Netty之Unpooled_Bytebuf
前言
计算机存储基本单位是字节(byte),传输基本单位是bit(位),JAVA NIO提供了ByteBuffer等七种容器来提升传输时的效率,但是在使用时比较复杂,经常要进行读写切换,主要缺点如下:
(1)ByteBuffer长度固定,一旦分配完成,它的容量不能动态扩展和收缩,当需要编码的对象大于ByteBuffer的容量时,会发生索引越界异常;
(2)ByteBuffer只有一个标识位置的指针position,读写的时候需要手工调用flip()和rewind()等,使用者必须小心谨慎地处理这些API,否则很容易导致程序处理失败;
(3)ByteBuffer的API功能有限,一些高级和实用的特性它不支持,需要使用者自己编程实现。
为了弥补这些不足,Netty提供了自己的ByteBuffer实现—— ByteBuf。
ByteBuf介绍
ByteBuf是Netty.Buffer中的类,主要特征如下:
- 读和写用不同的索引。
- 读和写可以随意的切换,不需要调用flip()方法。
- 容量能够被动态扩展,和StringBuilder一样。
- 用其内置的复合缓冲区可实现透明的零拷贝。
- 支持方法链。
- 支持引用计数。count == 0,release。
- 支持池。
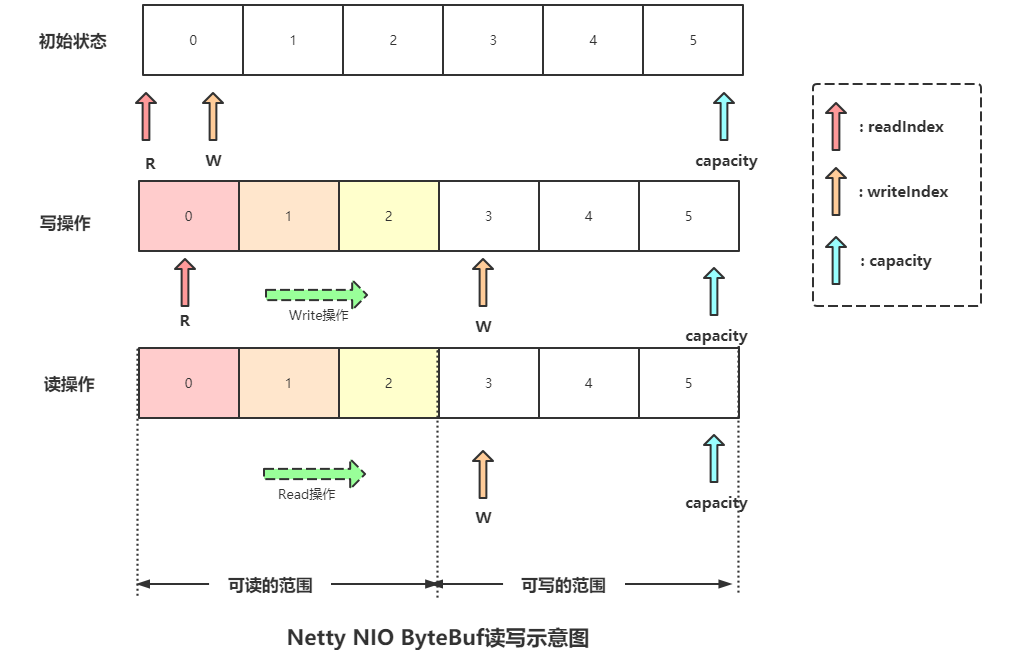
ByteBuf通过两个位置指针来协助缓冲区的读写操作,分别是读操作(使用readerIndex)、写操作(使用writerIndex)。
readerIndex和writerIndex的取值一开始都是0,随着数据的写入writerIndex会增加,读取数据会使readerIndex增加,但是它不会超过writerIndex。在读取之后,0~readerIndex的就被视为discard的,调discardReadBytes方法,可以释放这部分空间,它的作用类似ByteBuffer的compact方法。readerIndex和writerIndex之间的数据是可读取的,等价于ByteBuffer position和limit之间的数据。writerIndex和capacity之间的空间是可写的,等价于ByteBuffer limit和capacity之间的可用空间。
由于写操作不修改readerIndex指针,读操作不修改writerIndex指针,因此读写之间不再需要调整位置指针,这极大地简化了缓冲区的读写操作,避免了由于遗漏或者不熟悉flip()操作导致的功能异常。
传统JAVA NIO ByteBuffer图示:
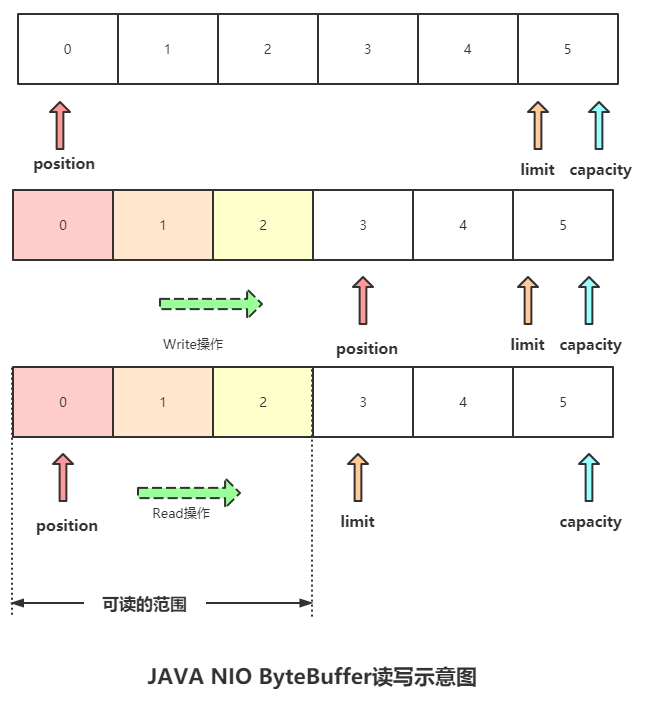
ByteBuf读写示意图:
ByteBuf零拷贝
netty提供了CompositeByteBuf类实现零拷贝。大多数情况下,在进行网络数据传输时我们会将消息分为消息头head和消息体body,甚至还会有其他部分,这里我们简单的分为两部分来进行探讨:
以前的做法
ByteBuffer header = ByteBuffer.allocate(1);
header.put("a".getBytes());
header.flip();
ByteBuffer body = ByteBuffer.allocate(1);
body.put("b".getBytes());
body.flip(); ByteBuffer message = ByteBuffer.allocate(header.remaining() + body.remaining()); message.put(header);
message.put(body);
message.flip();
while (message.hasRemaining()){
