cloudera-hdfs 告警处理
2018-03-13 11:15:17,215 WARN [org.apache.flume.sink.hdfs.HDFSEventSink] - HDFS IO error
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.StandbyException): Operation category WRITE is not supported in state standby
at org.apache.hadoop.hdfs.server.namenode.ha.StandbyState.checkOperation(StandbyState.java:87)
at org.apache.hadoop.hdfs.server.namenode.NameNode$NameNodeHAContext.checkOperation(NameNode.java:1754)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkOperation(FSNamesystem.java:1337)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2492)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFile(FSNamesystem.java:2446)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.create(NameNodeRpcServer.java:566)
at org.apache.hadoop.hdfs.server.namenode.AuthorizationProviderProxyClientProtocol.create(AuthorizationProviderProxyClientProtocol.java:108)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.create(ClientNamenodeProtocolServerSideTranslatorPB.java:388)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:587)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1026)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2013)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2009)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1678)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2007) at org.apache.hadoop.ipc.Client.call(Client.java:1411)
at org.apache.hadoop.ipc.Client.call(Client.java:1364)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:206)
at com.sun.proxy.$Proxy14.create(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy14.create(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.create(ClientNamenodeProtocolTranslatorPB.java:264)
at org.apache.hadoop.hdfs.DFSOutputStream.newStreamForCreate(DFSOutputStream.java:1612)
at org.apache.hadoop.hdfs.DFSClient.create(DFSClient.java:1488)
at org.apache.hadoop.hdfs.DFSClient.create(DFSClient.java:1413)
at org.apache.hadoop.hdfs.DistributedFileSystem$6.doCall(DistributedFileSystem.java:387)
at org.apache.hadoop.hdfs.DistributedFileSystem$6.doCall(DistributedFileSystem.java:383)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.create(DistributedFileSystem.java:383)
at org.apache.hadoop.hdfs.DistributedFileSystem.create(DistributedFileSystem.java:327)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:906)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:887)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:784)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:773)
at org.apache.flume.sink.hdfs.HDFSDataStream.doOpen(HDFSDataStream.java:86)
at org.apache.flume.sink.hdfs.HDFSDataStream.open(HDFSDataStream.java:113)
at org.apache.flume.sink.hdfs.BucketWriter$1.call(BucketWriter.java:273)
at org.apache.flume.sink.hdfs.BucketWriter$1.call(BucketWriter.java:262)
at org.apache.flume.sink.hdfs.BucketWriter$9$1.run(BucketWriter.java:722)
at org.apache.flume.sink.hdfs.BucketWriter.runPrivileged(BucketWriter.java:183)
at org.apache.flume.sink.hdfs.BucketWriter.access$1700(BucketWriter.java:59)
at org.apache.flume.sink.hdfs.BucketWriter$9.call(BucketWriter.java:719)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
查看hadoop源码:
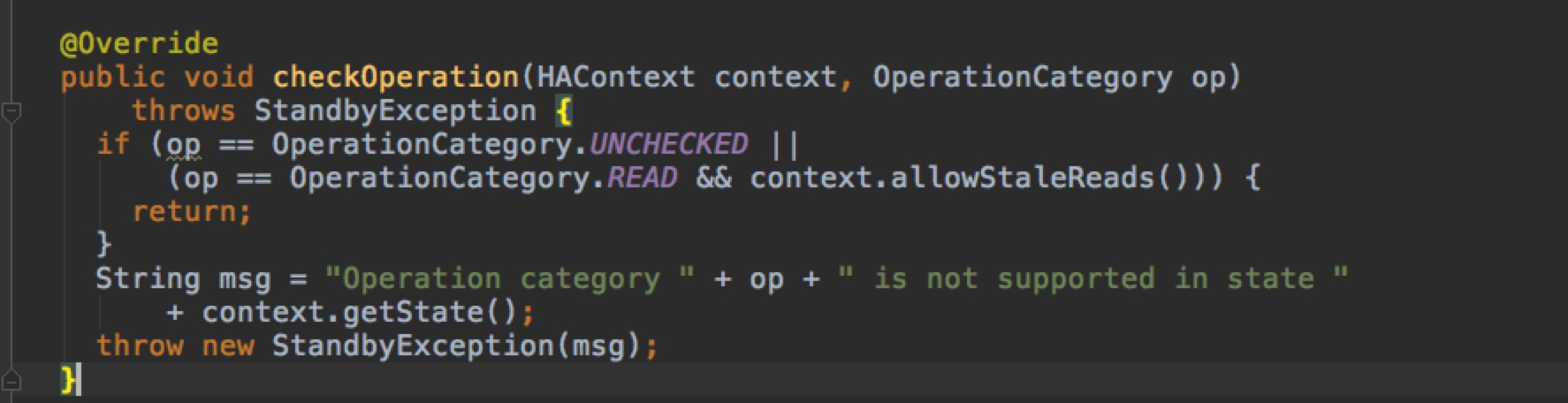

发些是写HDFS 无法写入权限,空间不足引起
参考:http://blog.csdn.net/xueyao0201/article/details/79530130
cloudera-hdfs 告警处理的更多相关文章
- Cloudera Certified Associate Administrator案例之Configure篇
Cloudera Certified Associate Administrator案例之Configure篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.下载CDH集群中最 ...
