SnowNLP——获取关键词(keywords(1))
一、SnowNLP的获取文本关键词
前面介绍了SnowNLP的获取关键词的方法,这里再重现一下
1 from snownlp import SnowNLP
2 # 提取文本关键词,总结3个关键词
3 text = '随着顶层设计完成,全国政协按下信息化建设快进键:建设开通全国政协委员移动履职平台,开设主题议政群、全国政协书院等栏目,建设委员履职数据库,拓展网上委员履职综合服务功能;建成网络议政远程协商视频会议系统,开展视频调研、远程讨论活动,增强网络议政远程协商实效;建立修订多项信息化规章制度,优化电子政务网络。'
4 s = SnowNLP(text)
5 print(s.keywords(3))
6
7 --->['全国', '政协', '远程']
二、源码分析
我们进入SnowNLP的源码看一下
1、SnowNLP(text)
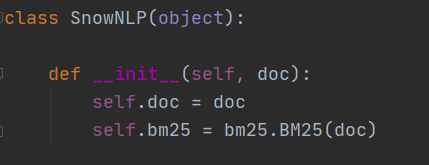
这里我们记住self.doc是我们传入的文本
2、keywords(self, limit=5, merge=False)

这是SnowNLP源码中keywords方法的源码,我们一行一行的看下具体流程:
70 def keywords(self, limit=5, merge=False):
limit参数:这个参数对应的是调用 keywords(3)方法时传入的形参,默认为5,即默认会返回五个关键词。
71 doc = []
72 sents = self.sentences
这是做了一个赋值,我看看下源码:
self.sentences是对输入文本的整理,对文本分句、分词

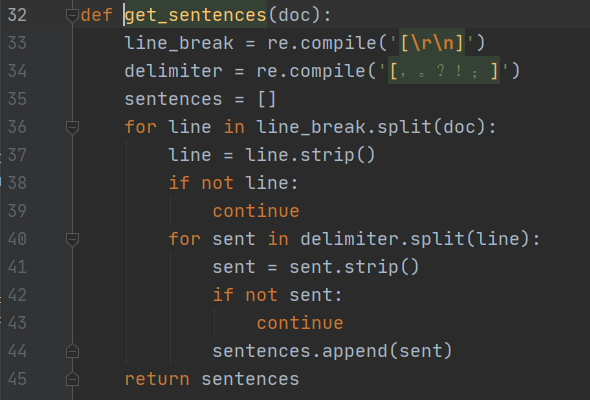
上图参数中的doc是我们传入的文本,这个方法主要功能是将我们传入的文本进行整理
33行、34行:定义了两个正则表达式,分别是筛选换行符、部分中文标点
36行:是根据换行符对文本进行切割后进行遍历。
40行:再上一次循环中,又将文本根据中文标点符号进行分割。
44行:将得到的句子放到一个list中,即sentences。
我们再回到keywords方法中:
72 sents = self.sentences
由此得到一个sents,里面存储的是我们输入文本分割成的句子的list
73 for sent in sents: #对sents进行遍历,得到每个句子
74 words = seg.seg(sent) #对句子进行分词
75 words = normal.filter_stop(words) #去除停用词
76 doc.append(words) #将得到的每个句子的分词加到doc中
77 rank = textrank.KeywordTextRank(doc) #得到一个KeywordTextRank对象
78 rank.solve() #计算词语的关键度,并进行关键排序
这里我们看一下KeywordTextRank()类以及rank.solve()方法:
rank.solve()是计算关键度的方法,是获取关键词的核心!!
