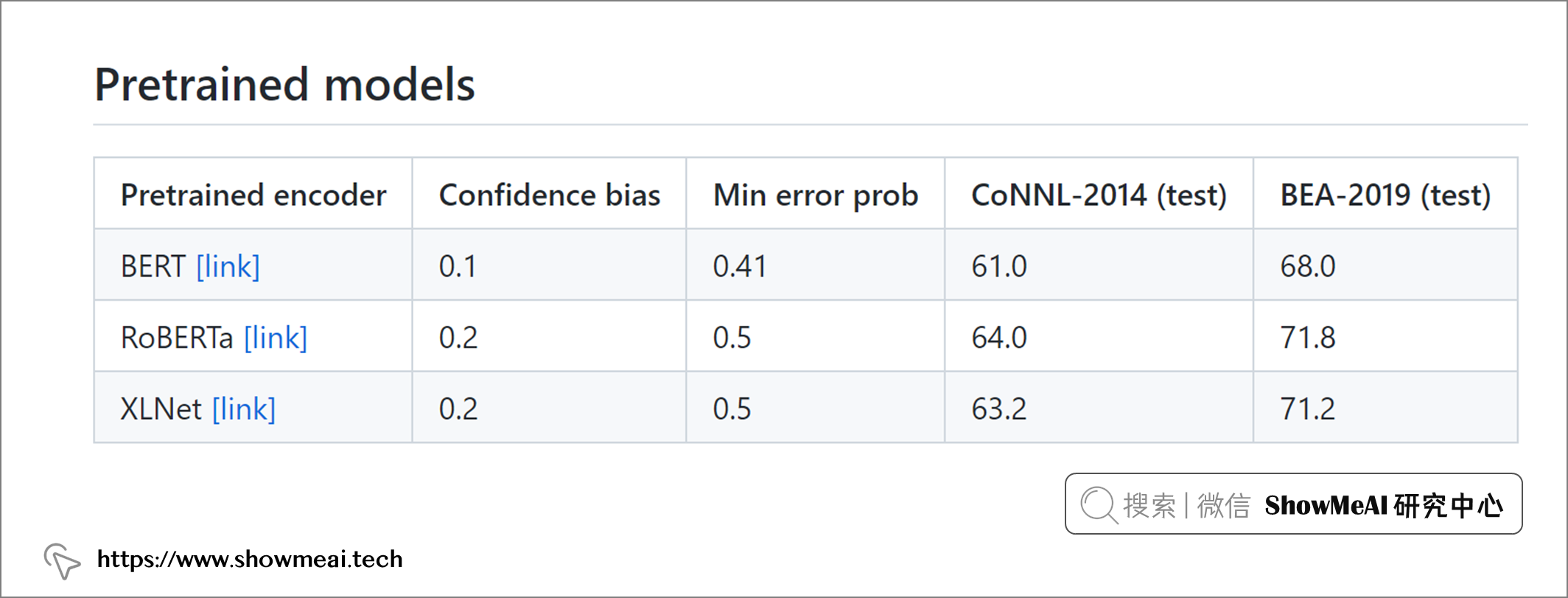
GECToR 提供了3种预训练模型。我们在这里使用 RoBERTa 作为预训练编码器的模型,它在现有模型中具有最高总分最好的表现。我们使用以下命令下载预训练模型:
wget https://grammarly-nlp-data-public.s3.amazonaws.com/gector/roberta_1_gectorv2.th
下载完毕后,我们把下载的模型权重移动到gector目录,以便后续使用:
mv roberta_1_gectorv2.th ./gector/gector
接下来,我们切换到gector文件夹下:
cd ./gector
gector对其他工具库有依赖,因此我们将使用以下命令安装这些依赖:
pip install -r requirements.txt
模型实践
现在我们已经做好所有准备工作了,可以开始使用工具库。总共有下述步骤:
- 导入工具包
- 构建模型实例
- 在有语法错误的句子上测试模型,以查看输出
① she are looking at sky
为此,我们将使用以下句子『she are looking at sky』。
# 导入工具库
from gector.gec_model import GecBERTModel
# 构建模型实例
model = GecBERTModel(vocab_path = "./data/output_vocabulary", model_paths = ["./gector/roberta_1_gectorv2.th"])
# 需要纠错的句子
sent = 'she are looking at sky'
# 存储处理结果
batch = []
batch.append(sent.split())
final_batch, total_updates = model.handle_batch(batch)
updated_sent = " ".join(final_batch[0])
print(f"Original Sentence: {sent}\n")
print(f"Updated Sentence: {updated_sent}")
结果:

模型的纠错结果非常准确!有以下变化:
- 句首将
she大写为She - 将
are更改为is,以使she和is主谓一致 - 在
sky之前添加the - 在句子末尾加句号
.
