Python3爬取小说并保存到文件
问题
python课上,老师给同学们布置了一个问题,因为这节课上学的是正则表达式,所以要求利用python爬取小说网的任意小说并保存到文件。
我选的网站的URL是‘https://www.biqukan.com/0_159/’
解决方法
首先先思考解决方式。
- 先获取到网页源码,从源码中找出小说的名字和目录结构
- 创建文件保存的目录,目录名是小说名
- 从网页代码中获取小说的目录列表
- 循环遍历目录,获取目录中每篇的超链接和文章标题
- 如果是超链接就继续发请求访问从而获取这章小说的正文
- 将正文写入创建好的目录,文件名是这章小说的标题名
使用之前需要导入相关的模块,requests模块,re正则的模块,os模块
导入有好几种,这里介绍的是在命令窗口中导入
以管理员的身份打开命令窗口。
2、输入pip install requests 下载安装requests模块,同样的方式安装剩余模块。
r = requests.get(url)
# 向URL发起get请求,r是返回的对象
r.text就是响应的网页源代码
r.encoding=r.apparent_encoding
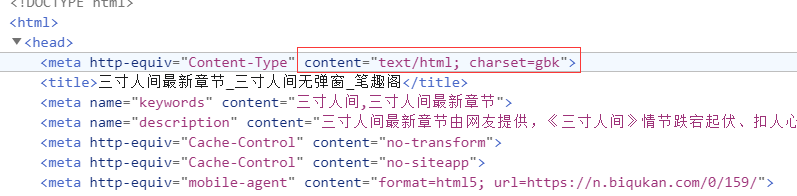
- 这里的encoding指的是对响应结果的编码格式,如果head中没有charset指明编码格式,那么默认是ISO-8859-1,r.text根据encoding编码响应内容;
- apparent_encding是 响应头的编码格式。从网页源代码中可以找出编码方式。
字符编码方式
r.raise_for_status()
如果status_code不是200,产生异常requests.HTTPError;这是HTTP错误。
该语句便于利用try-except进行异常处理。
正则表达式re.findall()方法返回的是一个list集合,关于正则表达式的一些字符。
.代表匹配除换行外的任意字符,*代表匹配一次到N次,?代表采用非贪婪模式匹配,不加?默认是贪婪模式进行匹配。
输入小说的链接,按下F12,查看源代码,检查元素,或是点
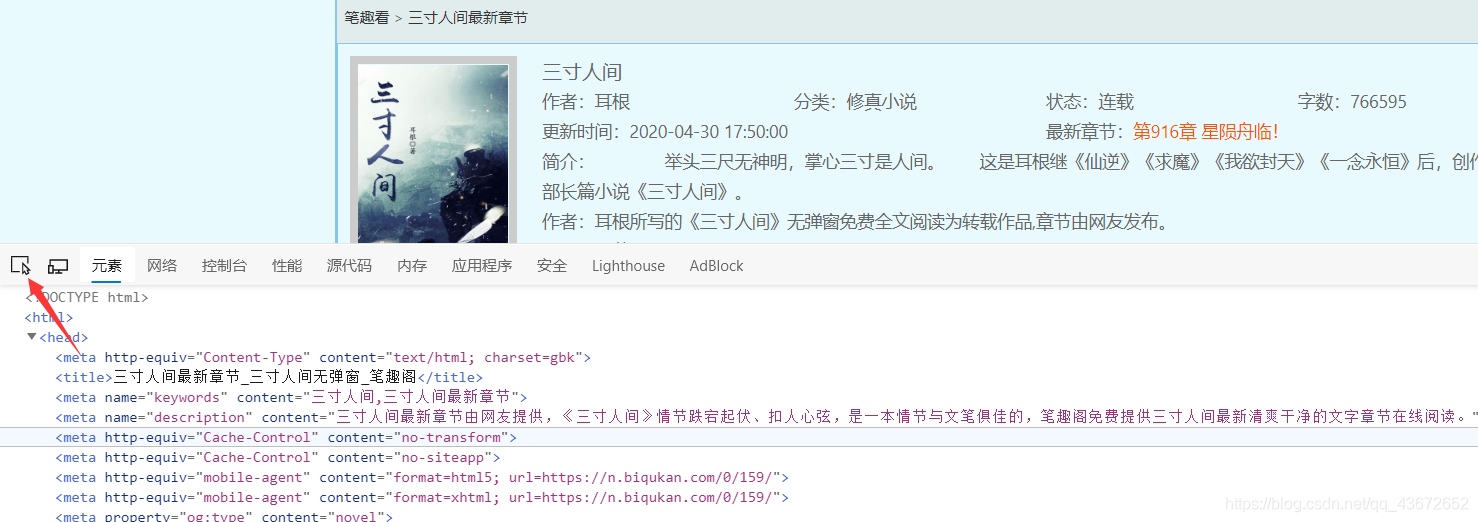
最左边的按钮,找到小说的名字,这时他在h2标签体中;
因此
name = re.findall(r'<h2>(.*?)</h2>',r.text)[0]
因为findall返回的是一个list集合,但是匹配到的只有小说名字一个元素,所以[0]就直接获取了小说名字 ‘三寸人间’
然后创建目录,先判断保存小说的目录存不存在,如果已存在不用创建,如果不存在再创建。这里目录名字就是小说名。
创建完目录后,继续获取小说的目录列表。
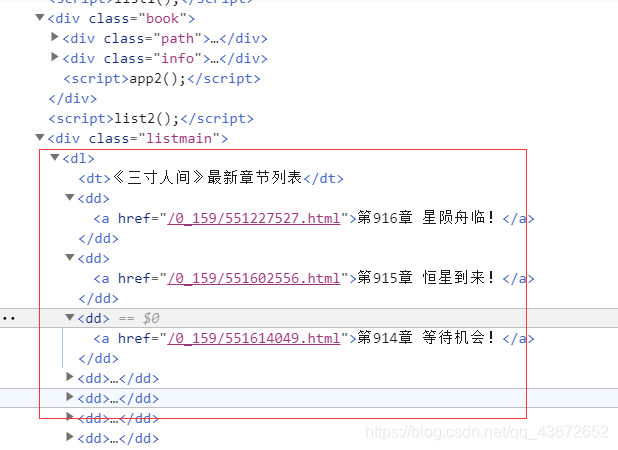
由上图可知,目录都在标签<dl></dl>中,
因此
novleList = re.findall(r'<dl>(.*?)</dl>',html,re.S)[0]
获取目录列表集合,

然后我们要的是a标签找连接里面的内容和href属性值。
在对他进行匹配。得到如下

剩下的就是遍历集合,取出超链接的href和标题,进而访问href,访问的时候需要加上网站的前缀,https://www.biqukan.com/。然后得到正文的返回结果。


想要获取小说内容采用正则匹配,以</script>开头,以<script>结尾。取中间内容。
content = re.findall(r'<script>app2.*?</script>(.*?)<script>',chapterHtml.text,re.S)
最后在保存前需要注意的是,小说中有空格和换行等HTML代码,需要将其替换成相应的格式,保存的时候一定不要忘了编码格式!!!
完整代码如下
import re
import requests
import os
