tachyon of zybo cluster
把Tachyon层加入spark和hadoop之间,以加速集群
官网:http://tachyon-project.org/
github:https://github.com/amplab/tachyon/releases
(1)准备工作:
wget http://tachyon-project.org/downloads/tachyon-0.4.1-bin.tar.gz
tar xvfz tachyon-0.4.1-bin.tar.gz
cd tachyon-0.4.1
cp conf/tachyon-env.sh.template conf/tachyon-env.sh
(2)在本地测试:
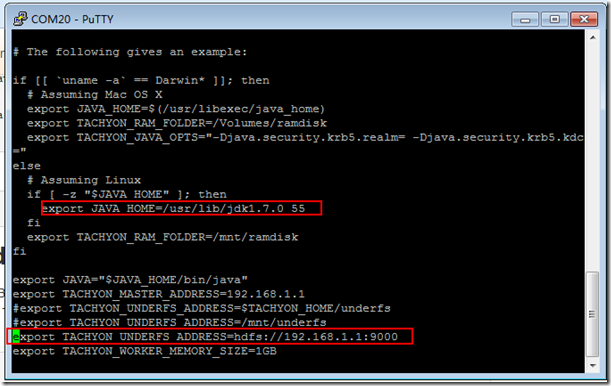
vi conf/tachyon-env.sh
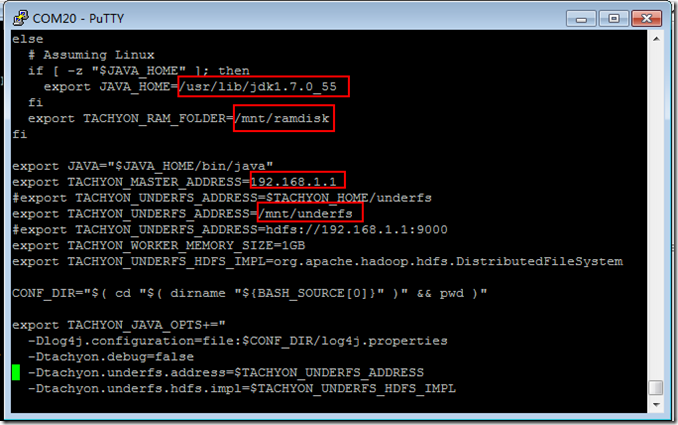
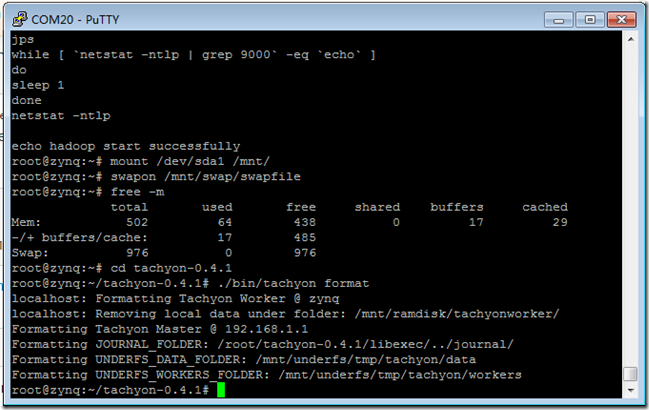
./bin/tachyon format
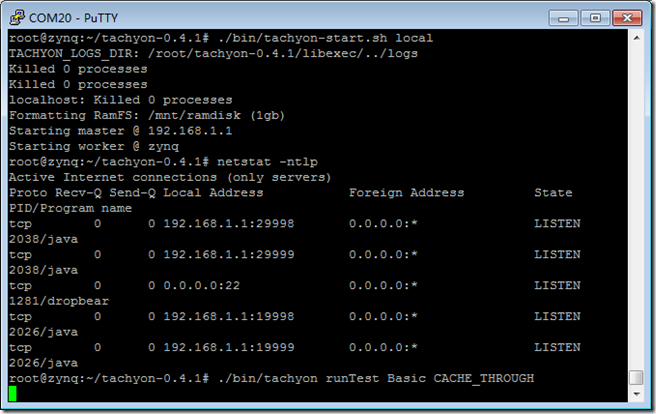
./bin/tachyon-start.sh local
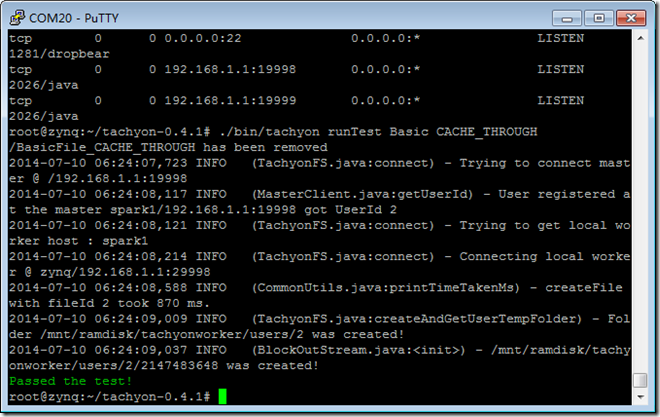
./bin/tachyon runTest Basic CACHE_THROUGH
(3)与Hadoop结合:Set HDFS as Tachyon’s under filesystem
因为2.4.0的hadoop需要重新编译,在arm平台安装maven会出错,故转移到x64pc机编译:
apt-get install maven
vi pom.xml
mvn -Dhadoop.version=2.4.0 clean package
cp -r /root/tachyon-0.4.1 /media/fs/root/
cd /root/tachyon-0.4.1
cd ..