② she looks at sky yesterday whil brushed her hair
刚才的句子语法比较简单,让我们看看复杂场景,比如混合时态下模型的表现如何。
# 添加复杂句子
sent = 'she looks at sky yesterday whil brushed her hair'
# 存储纠错后的句子
batch = []
batch.append(sent.split())
final_batch, total_updates = model.handle_batch(batch)
updated_sent = " ".join(final_batch[0])
print(f"Original Sentence: {sent}\n")
print(f"Updated Sentence: {updated_sent}")
结果:

在这个句子中我们来看一下纠错模型做了什么:
- 句首将
she大写为She - 将
looks改为looked,与yesterday一致 - 在
sky之前添加the - 将缺失的字母添加到
while - 将
brushed改为brushing,这是while之后的正确格式
不过这里有一点大家要注意,模型的另外一种纠错方式是将yesterday更改为today,对应的时态就不需要用过去式。但这里模型决定使用过去时态。
③ she was looking at sky later today whil brushed her hair
现在让我们再看一个例子:
# 添加复杂句子
sent = 'she was looking at sky later today whil brushed her hair'
# 纠错及存储
batch = []
batch.append(sent.split())
final_batch, total_updates = model.handle_batch(batch)
updated_sent = " ".join(final_batch[0])
print(f"Original Sentence: {sent}\n")
print(f"Updated Sentence: {updated_sent}")
结果:

我们发现了一种边缘情况,在这种情况下,模型无法识别正确的动词时态。更新后的句子是『She was looking at the sky later today while brushing her hair』,我们读下来感觉这句是将来时(今天晚点),而模型纠正后的句子是过去时。
我们想一想,为什么这句对模型比以前更具挑战性呢?答案是later today用两个词暗示时间,这需要模型具有更深层次的上下文意识。如果没有later这个词,我们会有一个完全可以接受的句子,如下所示:

在这种情况下,today可能指的是今天早些时候(即过去),纠错后的语法完全可以接受。但在原始示例中,模型未将later today识别为表示将来时态。
用户界面
在下一步,我们将制作一个web界面,通过用户界面把它产品化并改善用户体验:
# 创建一个函数,对于输入的句子进行语法纠错并返回结果
def correct_grammar(sent):
batch = []
batch.append(sent.split())
final_batch, total_updates = model.handle_batch(batch)
updated_sent = " ".join(final_batch[0])
return updated_sent
我们找一个句子测试这个函数,确保它能正常工作和输出结果。
sent = 'she looks at sky yesterday whil brushed her hair'
print(f"Original Sentence: {sent}\n")
print(f"Updated Sentence: {correct_grammar(sent = sent)}")
结果:

接下来我们将添加一个可视化用户界面。我们使用 Gradio来完成这个环节,它是一个开源 Python 工具库,可以快捷创建 Web 应用程序,如下所示。
# 在命令行运行以安装gradio
pip install gradio
安装Gradio后,我们继续导入和创建用户界面,如下所示:
# 导入Gradio
import gradio as gr