- 大数据平台R语言web UI应用架构 设计与开发
1. 系统拓扑图 在日常业务分析中,R是非常常用的分析工具,而当数据量较大时,用R语言需要需用更多的时间来完成训练模型,spark作为大规模数据处理框架,采用内存计算,可以短时间内完成大量的数据的处理 ...
- namenode No valid image files
1,角色日志报错 Encountered exception loading fsimage java.io.FileNotFoundException: No valid image files f ...
- 即将上线的Spark服务器面临的一系列填坑笔记
即将上线的Spark服务器面临的一系列填坑笔记 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 把kafka和flume倒腾玩了,以为可以轻松一段时间了,没想到使用CDH部署的spa ...
- Impala SQL 语言元素(翻译)[转载]
原 Impala SQL 语言元素(翻译) 本文来源于http://my.oschina.net/weiqingbin/blog/189413#OSC_h2_2 摘要 http://www.cloud ...
- Impala SQL 语言元素(翻译)
摘要: http://www.cloudera.com/content/cloudera-content/cloudera-docs/Impala/latest/Installing-and-Usin ...
- 报错:Error, CM server guid updated, expected xxxxx, received xxxxx (未解决)
报错背景: CDH断电重启后,cloudera-scm-server启动报错, cloudera-scm-server 已死,但 pid 文件仍存 由于没有成熟的解决方案,于是我就重新安装了MySQL ...
- 安装CDH5.11.2集群
master 192.168.1.30 saver1 192.168.1.40 saver2 192.168.1.50 首先,时间同步 然后,ssh互通 接下来开始: 1.安装MySQL5.6. ...
- 使用Cloudera Manager搭建HDFS完全分布式集群
使用Cloudera Manager搭建HDFS完全分布式集群 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 关于Cloudera Manager的搭建我这里就不再赘述了,可以参考 ...
- Problem of Uninstall Cloudera: Can't Add Hdfs and Reported Cannot Find CDH's bigtop-detect-javahome
[toc] 1. Problem We wrote a shell script to uninstall Cloudera Manager(CM) that run in a cluster wit ...
随机推荐
- mui 常用手势
一 事件: 点击:1. tap 单击屏幕2. doubletap 双击屏幕长按:1. longtap 长按屏幕2. hold 按住屏幕3.release 离开屏幕滑动:1. swipeleft 向左滑 ...
- 学习别人的rpc框架
https://my.oschina.net/huangyong/blog/361751 https://gitee.com/huangyong/rpc 在此文基础上的另一个实现,解决了原文中一些问题 ...
- linux终端发送邮件
使用mail: echo "This is message to send" | mail -a /tmp/attachment.txt -s "This is Subj ...
- vim主题设定
Vim的颜色主题在/usr/share/vim/vim74/colors文件夹里. 打开vim后在normal模式下输入“:colorscheme”查看当前的主题,修改主题使用命令“:colorsch ...
- PHP对redis操作详解
/*1.Connection*/$redis = new Redis();$redis->connect('127.0.0.1',6379,1);//短链接,本地host,端口为6379,超过1 ...
- springboot 项目 注意事项
SpringBoot出现下列错误. Your ApplicationContext is unlikely to start due to a @ComponentScan of the defaul ...
- 深入jUI(DWZ)
-----------------------------------------------------------------------------主页面index.html <html& ...
- 25. IO流.md
目录 IO分类: 1.FIle类 1.1目录分隔符 1.2常用方法 2.FileInputStream类 2.1读取文件 3.FileOutputStream类 拷贝文件 4.缓冲流 4.1 Buff ...
- ArcMap导入图层出现General function failure问题 [转]
ArcMap导入图层出现General function failure问题 [转] Link: http://www.cnblogs.com/angelx/p/3391967.html 问题描述 ...
- redmine安装-BitNami 提供的一键安装程序
redmine安装-BitNami 提供的一键安装程序 博客分类: REDMINE redmine安装redmine一键安装bitNami redmine BitNami 提供re ...