cd hadoop-2.4.0/
vi etc/hadoop/core-site.xml
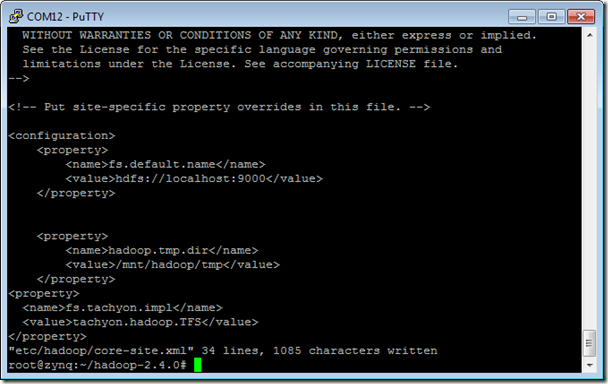
<property>
<name>fs.tachyon.impl</name>
<value>tachyon.hadoop.TFS</value>
</property>vi etc/hadoop/hadoop-env.sh
加入一行:
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/root/tachyon-0.4.1/target/tachyon-0.4
.1-jar-with-dependencies.jar
cd /root
./gohadoop.sh
cd tachyon-0.4.1
./bin/tachyon format
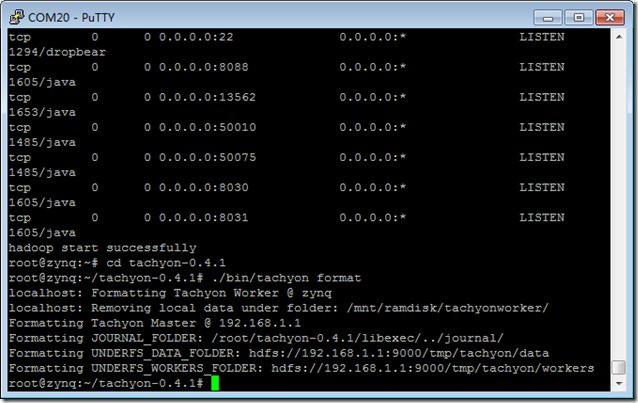
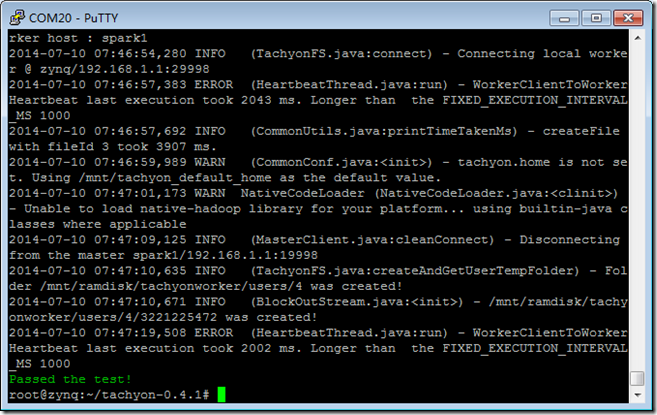
./bin/tachyon-start.sh local
./bin/tachyon runTest Basic CACHE_THROUGH
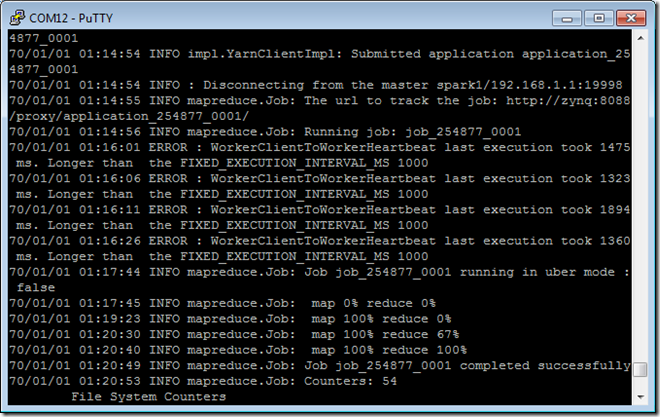
cd $HADOOP_HOME执行如下命令:./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.0.jar \
wordcount -libjars /root/tachyon-0.4.1/target/tachyon-0.4.1-jar-with-dependencies.jar \
tachyon://192.168.1.1:19998/in/file /out/file
(4)与Spark结合:Running Spark on Tachyon
cd spark-0.9.1-bin-hadoop2
vi conf/spark-env.sh
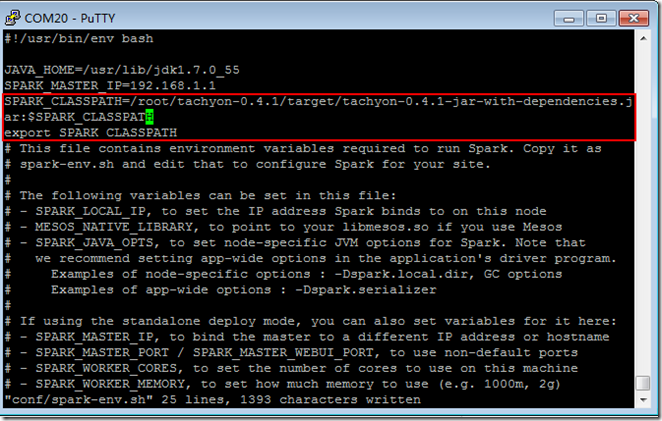
SPARK_CLASSPATH=/root/tachyon-0.4.1/target/tachyon-0.4.1-jar-with-dependencies.jar:$SPARK_CLASSPATH
