centos 安装elk监控
下面就是要安装一些收集日志 或者分配日志的工具,我选择的是 Filebeat 来收集日志,然后放到kafka中 让kafka这个消息队列来分配生产者消费者 然后通过Logstash 或者一个国产大神的 gohangout (及其节省性能) 来提取日志信息 然后放到es中 然后通过kibana 来展示数据信息
elk可以理解为是一套组件这个组件是帮助我们解决日志收集的信息 其中的
es:Elasticsearch 是用来存放收集来的日志信息的 也就是一个日志存放容器,
Kibana 是用来存放更好的展示数据信息的 更直观的展示
beats 和 logstash 是用来收集日志信息 然后发送到es中 ,但是logstash消耗特别厉害吃性能,但是可以做分词之类的过滤展示
整天流程图就是 :

下面的收集 收集完成之后给es 展示 但是有时候信息量大的时候 需要加上个消息队列来进行使用 不然就会造成日志信息量过大而宕机
centos7安装es:
首先es这些组件是以来java环境的, java 开发的开源的全文搜索引擎工具 ,所以我们要现在服务器上安装jdk环境:https://www.cnblogs.com/zhaoyunlong/p/10521326.html
然后再下载es :地址 https://www.elastic.co/downloads/

然后解压进行配置:
centos7
centos7的配置还和ccentos6的配置是不一样的
首先下载然后上传 到你的安装目录 然后解压:

首先要进行用户的创建 ,因为es是不被允许是root用户打开的,然后创建用户并且赋予他操作es的权限
创建用:useradd
useradd www # 创建一个www用户 然后给与权限
chown -R www:www es文件
然后进入es中的config目录下进行配置

配置elasticsearch.yml中的信息
cluster.name: my-application # 你的 集群名字
node.name: node-1 # es 名字 path.data: /data/opt/es # 数据存放额目录 path.logs: /data/opt/es # 日志存放的目录 bootstrap.memory_lock: true network.host: 0.0.0.0 # 修改为都可以连接
http.port: 9200端口号

上面有些信息是被隐去的要自己去打开,目录什么的要自己设置 ,其中的存放信息的目录必须要先创建好 不然会报错
centos6
如果是centos6 版本的配置就要加上这两个:
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
然后把 默认的 bootstrap.memory_lock: true 继续注释
然后 配置 jvm.options
默认的是centos6的配置是4g的可能内存太大 容易溢出就设置为2 或者1
-Xms2g
-Xmx2g
下面就要修改你的默认的配置文件中心:
vim /etc/sysctl.conf #单个JVM下支撑的线程数(也可以不进行配置)
vim /etc/security/limits.conf
vim /etc/security/limits.d/20-nproc.conf
配置 /etc/sysctl.conf
vm.max_map_count=262144 #单个JVM下支撑的线程数数量就是262144
然后配置:/etc/security/limits.conf
这是设置 用户所有进程能打开的最大文件数量,oft nofile表示软限制,hard nofile表示硬限制,软限制要小于等于硬限制
* soft nofile
* hard nofile
www soft memlock unlimited # www是我建立的用户 这是内存锁无限制
www hard memlock unlimited # www是建立的用户 硬盘锁无限制
然后修改: (其实也不用修改centos7默认的就是一下的配置)
* soft nproc
root soft nproc unlimited
以上的三个配置centos7只需要修改第二个就可以 一般的,然后再切换到你新建立的www用户
然后到es下的bin目录输入
./elasticsearch -d
就能启动了,然后看看你的进程是否有
ps -ef | grep java
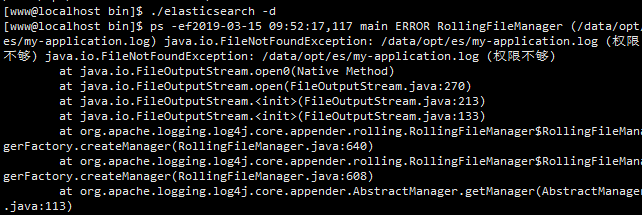
如果没有就去你的日志指定的目录下,我的是在/data/opt/es下
如果没有启动就去查看报错日志 查看日志信息 才启动就去 my-application.log 查看信息日志

因为我的日志和数据指向是同一个文件 所以modes就是我的数据的存放
记住一定不能用root用户启动,因为es默认的不能用root启动
启动就会报错:

启动没有反应久先去my-application.log 中去查看日志信息
并且还要给es的目录赋予你启动的非root用户操作权限
不然还会报错:Exception in thread "main" java.nio.file.AccessDeniedException:

