HanLP用户自定义词典源码分析详解
1. 官方文档及参考链接
l 关于词典问题Issue,首先参考:FAQ
l 自定义词典其实是基于规则的分词,它的用法参考这个issue
l 如果有些数量词、字母词需要分词,可参考:P2P和C2C这种词没有分出来,希望加到主词库
l 关于词性标注:可参考词性标注
2. 源码解析
分析 com.hankcs.demo包下的DemoCustomDictionary.java 基于自定义词典使用标准分词HanLP.segment(text)的大致流程(HanLP版本1.5.3)。首先把自定义词添加到词库中:
CustomDictionary.add("攻城狮");
CustomDictionary.insert("白富美", "nz 1024");//指定了自定义词的词性和词频
CustomDictionary.add("单身狗", "nz 1024 n 1")//一个词可以有多个词性
添加词库的过程包括:
l 若启用了归一化HanLP.Config.Normalization = true;,则会将自定义词进行归一化操作。归一化操作是基于词典文件 CharTable.txt 进行的。
l 判断自定义词是否存在于自定义核心词典中
public static boolean add(String word)
{
if (HanLP.Config.Normalization) word = CharTable.convert(word);
if (contains(word)) return false;//判断DoubleArrayTrie和BinTrie是否已经存在word
return insert(word, null);
}
l 当自定义词不在词典中时,构造一个CoreDictionary.Attribute对象,若添加的自定义词未指定词性和词频,则词性默认为 nz,频次为1。然后试图使用DAT树将该 Attribute对象添加到核心词典中,由于我们自定义的词未存在于核心词典中,因为会添加失败,从而将自定义词放入到BinTrie中。因此,不在核心自定义词典中的词(动态增删的那些词语)是使用BinTrie树保存的。
public static boolean insert(String word, String natureWithFrequency)
{
if (word == null) return false;
if (HanLP.Config.Normalization) word = CharTable.convert(word);
CoreDictionary.Attribute att = natureWithFrequency == null ? new CoreDictionary.Attribute(Nature.nz, 1) : CoreDictionary.Attribute.create(natureWithFrequency);
if (att == null) return false;
if (dat.set(word, att)) return true;
//"攻城狮"是动态加入的词语. 在核心词典中未匹配到,在自定义词典中也未匹配到, 动态增删的词语使用BinTrie保存
if (trie == null) trie = new BinTrie<CoreDictionary.Attribute>();
trie.put(word, att);
return true;
}
将自定义添加到BinTrie树后,接下来是使用分词算法分词了。假设使用的标准分词(viterbi算法来分词):
List<Vertex> vertexList = viterbi(wordNetAll);
分词具体过程可参考:
分词完成之后,返回的是一个 Vertex 列表。如下图所示:
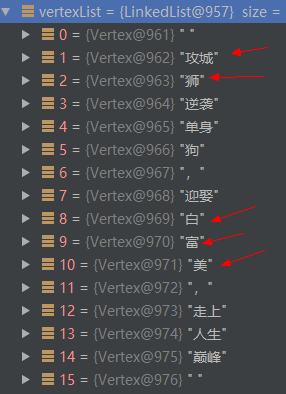
然后根据 是否开启用户自定义词典 配置来决定将分词结果与用户添加的自定义词进行合并。默认情况下,config.useCustomDictionary是true,即开启用户自定义词典。
if (config.useCustomDictionary)
{
if (config.indexMode > 0)
combineByCustomDictionary(vertexList, wordNetAll);
else combineByCustomDictionary(vertexList);
}
combineByCustomDictionary(vertexList)由两个过程组成:
l 合并DAT 树中的用户自定义词。这些词是从 词典配置文件 CustomDictionary.txt 中加载得到的。
l 合并BinTrie 树中的用户自定义词。这些词是 代码中动态添加的:CustomDictionary.add("攻城狮")
//DAT合并
DoubleArrayTrie<CoreDictionary.Attribute> dat = CustomDictionary.dat;
....
// BinTrie合并
if (CustomDictionary.trie != null)//用户通过CustomDictionary.add("攻城狮"); 动态增加了词典
{
....