# 将要爬取的url
url = 'https://www.biqukan.com/0_159/'
"""
1. 获取小说名字
2. 创建保存小说的目录
3. 从网页代码中获取小说的目录列表
4. 循环遍历目录,获取每篇的标题,每篇的超链接,如果是超链接就继续请求,进而获取文章内容,最后创建文件将章节写入
"""
# 1.获取小说名
def getNovelName(url):
r = requests.get(url)
# 打印状态码
print(r.status_code)
try:
r.raise_for_status()
r.encoding = r.apparent_encoding
html = r.text
name = re.findall(r'<h2>(.*?)</h2>', html)[0]
except:
return '获取失败'
return name
dirName = getNovelName(url)
#2. 保存小说的路径
path = 'D://workspace//python//reptile//work9_regular/'+dirName
#. 创建一个保存小说的目录
def createDir(path):
try:
if not os.path.exists(path):
os.mkdir(dirName)
else:
print('该文件夹已存在')
except:
print('创建文件失败!')
#3. 创建目录
createDir(path)
def getHtml(url):
r = requests.get(url)
r.encoding=r.apparent_encoding
if r.status_code==200:
return r.text
# 获取小说主页源代码
html = getHtml(url)
#4. 获取目录列表
novleList = re.findall(r'<dl>(.*?)</dl>',html,re.S)[0]
#5. 获取目录中的链接和标题
alls = re.findall(r'<a href ="(.*?)">(.*?)</a>',novleList,re.S)
def writeToFile(alls,path):
# 遍历目录下的标题和链接,继续访问链接获取内容
for item in alls:
hrefs = item[0] # 超链接地址
title = item[1] # 标题
chapterHtml = requests.get('https://www.biqukan.com/'+hrefs)
chapterHtml.encoding=chapterHtml.apparent_encoding
content = re.findall(r'<script>app2.*?</script>(.*?)<script>',chapterHtml.text,re.S)[0]
content = content.replace('<br />','\n') # 替换换行
content = content.replace('\u3000','\t') # 替换制表
content = content.replace(' ',' ') # 替换空格
f = open(path+'/'+title+'.txt','w',encoding='utf-8') # 注意编码方式
f.write(content)
# 6.写入文件
writeToFile(alls,path)
本人初学者,以上有错误的地方欢迎批评指正,有更好的想法的欢迎评论交流!
最后成功保存下来的截图!

Python3爬取小说并保存到文件的更多相关文章
- python3下BeautifulSoup练习一(爬取小说)
上次写博客还是两个月以前的事,今天闲来无事,决定把以前刚接触python爬虫时的一个想法付诸行动:就是从网站上爬取小说,这样可以省下好多流量(^_^). 因为只是闲暇之余写的,还望各位看官海涵:不足之 ...
