Python利用openpyxl带格式统计数据(1)- 处理excel数据
统计数据的随笔写了两篇了,再来一篇,这是第三篇,前面第一篇是用xlwt写excel数据,第二篇是用xlwt写mysql数据。先贴要处理的数据截图:

再贴最终要求的统计格式截图:
第三贴代码:
1 '''
2 #利用openpyxl向excel模板写入数据
3 '''
4 #首先写本地excel的
5 import xlwt
6 import xlrd
7 import openpyxl
8
9 #提取数据
10 xlsx = xlrd.open_workbook("要处理的数据表路径/xxx.xlsx")
11 table = xlsx.sheet_by_index(0)
12
13 #空列表,用以存储数据
14 all_data = []
15
16 #循环,读取表格的每个单元格
17 for n in range(1, table.nrows):
18 date = table.cell_value(n, 0)
19 company = table.cell_value(n, 1)
20 province = table.cell_value(n, 2)
21 price = table.cell_value(n, 3)
22 weight = table.cell_value(n, 4)
23 #print(company,price,weight)
24 #开始提取我们需要的数据并存储到字典
25 data = {'company':company, 'price':price, 'weight':weight}
26 #print(data)
27 #将上面字典的每一项以追加的方式追加到空列表all_data
28 all_data.append(data)
29
30 #print(all_data,type(all_data))
31
32 #开始从字典里读取数据
33 a_weight = [] #存储张三粮配每车重量的列表
34 a_total_price = [] #存储张三粮配每车总价格的列表
35 b_weight = []
36 b_total_price = []
37 c_weight = []
38 c_total_price = []
39 d_weight = []
40 d_total_price = []
41 for i in all_data:
42 if i['company'] == "张三粮配":
43 a_weight.append(i['weight'])
44 a_total_price.append(i['weight'] * i['price'])
45 if i['company'] == "李四粮食":
46 b_weight.append(i['weight'])
47 b_total_price.append(i['weight'] * i['price'])
48 if i['company'] == "王五小麦":
49 c_weight.append(i['weight'])
50 c_total_price.append(i['weight'] * i['price'])
51 if i['company'] == "赵六麦子专营":
52 d_weight.append(i['weight'])
53 d_total_price.append(i['weight'] * i['price'])
54 #开始按表格要求的数据细化数据
55 #首先是张三的
56 a_che = len(a_weight)
57 a_dun = sum(a_weight)
58 a_sum_price = sum(a_total_price)
59 #李四
60 b_che = len(b_weight)
61 b_dun = sum(b_weight)
62 b_sum_price = sum(b_total_price)
63 #王五
64 c_che = len(c_weight)
65 c_dun = sum(c_weight)
66 c_sum_price = sum(c_total_price)
67 #赵六
68 d_che = len(d_weight)
69 d_dun = sum(d_weight)
70 d_sum_price = sum(d_total_price)
71
72 #开始用openpyxl导入模板
73 tem_workbook = openpyxl.load_workbook("模板路径/统计表_openpyxl.xlsx") #这里注意是xlsx格式的
74 #获取工作表
75 tem_sheet = tem_workbook['Sheet1'] #这里获取的工作表就是工作簿里的第一个表,表名看清楚
76 #开始写入数据
77 #写张三的,张三的在第三行第二到第四列
78 tem_sheet['B3'] = a_che #在第三行第二列写入总车数
79 tem_sheet['C3'] = a_dun #在第三行第三列写入总吨数
80 tem_sheet['D3'] = a_sum_price #在第三行第四列写入总价格
81 #开始写李四的,李四在第四行,第二到第四列
82 tem_sheet['B4'] = b_che
83 tem_sheet['C4'] = b_dun
84 tem_sheet['D4'] = b_sum_price
85 #开始写王五,王五的在第五行,第二到第四列
86 tem_sheet['B5'] = c_che
87 tem_sheet['C5'] = c_dun
88 tem_sheet['D5'] = c_sum_price
89 #开始写赵六,赵六的在第五行,第二到第四列
90 tem_sheet['B6'] = d_che
91 tem_sheet['C6'] = d_dun
92 tem_sheet['D6'] = d_sum_price
93
94 #保存工作簿
95 tem_workbook.save('路径/2020-11-04-openpyxl-excel.xlsx')
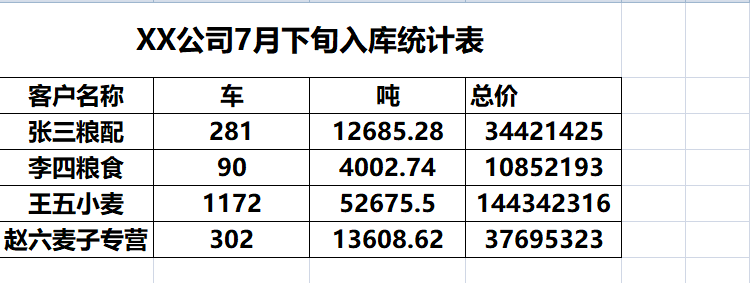
最后贴效果截图:
Python利用openpyxl带格式统计数据(1)- 处理excel数据的更多相关文章
- Python利用openpyxl带格式统计数据(2)- 处理mysql数据
上一篇些了openpyxl处理excel数据,再写一篇处理mysql数据的,还是老规矩,贴图,要处理的数据截图: 再贴最终要求的统计格式截图: 第三贴代码: 1 ''' 2 #利用openpyxl向e ...