合并之后的结果如下:

3. 关于用户自定义词典
总结一下,开启自定义分词的流程基本如下:
l HanLP启动时加载词典文件中的CustomDictionary.txt 到DoubleArrayTrie中;用户通过 CustomDictionary.add("攻城狮");将自定义词添加到BinTrie中。
l 使用某一种分词算法分词
l 将分词结果与DoubleArrayTrie或BinTrie中的自定义词进行合并,最终返回输出结果
HanLP作者在HanLP issue783:上面说:词典不等于分词、分词不等于自然语言处理;推荐使用语料而不是词典去修正统计模型。由于分词算法不能将一些“特定领域”的句子分词正确,于是为了纠正分词结果,把想要的分词结果添加到自定义词库中,但最好使用语料来纠正分词的结果。另外,作者还说了在以后版本中不保证继续支持动态添加自定义词典。以上是阅读源码过程中的一些粗浅理解,仅供参考。
文章转载自hapjin 的博客
HanLP用户自定义词典源码分析详解的更多相关文章
- HanLP用户自定义词典源码分析
HanLP用户自定义词典源码分析 1. 官方文档及参考链接 关于词典问题Issue,首先参考:FAQ 自定义词典其实是基于规则的分词,它的用法参考这个issue 如果有些数量词.字母词需要分词,可参考 ...
- 对javaEE Tutorial上hello2的源码分析详解
首先: java EE 上的hello2项目是一个部署在glass fish上的开发源码的java web项目,在终端通过命令行使用maven进行打包成.war文件,最后部署到相关的glass fis ...
- Nop--NopCommerce源码架构详解专题目录
最近在研究外国优秀的ASP.NET mvc电子商务网站系统NopCommerce源码架构.这个系统无论是代码组织结构.思想及分层都值得我们学习.对于没有一定开发经验的人要完全搞懂这个源码还是有一定的难 ...
- Hadoop3.1.1源码Client详解 : 入队前数据写入
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 紧接着上一篇: Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立 先给出 ...
- Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之DataStreamer(Packet发送) : 主干
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 在上一章(Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立) 我们提到, ...
- Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之ResponseProcessor(ACK接收)
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 紧接着上一篇文章: Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之D ...
- NopCommerce源码架构详解--初识高性能的开源商城系统cms
很多人都说通过阅读.学习大神们高质量的代码是提高自己技术能力最快的方式之一.我觉得通过阅读NopCommerce的源码,可以从中学习很多企业系统.软件开发的规范和一些新的技术.技巧,可以快速地提高我们 ...
- NopCommerce源码架构详解
NopCommerce源码架构详解--初识高性能的开源商城系统cms 很多人都说通过阅读.学习大神们高质量的代码是提高自己技术能力最快的方式之一.我觉得通过阅读NopCommerce的源码,可以从 ...
- Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览
一.设计原理 1.Hadoop架构: 流水线(PipeLine) 2.Hadoop架构: HDFS中数据块的状态及其切换过程,GS与BGS 3.Hadoop架构: 关于Recovery (Lease ...
随机推荐
- 5-log4j2.xml配置文件各个节点详解
具体配置参考官网:http://logging.apache.org/log4j/2.x/manual/configuration.html 一.log.xml文件的大致结构 <?xml ver ...
- linux列出目录下所有目录
我的一个目录下有很多文件,但是我想列出该目录下所有的目录,并且删除 列出目录下所有的目录,常用的方法是ll配合管道命令,比如 ll | grep "^d" 通过对ll命令的输出,抓 ...
- SSH升级到7.7
#!/bin/bash#删除旧版ssh包 危险操作,不删除也可以安装,建议跳过此操作.#rpm -e `rpm -qa | grep openssh` #安装zlib依赖包wget -c http:/ ...
- centos7 firewalld基本使用
firewalld的基本使用 启动: systemctl start firewalld 查看状态: systemctl status firewalld 停止: systemctl disable ...
- BZOJ 5099: Pionek(双指针)(占位)
pro:有N个向量,你可以选择一些向量,使得其向量和离原点最远. 输出这个欧几里得距离的平方. sol:(感觉网上的证明都不是很充分,我自己也是半信半疑吧)日后证明了再补. #include<b ...
- PS学习之如何把小姐姐塞进瓶子里
准备素材 开始制作 用PS新建一个国际通用纸张大小的画布 分辨率可以调为72 改变背景色 插入图片 水平居中对齐 插入木质素材 放大 覆盖之前的素材 调整图层顺序 创建剪切蒙版 对木桩添加曲线 设置立 ...
- hdu4338 Simple Path
Everybody knows that totalfrank has absolutely no sense of direction. Getting lost in the university ...
- hdu1542 Atlantis 线段树--扫描线求面积并
There are several ancient Greek texts that contain descriptions of the fabled island Atlantis. Some ...
- AangularJS过滤器详解
(参考angular权威指南) 过滤器: 用来格式化需要展示给用户的数据: 使用过滤器的方式: (1)$scope.name=$filter("lowercase").(&qu ...
- mysql给数据库授权与收回权限--------dcl
用户授权语法 grant 权限1,权限2... on 数据库名.* to 用户名 @IP地址或% 打开新创建的名为“test”的数据库后 用 show databases; 的命令 看内部的数据结果 ...