export SPARK_CLASSPATH
export TACHYON_MASTER="192.168.1.1:19998"
新建一个配置文件:
vi conf/core-site.xml
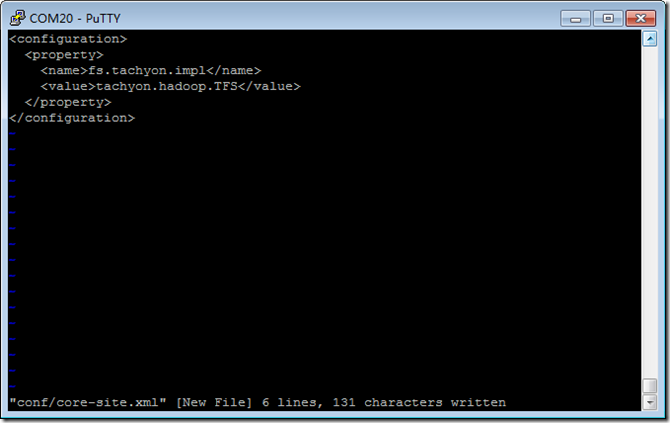
<configuration>
<property>
<name>fs.tachyon.impl</name>
<value>tachyon.hadoop.TFS</value>
</property>
</configuration>
运行
MASTER=spark://192.168.1.1:7077 ./bin/pyspark
file = sc.textFile("tachyon://192.168.1.1:19998/in/file")
counts = file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.collect()
counts.saveAsTextFile("tachyon://192.168.1.1:19998/out/mycount")
counts.saveAsTextFile("hdfs://192.168.1.1:9000/out/mycount1")
collect()正确执行,
save to hadoop 正确执行,
save to tachyon 后出错:
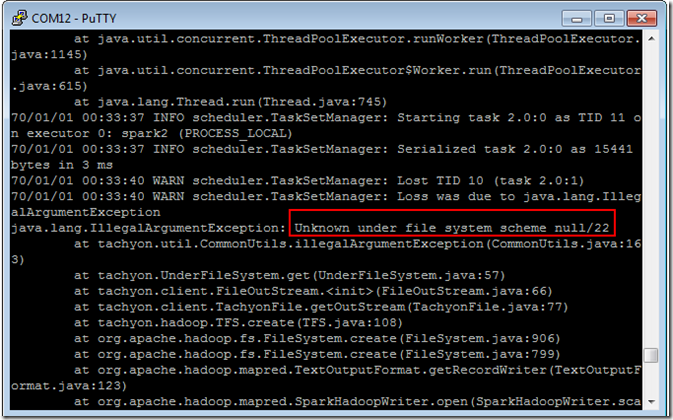
参考网站:http://tachyon-project.org/Syncing-the-Underlying-Filesystem.html
暂未解决。
先只测试用Tachyon读数据1G大小的文本文件:
使用hadoop读取使用了16分钟。
scp tachyon-0.4.1.bak2.tar.gz root@spark4:/root/
tachyon of zybo cluster的更多相关文章
- hadoop+tachyon+spark的zybo cluster集群综合配置
1.zybo cluster 架构简述: 1.1 zybo cluster 包含5块zybo 开发板组成一个集群,zybo的boot文件为digilent zybo reference design提 ...