1 class KeywordTextRank(object):
2
3 def __init__(self, docs):
4 self.docs = docs
5 self.words = {}
6 self.vertex = {}
7 self.d = 0.85
8 self.max_iter = 200
9 self.min_diff = 0.001
10 self.top = []
11
12 def solve(self):
13 for doc in self.docs: # self.docs是我们传入的文本被分词后的词语list:[['a','b','c'],['d','e'],['f','g']]
14 que = []
15 for word in doc: # 遍历每个句子的词语,得到该句的词
16 if word not in self.words: # 如果该词不存在self.words中,则添加进去
17 self.words[word] = set() # 一个字典集合:{'word':set()}
18 self.vertex[word] = 1.0 # 一个字典集合:{'word':1.0}
19 que.append(word) #将词加到que中:['word']
20 if len(que) > 5:
21 que.pop(0) # 如果que的长度大于5则移除第一个词
22 for w1 in que: # 遍历que
23 for w2 in que: # 遍历que
24 if w1 == w2:
25 continue # 如果w1与w2相等则结束这一轮循环,继续下一轮循环
26 self.words[w1].add(w2) # 将词加到自己字典中
27 self.words[w2].add(w1) #
28 for _ in range(self.max_iter): # 循环200次
29 m = {}
30 max_diff = 0
31 tmp = filter(lambda x: len(self.words[x[0]]) > 0,
32 self.vertex.items()) # 过滤每个词,判断值位的set中是否有值,有的话保留,返回:[('a', 1), ('b', 1), ('c', 1)]
33 tmp = sorted(tmp, key=lambda x: x[1] / len(self.words[x[0]])) # 根据值位的set的长度排序,返回:[('a', 1), ('b', 1), ('c', 1)]
34 for k, v in tmp: # k为词,v为相关度
35 for j in self.words[k]: # 遍历每个词对应的set集合(相关词)
36 if k == j:
37 continue
38 if j not in m:
39 m[j] = 1 - self.d
40 m[j] += (self.d / len(self.words[k]) * self.vertex[k]) # m值 = 0.85 / set的长度 * 1
41 for k in self.vertex: # {词1:相关度1,词2:相关度2}
42 if k in m and k in self.vertex:
43 if abs(m[k] - self.vertex[k]) > max_diff: # 计算本次相关度与上一次相关度之差的绝对值是否符合设定的阈值
44 max_diff = abs(m[k] - self.vertex[k]) # 改变阈值
45 self.vertex = m # 获取到本次相关度集合
46 if max_diff <= self.min_diff: # 设定退出条件
47 break
48 self.top = list(self.vertex.items()) # 将字典转成集合
49 self.top = sorted(self.top, key=lambda x: x[1], reverse=True) # 根据相似度进行排序 [('a', 1), ('b', 2), ('c', 3)]
50
51 def top_index(self, limit):
52 return list(map(lambda x: x[0], self.top))[:limit] # 获取list的值的key,并截取list,[0-limit)
53
54 def top(self, limit):
55 return list(map(lambda x: self.docs[x[0]], self.top)) # 获取字典中top字段对应值的value
我们再回到keywords方法中:
79 ret = []
80 for w in rank.top_index(limit): # 获取按词语关键度排序后并截取长度的list
81 ret.append(w)
82 if merge:
83 wm = words_merge.SimpleMerge(self.doc, ret)
84 return wm.merge()
85 return ret
merge默认为False,如果手动设定为True的话将走SimpleMerge类对结果重新处理
看下SimpleMerge源码:
# -*- coding: utf-8 -*-
from __future__ import unicode_literals class SimpleMerge(object): def __init__(self, doc, words):
self.doc = doc
self.words = words def merge(self):
trans = {}
for w in self.words:
trans[w] = ''
for w1 in self.words:
cw = 0
lw = len(w1)
for i in range(len(self.doc)-lw+1):
if w1 == self.doc[i: i+lw]:
cw += 1
for w2 in self.words:
cnt = 0
l2 = len(w1)+len(w2)
for i in range(len(self.doc)-l2+1):
if w1+w2 == self.doc[i: i+l2]:
cnt += 1
if cw < cnt*2:
trans[w1] = w2
break
ret = []
for w in self.words:
if w not in trans:
continue
s = ''
now = trans[w]
while now:
s += now
if now not in trans:
break
tmp = trans[now]
del trans[now]
now = tmp
trans[w] = s
for w in self.words:
if w in trans:
ret.append(w+trans[w])
return ret
SnowNLP——获取关键词(keywords(1))的更多相关文章
- ThinkPHP自动获取关键词(调用第三方插件)
ThinkPHP自动获取关键词调用在线discuz词库 先按照下图路径放好插件 方法如下 /** * 自动获取关键词(调用第三方插件) * @return [type] [description] * ...