# 构建一个demo实例
demo = gr.Interface(fn = correct_grammar, inputs = gr.Textbox(lines = 1, placeholder = 'Add your sentence here!'), outputs = 'text')
# 启动demo
demo.launch()
结果我们得到如下的界面:
我们可以在 web 界面中再次测试我们的句子啦!我们只需在左侧的框中键入待纠错的句子,然后按 Submit(提交)。接错后的结果将显示在右侧的框中,如下所示:
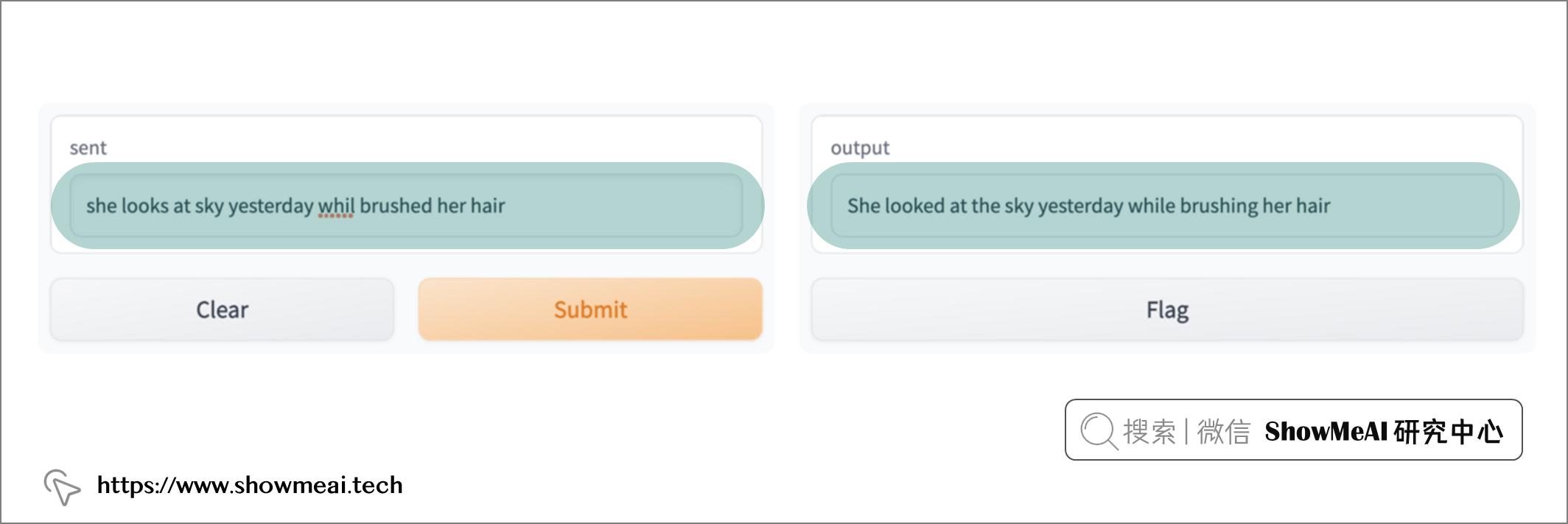
非常顺利,你也快来测试一下吧!
总结
在这篇文章中,我们实践了语法纠错模型。我们使用公开可用的 GECToR 库来实现一个预训练的语法纠错模型,在一些错误的句子上对其进行测试,发现该模型的适用场景和局限性(需要提高的地方),最后我们构建了一个可视化界面把文本纠错产品化。
参考资料
- Grammatical error correction using neural machine translation:https://aclanthology.org/N16-1042/
- Encode, Tag, Realize: High-Precision Text Editing:https://aclanthology.org/D19-1510/
- Attention Is All You Need:https://arxiv.org/abs/1706.03762
- GECToR – Grammatical Error Correction: Tag, Not Rewrite:https://aclanthology.org/2020.bea-1.16/
- GECToR模型的GitHub页面:https://github.com/grammarly/gector
- RoBERTa的GitHub页面:https://github.com/facebookresearch/fairseq/blob/main/examples/roberta/README.md
- Gradio的GitHub页面:https://github.com/gradio-app/gradio
推荐阅读
- 数据分析实战系列 :https://www.showmeai.tech/tutorials/40
- 机器学习数据分析实战系列:https://www.showmeai.tech/tutorials/41
- 深度学习数据分析实战系列:https://www.showmeai.tech/tutorials/42
- TensorFlow数据分析实战系列:https://www.showmeai.tech/tutorials/43
- PyTorch数据分析实战系列:https://www.showmeai.tech/tutorials/44
- NLP实战数据分析实战系列:https://www.showmeai.tech/tutorials/45
- CV实战数据分析实战系列:https://www.showmeai.tech/tutorials/46
NLP实践!文本语法纠错模型实战,搭建你的贴身语法修改小助手 ⛵的更多相关文章
- NLP点滴——文本相似度
[TOC] 前言 在自然语言处理过程中,经常会涉及到如何度量两个文本之间的相似性,我们都知道文本是一种高维的语义空间,如何对其进行抽象分解,从而能够站在数学角度去量化其相似性.而有了文本之间相似性的度 ...
- 「持续集成实践系列」Jenkins 2.x 搭建CI需要掌握的硬核要点
1. 前言 随着互联网软件行业快速发展,为了抢占市场先机,企业不得不持续提高软件的交付效率.特别是现在国内越来越多企业已经在逐步引入DevOps研发模式的变迁,在这些背景催促之下,对于企业研发团队所需 ...
- 基于UML网络教学管理平台模型的搭建
一.基本信息 标题:基于UML网络教学管理平台模型的搭建 时间:2013 出版源:网络安全技术与应用 领域分类:UML:网络教学管理平台:模型 二.研究背景 问题定义:网络教学管理平台模型的搭建 难点 ...
- iOS开发——高级技术精选OC篇&Runtime之字典转模型实战
Runtime之字典转模型实战 如果您还不知道什么是runtime,那么请先看看这几篇文章: http://www.cnblogs.com/iCocos/p/4734687.html http://w ...