System.err.println((char)message.get());
}
这样为了得到完整的消息体相当于对内存进行了多余的两次拷贝,造成了很大的资源的浪费。
netty提供的方法
CompositeByteBuf messageBuf = Unpooled.compositeBuffer();
ByteBuf headerBuf = Unpooled.buffer(1);
headerBuf.writeByte('a');
ByteBuf bodyBuf = Unpooled.buffer(1);
bodyBuf.writeByte('b');
messageBuf.addComponents(headerBuf, bodyBuf);
for (ByteBuf buf : messageBuf) {
System.out.println((char)buf.readByte());
System.out.println(buf.toString());10
}
这里通过CompositeByteBuf 对象将headerBuf 与bodyBuf组合到了一起,也得到了完整的消息体,但是并未进行内存上的拷贝。可以注意下我在上面代码段中进行的buf.toString()方法的调用,得出来的结果是:指向的还是原来分配的空间地址,也就证明了零拷贝的观点。
ByteBuf引用计数
retain和lock类似,release和unlock类似,内部维护一个计数器,计数器到0的时候就表示已经释放掉了。往一个已经被release掉的buffer中去写数据,会抛出IllegalReferenceCountException: refCnt: 0异常。
ByteBuf buffer = Unpooled.buffer(1);
int i = buffer.refCnt();
System.err.println("refCnt : " + i); //refCnt : 1
buffer.retain();
buffer.retain();
buffer.retain();
buffer.retain();
i = buffer.refCnt();
System.err.println("refCnt : " + i); //refCnt : 5
boolean release = buffer.release();
i = buffer.refCnt();
System.err.println("refCnt : " + i + " ===== " + release); //refCnt : 4 ===== false
release = buffer.release(4);
i = buffer.refCnt();
System.err.println("refCnt : " + i + " ===== " + release); //refCnt : 0 ===== true
引用计数器实现的原理并不复杂,仅仅只是涉及到一个指定对象的活动引用,对象被初始化后引用计数值为1。只要引用计数大于0,这个对象就不会被释放,当引用计数减到为0时,这个实例就会被释放,被释放的对象不应该再被使用。
ByteBuf支持池
Netty对ByteBuf的分配提供了池支持,具体的类是PooledByteBufAllocator。用这个分配器去分配ByteBuf可以提升性能以及减少内存碎片。Netty中默认用PooledByteBufAllocator当做ByteBuf的分配器。PooledByteBufAllocator对象可以从Channel中或者绑定了Channel的ChannelHandlerContext中去获取到。
Channel channel = ...;
ByteBufAllocator allocator = channel.alloc();
....