- phpcms 去掉默认自动获取关键词、自动提取第一张图片?
进入后台,内容--模型管理--管理模型,选择文章模型的字段管理,选择第13项内容--修改,然后把字段提示代码中的2个checked去掉就行了. <label><input name= ...
- SnowNLP:•中文分词•词性标准•提取文本摘要,•提取文本关键词,•转换成拼音•繁体转简体的 处理中文文本的Python3 类库
SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和Te ...
- 中文情感分析——snownlp类库 源码注释及使用
最近发现了snownlp这个库,这个类库是专门针对中文文本进行文本挖掘的. 主要功能: 中文分词(Character-Based Generative Model) 词性标注(TnT 3-gram 隐 ...
- Python第三方库SnowNLP(Simplified Chinese Text Processing)快速入门与进阶
简介 github地址:https://github.com/isnowfy/snownlp SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的 ...
- SnowNLP:一个处理中文文本的 Python 类库[转]
SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和Te ...
- Wordpress添加关键词和描述
找到主题的header.php文件,然后在其<head>标签内加入加一下代码: 详细版 <?php $description = ''; $keywords = ''; if (is ...
- seo优化入门教程:影响关键词排名的因素
很多人都说网站优化,但是怎么个优化法?优化什么东西?很多人都不知道.虽然我们优化的是我们的网站,但是提升的却是我们的关键词排名. 我们不管去优化哪一个网站,得到的搜索结果,他都会去触发关键词排名的因素 ...
- Python处理PDF-通过关键词定位-截取PDF中的图表
起因: 因为个人原因, 这些天了解了一下Python处理PDF的方法. 首先是PDF转txt, 这个方法比较多, 这里就不再赘述, 主要聊一下PDF中的图片获取. 这里用我自己的例子, 不过具体情况还 ...
随机推荐
- Codeforces Round #649 (Div. 2) C、Ehab and Prefix MEXs D、Ehab's Last Corollary 找环和点染色
题目链接:C.Ehab and Prefix MEXs 题意; 有长度为n的数组a(下标从1开始),要求构造一个相同长度的数组b,使得b1,b2,....bi集合中没有出现过的最小的数是ai. mex ...
- 病毒侵袭 HDU - 2896 板子题
当太阳的光辉逐渐被月亮遮蔽,世界失去了光明,大地迎来最黑暗的时刻....在这样的时刻,人们却异常兴奋--我们能在有生之年看到500年一遇的世界奇观,那是多么幸福的事儿啊~~ 但网路上总有那么些网站,开 ...
- k8s二进制部署 - etcd节点安装
下载etcd [root@hdss7-12 ~]# useradd -s /sbin/nologin -M etcd [root@hdss7-12 ~]# cd /opt/src/ [root@hds ...
- ArcGIS处理栅格数据(二)
五.栅格数据的配准 1.有参考图层 ① 在ArcMap里面添加需要配准的栅格数据集和参考数据集. ② 在ArcMap里面添加"地理配准"工具条. 添加成功后如下图所示: ③ 将需要 ...
- codefforces 877B
B. Nikita and stringtime limit per test2 secondsmemory limit per test256 megabytesinputstandard inpu ...
- mybatis(二)全局配置mybatis-config.xml
转载:https://www.cnblogs.com/wuzhenzhao/p/11092526.html 大部分时候,我们都是在Spring 里面去集成MyBatis.因为Spring 对MyBat ...
- WSL2+Terminal+VScode配置调试
最近几天一直想找个方法把VMware虚拟机和远程连接工具MobaXterm这一组配合替换掉,因为每次开启虚拟机操作Ubuntu都需要占用很大的内存,而且要等好久好久才能开启!!!后面还要使用MobaX ...
- how to install GitLab on Raspberry Pi OS
how to install GitLab on Raspberry Pi OS GitLab & Raspberry Pi refs https://about.gitlab.com/ins ...
- Python Learning Paths
Python Learning Paths Python Expert Python in Action Syntax Python objects Scalar types Operators St ...
- App Store Connect
App Store Connect https://developer.apple.com/support/app-store-connect/ https://developer.apple.com ...