被 Pandas read_csv 坑了
被 Pandas read_csv 坑了
-- 不怕前路坎坷,只怕从一开始就走错了方向
Pandas 是python的一个数据分析包,纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas 就是为解决数据分析任务生的,无论是数据分析还是机器学习项目数据预处理中, Pandas 无处不在。
最近掉进一坑,差点铸成大错。实在没想到居然栽在pandas.read_csv上了,这里分享一下,希望大家注意。
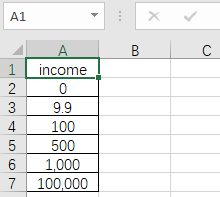
另:业务数据不方便拿出来演示,为尽可能复现,这里我手造了一份,另存为 income.csv 文件。
翻船记
读取csv文件小菜一碟
import numpy as np
import pandas as pd
df = pd.read_csv(r'C:\...\income.csv',encoding='utf-8')
读好了看看数据信息吧:
df.info()
RangeIndex: 6 entries, 0 to 5
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 income 6 non-null object
dtypes: object(1)
memory usage: 176.0+ bytes
诶,怎么数据成了object?不应该是float吗?
不管他,硬转一发
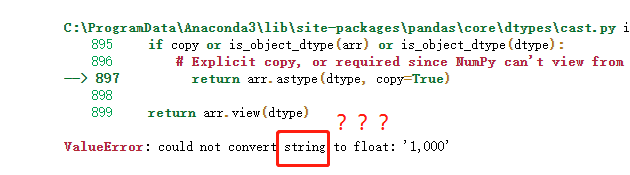
df=pd.DataFrame(df,dtype=np.float)
居然报错了,1000被读成了字符串。
其实这里我还掉进了另一个坑,使用了一个已被弃用的 .convert_objects 方法。这种方法更硬,直接把string转成了NaN,所以后面各种操作流畅且错误地进行着....这都是 pandas 没升级的锅,定期检查升级包太有必要了(pip 的高阶玩法)
说回刚才的问题,1,000被读成了字符串是因为csv文件中它使用了千位分隔符。问题其实非常简单,设置一下 thousands 参数就行了
df2 = pd.read_csv(r'C:\...\income.csv',encoding='utf-8',thousands =',')
看一下info
df2.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6 entries, 0 to 5
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 income 6 non-null float64
dtypes: float64(1)
往下继续
df2.describe()
income
count 6.000000
mean 16934.983333
std 40695.203980
min 0.000000
25% 32.425000
50% 300.000000
75% 875.000000
max 100000.000000
一切正常!
pandas.read_csv()参数

pandas.read_csv()的参数特别多,除了filepath,其他均可缺省。参数的具体含义这里就不赘述,还想复习一下的同学可以直接去看官方文档
http://pandas.pydata.org/pandas-docs/stable/io.html
英语不好的同学可以看一下热心博主的翻译版:
https://www.cnblogs.com/datablog/p/6127000.html
被 Pandas read_csv 坑了的更多相关文章
- API:详解 pandas.read_csv
pandas.read_csv 作为常用的读取数据的常用API,使用频率非常高,但是API中可选的参数有哪些呢? pandas项目代码 答案是: .read_csv(filepath_or_buffe ...
- pandas read_csv读取大文件的Memory error问题
今天在读取一个超大csv文件的时候,遇到困难:首先使用office打不开然后在python中使用基本的pandas.read_csv打开文件时:MemoryError 最后查阅read_csv文档发现 ...
- pandas.read_csv() 部分参数解释
read_csv()所有参数 pandas.read_csv( filepath_or_buffer, sep=',', delimiter=None, header='infer', names=N ...
- pandas.read_csv()参数(转载)
文章转载地址 pandas.read_csv参数整理 读取CSV(逗号分割)文件到DataFrame 也支持文件的部分导入和选择迭代 更多帮助参见:http://pandas.pydata.org/p ...
