Python:抓取百度SERP搜索结果页的网站标题信息
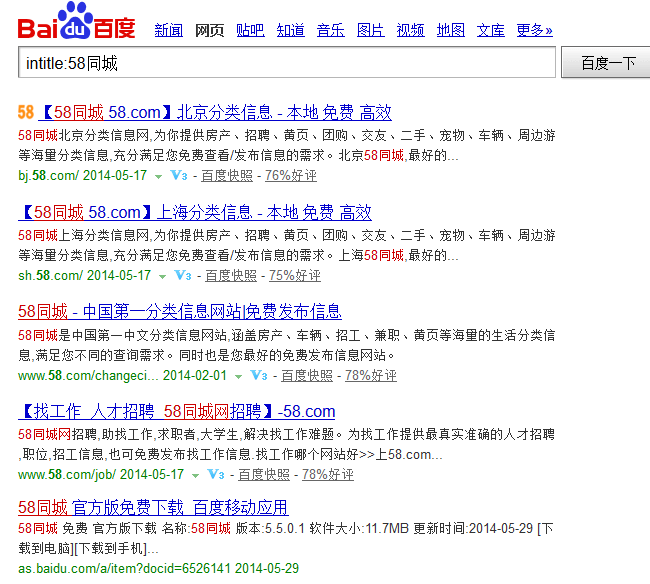
比如,你想采集标题中包含“58同城”的SERP结果,并过滤包含有“北京”或“厦门”等结果数据。
该Python脚本主要是实现以上功能。
其中,使用BeautifulSoup来解析HTML,可以参考我的另外一篇文章:Windows8下安装BeautifulSoup
代码如下:
__author__ = '曾是土木人'
# -*- coding: utf-8 -*-
#采集SERP搜索结果标题
import urllib2
from bs4 import BeautifulSoup
import time
#写文件
def WriteFile(fileName,content):
try:
fp = file(fileName,"a+")
fp.write(content + "\r")
fp.close()
except:
pass #获取Html源码
def GetHtml(url):
try:
req = urllib2.Request(url)
response= urllib2.urlopen(req,None,3)#设置超时时间
data = response.read().decode('utf-8','ignore')
except:pass
return data #提取搜索结果SERP的标题
def FetchTitle(html):
try:
soup = BeautifulSoup(''.join(html))
for i in soup.findAll("h3"):
title = i.text.encode("utf-8")
if any(str_ in title for str_ in ("北京","厦门")):
continue
else:
print title
WriteFile("Result.txt",title)
except:
pass keyword = "58同城"
if __name__ == "__main__":
global keyword
start = time.time()
for i in range(0,8):
url = "http://www.baidu.com/s?wd=intitle:"+keyword+"&rn=100&pn="+str(i*100)
html = GetHtml(url)
FetchTitle(html)
time.sleep(1)
c = time.time() - start
print('程序运行耗时:%0.2f 秒'%(c))
原文地址:曾是土木人
转载请注明出处:http://www.cnblogs.com/hongfei/p/3764181.html
Python:抓取百度SERP搜索结果页的网站标题信息的更多相关文章
- Python爬虫之小试牛刀——使用Python抓取百度街景图像
之前用.Net做过一些自动化爬虫程序,听大牛们说使用python来写爬虫更便捷,按捺不住抽空试了一把,使用Python抓取百度街景影像. 这两天,武汉迎来了一个德国总理默克尔这位大人物,又刷了一把武汉 ...
- Python抓取百度百科数据
前言 本文整理自慕课网<Python开发简单爬虫>,将会记录爬取百度百科"python"词条相关页面的整个过程. 抓取策略 确定目标:确定抓取哪个网站的哪些页面的哪部分 ...
- 使用python抓取百度搜索、百度新闻搜索的关键词个数
由于实验的要求,需要统计一系列的字符串通过百度搜索得到的关键词个数,于是使用python写了一个相关的脚本. 在写这个脚本的过程中遇到了很多的问题,下面会一一道来. ps:我并没有系统地学习过pyth ...
- python抓取百度百科点赞数等动态数据
利用selenium 模拟浏览器打开页面,加载后抓取数据 #!/usr/bin/env python # coding=utf-8 import urllib2 import re from bs4 ...
- Python抓取百度汉字笔画的gif
偶然发现百度汉语里面,有一笔一划的汉字顺序: 觉得这个动态的图片,等以后娃长大了,可以用这个教写字.然后就去找找常用汉字,现代汉语常用字表 .拿到这里面的汉字,做两个数组出来,一共是 ...
- python 抓取百度音乐
# coding:utf-8 import urllib2 import re import urllib import chardet from json import * category = ' ...
- python抓取百度热词
#baidu_hotword.py #get baidu hotword in news.baidu.com import urllib2 import os import re def getHtm ...
- 使用python抓取CSDN关注人的全部公布的文章
# -*- coding: utf-8 -*- """ @author: jiangfuqiang """ import re import ...
- python爬取百度搜索结果ur汇总
写了两篇之后,我觉得关于爬虫,重点还是分析过程 分析些什么呢: 1)首先明确自己要爬取的目标 比如这次我们需要爬取的是使用百度搜索之后所有出来的url结果 2)分析手动进行的获取目标的过程,以便以程序 ...
随机推荐
- best performance / best appearance
- 11-DOM介绍
什么是DOM DOM:文档对象模型.DOM 为文档提供了结构化表示,并定义了如何通过脚本来访问文档结构.目的其实就是为了能让js操作html元素而制定的一个规范. DOM就是由节点组成的. 解析过程 ...
- (转)忘记wamp-mysql数据库root用户密码重置方法
转自:http://www.jb51.net/article/28883.htm 1.打开任务管理器,结束进程 mysqld-nt.exe . 2.运行命令窗口 1)进行php服务管理器安装目录中的 ...
- (转)私有代码存放仓库 BitBucket介绍及入门操作
转自:http://blog.csdn.net/lhb_0531/article/details/8602139 私有代码存放仓库 BitBucket介绍及入门操作 分类: 研发管理2013-02-2 ...
- loadrunner实战篇 - 客户关系管理系统性能测试
系统介绍 图1(客户关系管理系统模块关系图) 需求分析 一.性能指标 性能指标分 ...
- 数据压缩之经典——哈夫曼编码(Huffman)
(笔记图片截图自课程Image and video processing: From Mars to Hollywood with a stop at the hospital的教学视频,使用时请注意 ...
- tarjan算法的补充POJ2533tarjan求度
做题时又遇到了疑惑,说明一开始就没有完全理解 基于dfs的tarjan,搜索时会有四种边 树枝边:DFS 时经过的边,即 DFS 搜索树上的边 前向边:与 DFS 方向一致,从某个结点指向其某个子孙的 ...
- DXP 板层
一)DXP-设置板层(D+K )在PCB编辑 Design->Layer Stack Manager(层管理) 1)快捷命令 D + K 进入么多层置管理器 2.鼠标右键 TopLayer- ...
- Delphi IDHTTP控件:GET/POST 请求
Delphi IDHTTP控件:GET/POST 请求 最近一直在使用IDHTTP,下面是一些关于 GET.POST 请求基本使用方法的代码 一.GET 请求 1 procedure GetDem ...
- 实验6 LCD接口
1.利用单片机控制LCD1602,在LCD1602上显示字符串,并使其整屏左移. #include<reg51.h> #define uchar unsigned char #define ...