- Learn ZYNQ(10) – zybo cluster word count
1.配置环境说明 spark:5台zybo板,192.168.1.1master,其它4台为slave hadoop:192.168.1.1(外接SanDisk ) 2.单节点hadoop测试: 如果 ...
- Learn ZYNQ (9)
创建zybo cluster的spark集群(计算层面): 1.每个节点都是同样的filesystem,mac地址冲突,故: vi ./etc/profile export PATH=/usr/loc ...
- Tachyon Cluster: 基于Zookeeper的Master High Availability(HA)高可用配置实现
1.Tachyon简介 Tachyon是一个高容错的分布式文件系统,允许文件以内存的速度在集群框架中进行可靠的共享,就像Spark和 MapReduce那样.通过利用信息继承,内存侵入,Tachyon ...
- Tachyon在Spark中的作用(Tachyon: Reliable, Memory Speed Storage for Cluster Computing Frameworks 论文阅读翻译)
摘要: Tachyon是一种分布式文件系统,能够借助集群计算框架使得数据以内存的速度进行共享.当今的缓存技术优化了read过程,可是,write过程由于须要容错机制,就须要通过网络或者 ...
- 分布式内存文件系统Tachyon
UCBerkeley研发的Tachyon(超光子['tækiːˌɒn],名字要不要这么太嚣张啊:)是一款为各种集群并发计算框架提供内存数据管理的平台,也可以说是一种内存式的文件系统吧.如下图,它就处于 ...
- Spark(十二) -- Spark On Yarn & Spark as a Service & Spark On Tachyon
Spark On Yarn: 从0.6.0版本其,就可以在在Yarn上运行Spark 通过Yarn进行统一的资源管理和调度 进而可以实现不止Spark,多种处理框架并存工作的场景 部署Spark On ...
- [Berkeley]弹性分布式数据集RDD的介绍(RDD: A Fault-Tolerant Abstraction for In-Memory Cluster Computing 论文翻译)
摘要: 本文提出了分布式内存抽象的概念--弹性分布式数据集(RDD,Resilient Distributed Datasets).它同意开发者在大型集群上运行基于内存的计算.RDD适用于两种 ...
- Node.js:进程、子进程与cluster多核处理模块
1.process对象 process对象就是处理与进程相关信息的全局对象,不需要require引用,且是EventEmitter的实例. 获取进程信息 process对象提供了很多的API来获取当前 ...
随机推荐
- UVA-11991 Easy Problem from Rujia Liu?
Problem E Easy Problem from Rujia Liu? Though Rujia Liu usually sets hard problems for contests (for ...
- PHP正则表达式详解(三)
1.preg_match() :preg_match() 函数用于进行正则表达式匹配,成功返回 1 ,否则返回 0 . 语法:int preg_match( string pattern, strin ...
- [Keygen]IntelliJ IDEA 14.1.7
IntelliJ IDEA 14.1.7 Keygen package com.candy.keygen.intelliJIdea; import java.math.BigInteger; impo ...
- SQLite返回码
SQLite返回码 返回码含义 宏 值 含义 SQLITE_OK 0 返回成功 SQLITE_ERROR 1 SQL错误或数据库不存在 SQLITE_INTERNAL 2 SQLite内部逻辑错误 S ...
- sublime text install packages报错
汉化版的sublime text安装软件包的时候报错如下: There are no packages available for install 打开控制台,ctrl+~,然后看到如下错误: Pac ...
- css3美化复选框checkbox
两种美化效果如下图: 代码(html) <div id="main"> <h2 class="top_title">使用CSS3美化复 ...
- 我常用的find命令
查找某种类型文件中包含特定字符的文件 find /* -type f -name "*.php" |xargs grep "rename(" find ./|x ...
- poj1001_Exponentiation_java高精度
Exponentiation Time Limit: 500MS Memory Limit: 10000K Total Submissions: 162918 Accepted: 39554 ...
- iOS/Android 浏览器(h5)及微信中唤起本地APP
在移动互联网,链接是比较重要的传播媒质,但很多时候我们又希望用户能够回到APP中,这就要求APP可以通过浏览器或在微信中被方便地唤起. 这是一个既直观又很好的用户体验,但在实现过程中会遇到各种问题: ...
- (转)nginx优化 实现10万并发访问量
转自http://www.cnblogs.com/pricks/p/3837149.html 一般来说nginx配置文件中对优化比较有作用的为以下几项:worker_processes 8;1 ngi ...