如果报错:
[o.e.b.Bootstrap ] [node-1] node validation exception
[1] bootstrap checks failed
[1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
这个就是你的配置elasticsearch.yml中的信息 出问题
需要调试
#bootstrap.memory_lock: true bootstrap.system_call_filter: false # 这两个和上面的一个 bootstrap.memory_lock: true 随时切换 bootstrap.memory_lock: false
记住随时查看你的保存的日志信息来看错误日志 就可以解决
linux查看所有用户:
cut -d : -f /etc/passwd
然后给与你的操作用户赋予操作权限:
chown + R 用户名:用户名 +文件名
启动成功的标志:
然后在在浏览器中输入服务器ip和启动端口就可以访问你的es信息了 如果启动了不能访问信息就是你的防火墙的事情了
centos7关闭防防火墙:
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
安装kafka消息队列:
安装kafka的之前你要先安装zookeeper 因为kafka是以来zookeeper来运行的
安装zookeeper
下载 http://mirror.bit.edu.cn/apache/zookeeper/
然后解压之后就去进行配置 进入config中 配置信息的值
执行:
cp zoo_sample.cfg zoo.cfg
 zook.cfg的配置信息如下:
zook.cfg的配置信息如下:
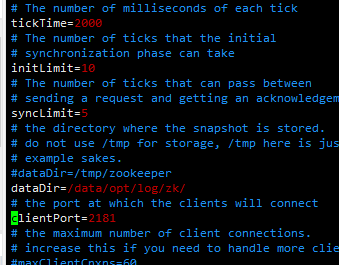
基本上都是默认的配置信息(信息内不可以有汉字不然启动不成功)
tickTime=
initLimit=
syncLimit=
dataDir=/tmp/zookeeper # 日志存放的目录(中文不可以加入里面)
clientPort= # 启动的端口
然后进入bin目录下启动:
./zkServer.sh start # 启动
./zkServer.sh restart # 重启
当显示如下就是启动成功

然后查看启动情况:
./zkServer.sh status
然后安装kafka
kafka是一个消息队列和rabbitmq 一样都是消息队列,它是一种高吞吐量的分布式发布订阅消息系统,以可水平扩展和高吞吐率而被广泛使用
首先 下载kafka:https://kafka.apache.org/downloads
还可以直接wget来下载 :wget https://www.apache.org/dyn/closer.cgi?path=/kafka/2.1.1/kafka_2.11-2.1.1.tgz
然后解压完成之后久开始配置信息:
切换到你解压的kafka目录下de config进行信息的配置,

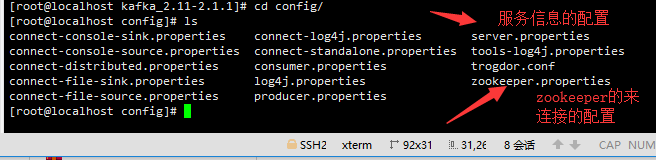
这两个配置信息是很重要的, 然后进入server.properties 来进行服务信息的配置
里面的信息都是默认的 一般只需要修改 listeners 就是监听的端口号
listeners=PLAINTEXT://localhost:9092
listeners=PLAINTEXT://:9092 # 默认的信息是这样
加上localhost是代表监听的端口就是我们本机的9092 的配置
然后其他的大部分都是默认的信息:
broker.id= listeners=PLAINTEXT://localhost:9092 # 一般只需要修改这一个就可以 加上监听的端口是哪个位置的 num.network.threads=
num.io.threads= socket.send.buffer.bytes=
socket.receive.buffer.bytes= socket.request.max.bytes=
log.dirs=/tmp/kafka-logs # 放置的信息的位置 num.partitions=
然后zookeeper.properties 的配置如果你上面的zookeeper的性能是没有改变的时候就可以直接使用默认的,如果改变久修改默认的配置信息值
然后 你还要使用topic来进行你的分区的盘的设置 kafka的topic就相当于是kafka的盘符 你的 信息日志收集来久灌溉到kafka中
创建topic:
首先要先进入kafka目录下的 bin目录下执行语句 ./kafka-topics.sh --create --zookeeper localhost: --replication-factor --partitions 3 --topic test_kafka
./kafka-topics.sh --create --zookeeper 地址:端口 --replication-factor 分区数 --partitions 消费者数 --topic test_kafka
partitions指定topic分区数,replication-factor指定topic每个分区的副本数(可以理解为replication-factor是有多少个消费者,这个时候我创建了三个 也就是最多每次只能有三个消费者来取数据),然后你收集来的数据就可以灌输到分区中然后消费者来取数据
kafka的启动:
进入kafk下的bin 目录下然后制定配置文件 要制定绝对路径
./kafka-server-start.sh /data/opt/kafka_2.-2.1./config/server.properties &
./kafka-server-start.sh 安装kafka路径下的config/server.properties &
安装filebeat收集日志信息:
filebeat下载;https://www.elastic.co/downloads/beats
解压之后进入目录在目录下有一个文件:filebeat.yml