ChannelHandlerContext ctx = ...;
ByteBufAllocator allocator2 = ctx.alloc();
ByteBuf API介绍
创建ByteBuf
// 创建一个heapBuffer,是在堆内分配的
ByteBuf heapBuf = Unpooled.buffer(5);
if (heapBuf.hasArray()) {
byte[] array = heapBuf.array();
int offset = heapBuf.arrayOffset() + heapBuf.readerIndex();
int length = heapBuf.readableBytes();
handleArray(array, offset, length);
}
// 创建一个directBuffer,是分配的堆外内存
ByteBuf directBuf = Unpooled.directBuffer();
if (!directBuf.hasArray()) {
int length = directBuf.readableBytes();
byte[] array = new byte[length];
directBuf.getBytes(directBuf.readerIndex(), array);
handleArray(array, 0, length);
}
这两者的主要区别:
a. 分配的堆外内存空间,在进行网络传输时就不用进行拷贝,直接被网卡使用。但是这些空间想要被jvm所使用,必须拷贝到堆内存中。
b. 分配和释放堆外内存相比堆内存而言,代价是相当昂贵的。
c. 使用这两者buffer中的数据的方式也略有不同,见上面的代码段。
读写数据(readByte writeByte)
ByteBuf heapBuf = Unpooled.buffer(5);
heapBuf.writeByte(1);
System.err.println("writeIndex : " + heapBuf.writerIndex());//writeIndex : 1
heapBuf.readByte();
System.err.println("readIndex : " + heapBuf.readerIndex());//readIndex : 1
heapBuf.setByte(2, 2);
System.err.println("writeIndex : " + heapBuf.writerIndex());//writeIndex : 1
heapBuf.getByte(2);
System.err.println("readIndex : " + heapBuf.readerIndex());//readIndex : 1
进行readByte和writeByte方法的调用时会改变readIndex和writeIndex的值,而调用set和get方法时不会改变readIndex和writeIndex的值。上面的测试案例中打印的writeIndex和readIndex均为1,并未在调用set和get方法后被改变。
discardReadBytes方法
先看一张图:

从上面的图中可以观察到,调用discardReadBytes方法后,readIndex置为0,writeIndex也往前移动了Discardable bytes长度的距离,扩大了可写区域。但是这种做法会严重影响效率,它进行了大量的拷贝工作。如果要进行数据的清除操作,建议使用clear方法。调用clear()方法将会将readIndex和writeIndex同时置为0,不会进行内存的拷贝工作,同时要注意,clear方法不会清除内存中的内容,只是改变了索引位置而已。
Derived buffers
这里介绍三个方法(浅拷贝):
duplicate():直接拷贝整个buffer。
slice():拷贝buffer中已经写了的数据。
slice(index,length): 拷贝buffer中从index开始,长度为length的数据。
readSlice(length): 从当前readIndex读取length长度的数据。
上面这几个方法的虽然是拷贝,但是这几个方法并没有实际意义上去复制一个新的buffer出来,它和原buffer是共享数据的。所以说调用这些方法消耗是很低的,并没有开辟新的空间去存储,但是修改后会影响原buffer。这种方法也就是咱们俗称的浅拷贝。
要想进行深拷贝,这里可以调用copy()和copy(index,length)方法,使用方法和上面介绍的一致,但是会进行内存复制工作,效率很低。
ByteBuf heapBuf = Unpooled.buffer(5);
heapBuf.writeByte(1);
heapBuf.writeByte(1);
heapBuf.writeByte(1);
heapBuf.writeByte(1);
// 直接拷贝整个buffer
ByteBuf duplicate = heapBuf.duplicate();
duplicate.setByte(0, 2);
System.err.println("duplicate: " + duplicate.getByte(0) + "====heapBuf: " + heapBuf.getByte(0));//duplicate: 2====heapBuf: 2
// 拷贝buffer中已经写了的数据
ByteBuf slice = heapBuf.slice();
System.err.println("slice capacity: " + slice.capacity());//slice capacity: 4
slice.setByte(2, 5);
ByteBuf slice1 = heapBuf.slice(0, 3);
System.err.println("slice1 capacity: "+slice1.capacity());//slice1 capacity: 3
System.err.println("duplicate: " + duplicate.getByte(2) + "====heapBuf: " + heapBuf.getByte(2));//duplicate: 5====heapBuf: 5复制代码
Netty之Unpooled_Bytebuf的更多相关文章
- 谈谈如何使用Netty开发实现高性能的RPC服务器
RPC(Remote Procedure Call Protocol)远程过程调用协议,它是一种通过网络,从远程计算机程序上请求服务,而不必了解底层网络技术的协议.说的再直白一点,就是客户端在不必知道 ...