- pandas.read_csv()函数读取文件时,关于“header=None”影响读取列数区间的右闭合总结
对于一个没有字段名标题的数据,如data.csv 1.获取数据内容.pandas.read_csv("data.csv")默认情况下,会把数据内容的第一行默认为字段名标题. imp ...
- pandas.read_csv to_csv参数详解
pandas.read_csv参数整理 读取CSV(逗号分割)文件到DataFrame 也支持文件的部分导入和选择迭代 更多帮助参见:http://pandas.pydata.org/pandas ...
- pandas.read_csv参数详解
读取CSV(逗号分割)文件到DataFrame 也支持文件的部分导入和选择迭代 更多帮助参见:http://pandas.pydata.org/pandas-docs/stable/io.html 参 ...
- pandas.read_csv() 报错 OSError: Initializing from file failed,报错原因分析和解决方法
今天调用pandas读取csv文件时,突然报错“ OSError: Initializing from file failed ”,我是有点奇怪的,以前用的好好的,read_csv(path)方法不是 ...
- pandas.read_csv用法(转)
的数据结构DataFrame,几乎可以对数据进行任何你想要的操作. 由于现实世界中数据源的格式非常多,pandas也支持了不同数据格式的导入方法,本文介绍pandas如何从csv文件中导入数据. 从上 ...
随机推荐
- 如何使用iMazing编辑iOS设备的备份
乍一看,编辑iPhone或iPad的备份似乎是一个奇怪的命题,但实际上这样做的原因有很多,例如在备份数据损坏时进行修复,又如合并来自不同设备的数据. iMazing对备份文件编辑的支持非常全面,即使备 ...
- 攻克弹唱第七课(如何弹奏neon)
在本期文章中,笔者将通过Guitar Pro 7来跟大家研究一下neon的曲谱,顺便复习一下之前文章中说过的和弦技巧. 在<如何在指板上寻找特殊和弦(二)>这一期课程中,我们分析过如何使用 ...
- Dapr DotNet5 HTTP 调用
Dapr DotNet5 HTTP 调用 版本介绍 Dotnet 版本:5.0.100 Dapr dotnet 版本:0.12.0-preview01 注意: Asp.Net Core 项目中的 la ...
- 为k8s预留系统资源
为k8s预留系统资源 Kubernetes 的节点可以按照 Capacity 调度.默认情况下 pod 能够使用节点全部可用容量. 这是个问题,因为节点自己通常运行了不少驱动 OS 和 Kuberne ...
- 【震惊】手把手教你用python做绘图工具(一)
在这篇博客里将为你介绍如何通过numpy和cv2进行结和去创建画布,包括空白画布.白色画布和彩色画布.创建画布是制作绘图工具的前提,有了画布我们就可以在画布上尽情的挥洒自己的艺术细胞. 还在为如何去绘 ...
- 【MySQL/C#/.NET】VS2010报错--“.Net Framework Data Provider。可能没有安装。”
前言 公司行业是金融软件,之前用的都是Oracle数据库.Oracle数据库用一个词来形容:大而全.MySQL的话,可能是因为开源.便宜,现在越来越主流. 我们也支持MySQL数据库,不过平时不用.最 ...
- Redis分布式锁—SETNX+Lua脚本实现篇
前言 平时的工作中,由于生产环境中的项目是需要部署在多台服务器中的,所以经常会面临解决分布式场景下数据一致性的问题,那么就需要引入分布式锁来解决这一问题. 针对分布式锁的实现,目前比较常用的就如下几种 ...
- 浅尝 Elastic Stack (三) Logstash + Beats
本文使用 Filebeat,如果没有安装需要安装: curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat- ...
- 安装pillow报错处理
sudo python3 pip install pillow 报错:The headers or library files could not be found for jpeg,... 解决:安 ...
- day2(APlview+Serializers使用)
1.APIview使用 ModelVIewSet 是对 APIView 封装 ModelSerializer是对Serializeer 1.1 在user/urls.py中添加路由 urlpatte ...