然后配置信息:
添加配置到kafka的信息:
#================================ Outputs =====================================
output.kafka:
enabled: true
hosts: ["localhost:9092"]
topic: test
并且注释掉默认的送到es内的信息 因为是发送到kafka的:
# 注释掉 #-------------------------- Elasticsearch output ------------------------------
#output.elasticsearch:
# Array of hosts to connect to.
# hosts: ["localhost:9200"]
然后HIA可以自己在进入的时候修改你的收集日志存放的目录 paths
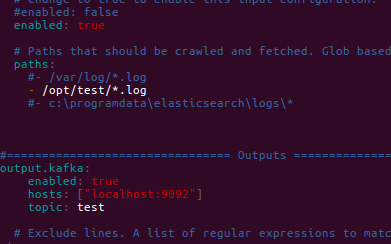
然后就可以启动filebeat收集日志信息了
然后启动你的filebeat 指定你的刚才的配置信息
./filebeat -e -c filebeat.yml
然后你的filebeat就启动了
安装kafkakmanage
安装kafkamanage用来管理你的kafka
下载地址github: https://github.com/yahoo/kafka-manager
然后解压
centos 安装elk监控的更多相关文章
- centos 安装cacti监控
CentOS 6下Cacti搭建文档 安装依赖关系 yum -y install mysql-devel httpd php php-pdo php-snmp php-mysql lm_sensors ...
- centos 安装ELK
准备安装环境 由于本人的centos是通过虚拟机来进行安装的,为了本地电脑能够访问centos系统中的端口,则需要把防火墙进行关闭,通过以下方式进行关闭防火墙. # vi /etc/sysconfig ...
- centos安装zabbix监控服务器端
首先安装zabbx 依赖yum install net-snmp-devel libxml2-devel libcurl-devel -y 下载zabbix 源码包wget https://ncu.d ...
- centos安装流量监控软件,并指定端口号监控
yum install -y iptraf 安装好以后使用进入界面: iptraf-ng enter回车,比如22端口,就是22 22 然后退出 重新登录 ok!
- Centos安装流量监控工具iftop笔记
Centos安装流量监控工具iftop笔记 一.概述 iftop可以用来监控网卡的实时流量(可以指定网段).反向解析IP.显示端口信息等,详细的将会在后面的使用参数中说明.官方网站:http://ww ...
- CentOS 7.x安装ELK(Elasticsearch+Logstash+Kibana)
第一次听到ELK,是新浪的@ARGV 介绍内部使用ELK的情况和场景,当时触动很大,原来有那么方便的方式来收集日志和展现,有了这样的工具,你干完坏事,删除日志,就已经没啥作用了. 很多企业都表示出他们 ...
- 如何在CentOS 7 / Fedora 31/30/29上安装ELK Stack
原文地址:https://computingforgeeks.com/how-to-install-elk-stack-on-centos-fedora/ 原作者: Josphat Mutai 译者: ...
- 虚拟机创建及安装ELK
虚拟机创建及安装ELK 作者:高波 归档:学习笔记 2018年5月31日 13:57:02 快捷键: Ctrl + 1 标题1 Ctrl + 2 标题2 Ctrl + 3 标题3 C ...
- Windows 安装ELK
在Windows服务器上安装ELK logstash在windows平台下不能监控磁盘文件,用nxlog代替,监控文件并把内容发送到logstash 部署环境 Os :Windows 7 logsta ...
随机推荐
- springboot-28-security(一)用户角色控制
spring security 使用众多的拦截器实现权限控制的, 其核心有2个重要的概念: 认证(Authentication) 和授权 (Authorization)), 认证就是确认用户可以访问当 ...
- Undo日志文件的产生和使用
Undo 日志 比如A有200块钱, B有50 块钱,现在A要给B转100块” . (1) 开始事务 T1 (假设T1是个事务的内部编号) (2) A余额 = A余额 -100 (3) B余额 ...
- SkipList 跳跃表
引子 考虑一个有序表:14->->34->->50->->66->72 从该有序表中搜索元素 < 23, 43, 59 > ,需要比较的次数分别为 ...
- ASP.NET MVC HtmlHelper 类的扩展方法
再ASP.NET MVC编程中用到了R语法,在View页面编辑HTML标签的时候,ASP.NET MVC 为我们准备好了可以辅助我们写这些标签的办法,它们就是HtmlHelper.微软官方地址是:ht ...
- core Animation之CAKeyframeAnimation(关键帧动画)
CABasicAnimation的区别是:CABasicAnimation只能从一个数值(fromValue)变到另一个数值(toValue),而CAKeyframeAnimation会使用一个NSA ...
- nodejs的__dirname,__filename,process.cwd()区别
假定我们有这样一个mynode的node项目在User/leinov/porject/文件夹下,cli是一个可执行文件 |-- mynode |-- bin |-- cli.js |-- src |- ...
- Jquery插件的使用及制作插件
常用插件 插件:jquery不可能包含所有的功能,我们可以通过插件扩展jquery的功能. jQuery有着丰富的插件,使用这些插件能给jQuery提供一些额外的功能. jquery.color.js ...
- IDEA中上传项目到GIt
一.先创建一个git仓库 二.然后在右键项目pull 三.add 最后提交: 完成
- 过滤器模式(Filter Pattern)
过滤器模式 一.什么是过滤器模式 过滤器模式(Filter Pattern),这种模式允许开发人员使用不同的标准来过滤一组对象,通过逻辑运算以解耦的方式把它们连接起来.这种类型的设计模式属于结构型 ...
- hdu 1568 (log取对数 / Fib数通项公式)
hdu 1568 (log取对数 / Fib数通项公式) 2007年到来了.经过2006年一年的修炼,数学神童zouyu终于把0到100000000的Fibonacci数列 (f[0]=0,f[1]= ...