- 基于netty http协议栈的轻量级流程控制组件的实现
今儿个是冬至,所谓“冬大过年”,公司也应景五点钟就放大伙儿回家吃饺子喝羊肉汤了,而我本着极高的职业素养依然坚持留在公司(实则因为没饺子吃没羊肉汤喝,只能呆公司吃食堂……).趁着这一个多小时的时间,想跟 ...
- 从netty-example分析Netty组件续
上文我们从netty-example的Discard服务器端示例分析了netty的组件,今天我们从另一个简单的示例Echo客户端分析一下上个示例中没有出现的netty组件. 1. 服务端的连接处理,读 ...
- 源码分析netty服务器创建过程vs java nio服务器创建
1.Java NIO服务端创建 首先,我们通过一个时序图来看下如何创建一个NIO服务端并启动监听,接收多个客户端的连接,进行消息的异步读写. 示例代码(参考文献[2]): import java.io ...
- 从netty-example分析Netty组件
分析netty从源码开始 准备工作: 1.下载源代码:https://github.com/netty/netty.git 我下载的版本为4.1 2. eclipse导入maven工程. netty提 ...
- Netty实现高性能RPC服务器优化篇之消息序列化
在本人写的前一篇文章中,谈及有关如何利用Netty开发实现,高性能RPC服务器的一些设计思路.设计原理,以及具体的实现方案(具体参见:谈谈如何使用Netty开发实现高性能的RPC服务器).在文章的最后 ...
- Netty构建分布式消息队列(AvatarMQ)设计指南之架构篇
目前业界流行的分布式消息队列系统(或者可以叫做消息中间件)种类繁多,比如,基于Erlang的RabbitMQ.基于Java的ActiveMQ/Apache Kafka.基于C/C++的ZeroMQ等等 ...
- 基于Netty打造RPC服务器设计经验谈
自从在园子里,发表了两篇如何基于Netty构建RPC服务器的文章:谈谈如何使用Netty开发实现高性能的RPC服务器.Netty实现高性能RPC服务器优化篇之消息序列化 之后,收到了很多同行.园友们热 ...
- Netty构建分布式消息队列实现原理浅析
在本人的上一篇博客文章:Netty构建分布式消息队列(AvatarMQ)设计指南之架构篇 中,重点向大家介绍了AvatarMQ主要构成模块以及目前存在的优缺点.最后以一个生产者.消费者传递消息的例子, ...
随机推荐
- 简单的冒泡排序算法(java)
package lianxi; public class BubbleSort { public static void main(String[] args) { int[] array = {12 ...
- SpringCloud 源码系列(5)—— 负载均衡 Ribbon(下)
SpringCloud 源码系列(4)-- 负载均衡 Ribbon(上) SpringCloud 源码系列(5)-- 负载均衡 Ribbon(下) 五.Ribbon 核心接口 前面已经了解到 Ribb ...
- [论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks
[论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks 本文结构 解决问题 主要贡献 算法 ...
- 【Tomcat】手写迷你版Tomcat
目录 源码地址 一,分析 Mini版Tomcat需要实现的功能 二,开发--准备工作 2.1 新建Maven工程 2.2 定义编译级别 2.3 新建主类编写启动入口和端口 三,开发--1.0版本 3. ...
- java: Compilation failed: internal java compiler error
IDEA 编译项目出现java: Compilation failed: internal java compiler error 原因: 项目Java版本不一致 解决办法: 点击FIle> ...
- C#—连接SQLserver数据库,并执行查询语句代码
//字段ArticleID,ArticleName,ArticleNumber,Unit,Weight,Price,Currency,IsIuggage,IsQuarantine string str ...
- Java学习日报7.15
package oddor;import java.util.Scanner;public class Oddor{ public static void main(String args[]) { ...
- js实现页面消息滚动效果
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- .NET 云原生架构师训练营(模块二 基础巩固 MongoDB 问答系统)--学习笔记
2.5.6 MongoDB -- 问答系统 MongoDB 数据库设计 API 实现概述 MongoDB 数据库设计 设计优化 内嵌(mongo)还是引用(mysql) 数据一致性 范式:将数据分散到 ...
- shell脚本学习之6小时搞定(1)
shell脚本学习之6小时搞定(1) 简介 Shell是一种脚本语言,那么,就必须有解释器来执行这些脚本. Unix/Linux上常见的Shell脚本解释器有bash.sh.csh.ksh等,习惯上把 ...