- oracle xmltype导入并解析Excel数据 (三)解析Excel数据
包声明 create or replace package PKG_EXCEL_UTILS is -- Author: zkongbai-- Create at: 2016-07-06-- Actio ...
- 把数据库中的数据制作成Excel数据
把数据库中的数据制作成Excel数据 如果我们在使用Excel的时候,需要把数据库中的数据制作成Excel数据透视表,我们该怎么操作呢?如果数据在数据库中,我们不用把数据导入到工作表中,我们可以直接以 ...
- 数据透视:Excel数据透视和Python数据透视
作者 | leo 早于90年代初,数据透视的概念就被提出,主要的应用场景是处理大量数据的交互式汇总查询,它实现了行或列的移动,使得行可以移到列上,列移到行上,从而根据使用者的诉求取对关注的数据子集进行 ...
- python 利用jieba库词频统计
1 #统计<三国志>里人物的出现次数 2 3 import jieba 4 text = open('threekingdoms.txt','r',encoding='utf-8').re ...
- 小白学 Python 数据分析(7):Pandas (六)数据导入
人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Pandas (一)概述 小白学 Python 数据分析(3):P ...
- python通过openpyxl操作excel
python 对Excel操作常用的主要有xlwt.xlrd.openpyxl ,前者xlwt主要适合于对后缀为xls比较进行写入,而openpyxl主要是针对于Excel 2007 以上版本进行操作 ...
- 办公室文员必备python神器,将PDF文件表格转换成excel表格!
[阅读全文] 第三方库说明 # PDF读取第三方库 import pdfplumber # DataFrame 数据结果处理 import pandas as pd 初始化DataFrame数据对象 ...
- oracle xmltype导入并解析Excel数据 (一)创建表与序
表说明: T_EXCEL_IMPORT_DATASRC: Excel数据存储表,(使用了xmltype存储Excel数据) 部分字段说明: BUSINESSTYPE: Excel模板类型,一个Exce ...
随机推荐
- 采集post传输的数据
采集数据,网页上的数据是开发者通过ajax的post方式显示的,就得用到curl以及它的跨域方法 代码: $post_data------post传过去的参数 $ch = curl_init(); $ ...
- 2020 CSP-J 多校赛 Day 2 T2 题解
0x01 引入 在考场时想了一个错误算法,口胡一下,或许对理解正解有点帮助. 我们考虑交换两个数产生的代价,你会发现我们需要让大的数重复被交换的次数尽可能少,减少它对后面的代价. 那么不难构思出一个按 ...
- 【AcWing 113】【交互】特殊排序——二分
(题面来自AcWing) 有N个元素,编号1.2..N,每一对元素之间的大小关系是确定的,关系不具有传递性. 也就是说,元素的大小关系是N个点与N*(N-1)/2条有向边构成的任意有向图. 然而,这是 ...
- 精尽MyBatis源码分析 - Spring-Boot-Starter 源码分析
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...
- django中的积累
只要继承了model.Model, 就会生成一个新的表,但是,如果在Meta方法中添加abstract=True,就不会产生新的表,而是作为一个基类存放多个表共同拥有的方法和字段等 from djan ...
- 20200315_python3.6去除标点符号
line = "python3.6下进行去!@#$%^&*()除标点测试,:!大家好,:!&>啥都不是!@#¥%--&*(-.||" # python ...
- 第15.47节、PyQt显示部件:QGraphicsView图形视图和QGraphicsScene图形场景简介及应用案例
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 老猿学5G博文目录 一.概述 Designer中的Graphics V ...
- Python正则表达式书写容易碰到的陷阱:\W*和\W*?匹配过程遇到的问题
老猿在分析<Python正则表达式\W+和\W*匹配过程的深入分析>中的问题时,想到一个问题,如果"re.split('(\W*)','Hello,world')"的处 ...
- PyQt(Python+Qt)学习随笔:Designer中ItemViews类部件的frameShadow属性
老猿Python博文目录 老猿Python博客地址 frameShadow属性是从QFrame继承的属性,对应类型为QFrame.Shadow,该属性表示框架提供三维效果的阴影类型,有如下取值: 可以 ...
- Android使用阿里镜像
在学习room时项目一直在编译中,最后排查发现是依赖没有下载完导致.随后查询将依赖下载源改为阿里源,即可正常使用. 需要修改 build.gradle (project),改为以下内容: // Top ...