- k8s经典实战—搭建WordPress
k8s经典实战—搭建WordPress说明:需要在k8s上部署lnmp环境,建议跟着步骤来端口最好不要改,希望你也能搭建成功,完成这个搭建后你对Kubernetes的技术基本上是入门了.首先看下效果图 ...
- C#并行Parallel编程模型实战技巧手册
一.课程介绍 本次分享课程属于<C#高级编程实战技能开发宝典课程系列>中的一部分,阿笨后续会计划将实际项目中的一些比较实用的关于C#高级编程的技巧分享出来给大家进行学习,不断的收集.整理和 ...
- 【K8S】K8S-网络模型、POD/RC/SVC YAML 语法官方文档
K8S-网络模型.POD/RC/SVC YAML 语法官方文档 Kubernetes - Production-Grade Container Orchestration kubernetes/kub ...
- Runtime之字典转模型实战
Runtime之字典转模型实战 先来看看怎么使用Runtime给模型类赋值 iOS开发中的Runtime可谓是功能强大,同时Runtime使用起来也是非常灵活的,今天博客的内容主要就是使用到一丁点的R ...
- vue+uni-app商城实战 | 第一篇:【有来小店】微信小程序快速开发接入Spring Cloud OAuth2认证中心完成授权登录
一. 前言 本篇通过实战来讲述如何使用uni-app快速进行商城微信小程序的开发以及小程序如何接入后台Spring Cloud微服务. 有来商城 youlai-mall 项目是一套全栈商城系统,技术栈 ...
- 将keras模型在django中应用时出现的小问题——ValueError: Tensor Tensor("dense_2/Softmax:0", shape=(?, 8), dtype=float32) is not an element of this graph.
本文原出处(感谢作者提供):https://zhuanlan.zhihu.com/p/27101000 将keras模型在django中应用时出现的小问题 王岳王院长 10 个月前 keras 一个做 ...
随机推荐
- crictl 命令 - Kubernetes 管理命令详解
描述:crictl 是 CRI 兼容的容器运行时命令行对接客户端, 你可以使用它来检查和调试 Kubernetes 节点上的容器运行时和应用程序.由于该命令是为k8s通过CRI使用containerd ...
- Shell 脚本实践指南
代码风格规范 开头有"蛇棒" 所谓shebang其实就是在很多脚本的第一行出现的以#!开头的注释,他指明了当我们没有指定解释器的时候默认的解释器,一般可能是下面这样: #!/bin ...
- 在k8s中部署前后端分离项目进行访问的两种配置方式
第一种方式 (1) nginx配置中只写前端项目的/根路径配置 前端项目使用的Dockerfile文件内容 把前端项目编译后生成的dist文件夹放在nginx的html默认目录下,浏览器访问前端项目时 ...
- 使用yum方式安装的openresty参数
nginx version: openresty/1.19.3.1 built by gcc 8.3.1 20190311 (Red Hat 8.3.1-3) (GCC) built with Ope ...
- Loki二进制命令帮助
Usage of config-file-loader: -auth.enabled Set to false to disable auth. (default true) -azure.accou ...
- SECS半导体设备通讯-4 GEM通信标准
一 概述 GEM标准定义了通信链路上的半导体设备的行为. SECS-II标准定义了在主机和设备之间交换的消息和相关数据项.GEM标准则定义了在哪种情况下应该使用哪些SECS-II消息以及由此产生的结果 ...
- mysql 判断 字段为空 的一个小误区(又忘了)
今天判断mysql是否为空 直接写某字段 例 image_url !=null 结果数据库不报错误 并且没有返回相对数据. 又忘了这个事.今天特地记录一下. 因为null 表示什么也不是, 不能= ...
- JavaWeb完整案例详细步骤
JavaWeb完整案例详细步骤 废话少说,展示完整案例 代码的业务逻辑图 主要实现功能 基本的CURD.分页查询.条件查询.批量删除 所使用的技术 前端:Vue+Ajax+Elememt-ui 后端: ...
- Teambition企业内部应用开发指南
Teambition企业内部应用Python开发指南 注意:此文章并非搬运,一小部分仅为借鉴. Teambition提供了API接口,我们可以注册成为开发者,然后通过接口获取Teambition的数据 ...
- 【Kubernetes】K8s笔记(十一):Ingress 集群进出流量总管
目录 0. Ingress 解决了什么问题 1. Ingress Controller 2. 指定 Ingress Class 使用多个 Ingress Controller 3. 使用 YAML 描 ...