- python3爬取女神图片,破解盗链问题
title: python3爬取女神图片,破解盗链问题 date: 2018-04-22 08:26:00 tags: [python3,美女,图片抓取,爬虫, 盗链] comments: true ...
- Python3 爬取微信好友基本信息,并进行数据清洗
Python3 爬取微信好友基本信息,并进行数据清洗 1,登录获取好友基础信息: 好友的获取方法为get_friends,将会返回完整的好友列表. 其中每个好友为一个字典 列表的第一项为本人的账号信息 ...
- Python实战项目网络爬虫 之 爬取小说吧小说正文
本次实战项目适合,有一定Python语法知识的小白学员.本人也是根据一些网上的资料,自己摸索编写的内容.有不明白的童鞋,欢迎提问. 目的:爬取百度小说吧中的原创小说<猎奇师>部分小说内容 ...
- python3爬取网页
爬虫 python3爬取网页资源方式(1.最简单: import'http://www.baidu.com/'print2.通过request import'http://www.baidu.com' ...
- python爬虫——爬取小说 | 探索白子画和花千骨的爱恨情仇(转载)
转载出处:药少敏 ,感谢原作者清晰的讲解思路! 下述代码是我通过自己互联网搜索和拜读完此篇文章之后写出的具有同样效果的爬虫代码: from bs4 import BeautifulSoup imp ...
- Python3爬取人人网(校内网)个人照片及朋友照片,并一键下载到本地~~~附源代码
题记: 11月14日早晨8点,人人网发布公告,宣布人人公司将人人网社交平台业务相关资产以2000万美元的现金加4000万美元的股票对价出售予北京多牛传媒,自此,人人公司将专注于境内的二手车业务和在美国 ...
- python3爬取微博评论并存为xlsx
python3爬取微博评论并存为xlsx**由于微博电脑端的网页版页面比较复杂,我们可以访问手机端的微博网站,网址为:https://m.weibo.cn/一.访问微博网站,找到热门推荐链接我们打开微 ...
- python3爬取全民K歌
Python3爬取全民k歌 环境 python3.5 + requests 1.通过歌曲主页链接爬取 首先打开歌曲主页,打开开发者工具(F12). 选择Network,点击播放,会发现有一个请求返回的 ...
随机推荐
- CSP-S2020 DP专项训练
前言 \(\text{CPS-S2020}\) 已然临近,而 \(\text{DP}\) 作为联赛中的常考内容,是必不可少的复习要点,现根据教练和个人刷题,整理部分好题如下(其实基本上是直接搬--). ...
- P6007 [USACO20JAN]Springboards G
本题解仅用与作者加深算法理解,也欢迎大家的阅读 做题背景 原本关于二维的点的 \(dp\) 问题一直都没有什么想法,昨天晚上再做一道 \(cdq\) 的题目的时候被同学询问了这道题,发现可以用二维偏序 ...
- 后台运行程序nohup的使用
linux后台运行程序 nohup python3 test.py >output 2>&1 & 参数解释 用途:不挂断地运行命令. 语法:nohup Command [ ...
- STL——容器(Map & multimap)的删除
Map & multimap 的删除 map.clear(); //删除所有元素 map.erase(pos); //删除pos迭代器所指的元素,返回下一个元素的 ...
- AWT05-对话框
1.Dialog Dialog组件是Window的子类,是容器类,是特殊组件. Dialog是可以独立存在的顶级窗口,使用上和普通窗口几乎没有区别,但应注意以下两点: 1.对话框通常依赖于其他窗口,也 ...
- 【Tomcat 源码系列】Tomcat 整体结构
一,前言 在开始看源码细节之前,首先要想好要看的问题.想好问题之后,我们该如何寻找要看的代码呢? 其实,这就好像去爬山的时候,突然想去上厕所,如果有一副地图,那么我们可以很快就找到厕所的位置.带着问题 ...
- vue 事件基本用法
事件基本用法 事件的函数都定义在VUE实例中的methods中,当然也可以直接写在元素内,但是这并不利于后期的维护,需要注意的是:在methods定义的函数内想要引用插值内容,需要使用this,不然就 ...
- OS第六章
OS第七次实验 多进程 添加一个进程体 添加进程B,首先设置i的初值为0x1000,这样来方便程序运行时的时候能区分.其余地方与A一致. 相关变量和宏 Minix中定义了一个数组,叫做tasktab的 ...
- Flutter InkWell - Flutter每周一组件
Flutter Inkwell使用详解 该文章属于[Flutter每周一组件]系列,其它组件可以查看该系列下的文章,该系列会不间断更新:所有组件的demo已经上传值Github: https://gi ...
- IIS本地部署局域网可随时访问的项目+mysql可局域网内访问
开端口即可 或者以下 原理 在本机的IIS下创建一个网站,文件目录直接指向Web项目文件夹 步骤 1.项目的启动项目为web 2.在iis中创建一个新的网站(Work_TK_EIS) 文件目录为web ...