java8 stream api流式编程
java8自带常用的函数式接口
- Predicate boolean test(T t) 传入一个参数返回boolean值
- Consumer void accept(T t) 传入一个参数,无返回值
- Function<T,R> R apply(T t) 传入一个参数,返回另一个类型
准备数据
//计算机俱乐部
private static List<Student> computerClub = Arrays.asList(
new Student("2015134001", "小明", 15, "1501"),
new Student("2015134003", "小王", 14, "1503"),
new Student("2015134006", "小张", 15, "1501"),
new Student("2015134008", "小梁", 17, "1505")
);
//篮球俱乐部
private static List<Student> basketballClub = Arrays.asList(
new Student("2015134012", "小c", 13, "1503"),
new Student("2015134013", "小s", 14, "1503"),
new Student("2015134015", "小d", 15, "1504"),
new Student("2015134018", "小y", 16, "1505")
);
//乒乓球俱乐部
private static List<Student> pingpongClub = Arrays.asList(
new Student("2015134022", "小u", 16, "1502"),
new Student("2015134021", "小i", 14, "1502"),
new Student("2015134026", "小m", 17, "1504"),
new Student("2015134027", "小n", 16, "1504")
);
private static List<List<Student>> allClubStu = new ArrayList<>();
allClubStu.add(computerClub);
allClubStu.add(basketballClub);
allClubStu.add(pingpongClub);
常用的stream三种创建方式
- 集合 Collection.stream()
- 静态方法 Stream.of
- 数组 Arrays.stream
//1.集合
Stream<Student> stream = basketballClub.stream();
//2.静态方法
Stream<String> stream2 = Stream.of("a", "b", "c");
//3.数组
String[] arr = {"a","b","c"};
Stream<String> stream3 = Arrays.stream(arr);
Stream的终止操作
- foreach(Consumer c) 遍历操作
- collect(Collector) 将流转化为其他形式
- max(Comparator) 返回流中最大值
- min(Comparator) 返回流中最小值
- count 返回流中元素综述
Collectors 具体方法
- toList List 把流中元素收集到List
- toSet Set 把流中元素收集到Set
- toCollection Coolection 把流中元素收集到Collection中
- groupingBy Map<K,List> 根据K属性对流进行分组
- partitioningBy Map<boolean, List> 根据boolean值进行分组
//此处只是演示 此类需求直接用List构造器即可
List<Student> collect = computerClub.stream().collect(Collectors.toList());
Set<Student> collect1 = pingpongClub.stream().collect(Collectors.toSet());
//注意key必须是唯一的 如果不是唯一的会报错而不是像普通map那样覆盖
Map<String, String> collect2 = pingpongClub.stream()
.collect(Collectors.toMap(Student::getIdNum, Student::getName));
//分组 类似于数据库中的group by
Map<String, List<Student>> collect3 = pingpongClub.stream()
.collect(Collectors.groupingBy(Student::getClassNum));
//字符串拼接 第一个参数是分隔符 第二个参数是前缀 第三个参数是后缀
String collect4 = pingpongClub.stream().map(Student::getName).collect(Collectors.joining(",", "【", "】"));
//【小u,小i,小m,小n】
//三个俱乐部符合年龄要求的按照班级分组
Map<String, List<Student>> collect5 = Stream.of(basketballClub, pingpongClub, computerClub)
.flatMap(e -> e.stream().filter(s -> s.getAge() < 17))
.collect(Collectors.groupingBy(Student::getClassNum));
//按照是否年龄>16进行分组 key为true和false
ConcurrentMap<Boolean, List<Student>> collect6 = Stream.of(basketballClub, pingpongClub, computerClub)
.flatMap(Collection::stream)
.collect(Collectors.groupingByConcurrent(s -> s.getAge() > 16));
Stream的中间操作
- filter(Predicate) 筛选流中某些元素

//筛选1501班的学生
computerClub.stream().filter(e -> e.getClassNum().equals("1501")).forEach(System.out::println);
//筛选年龄大于15的学生
List<Student> collect = computerClub.stream().filter(e -> e.getAge() > 15).collect(Collectors.toList());
- map(Function f) 接收流中元素,并且将其映射成为新元素,例如从student对象中取name属性

//篮球俱乐部所有成员名 + 暂时住上商标^_^,并且获取所有队员名
List<String> collect1 = basketballClub.stream()
.map(e -> e.getName() + "^_^")
.collect(Collectors.toList());
collect1.forEach(System.out::println);
//小c^_^^_^
//小s^_^^_^
//小d^_^^_^
//小y^_^^_^
- flatMap(Function f) 将所有流中的元素并到一起连接成一个流
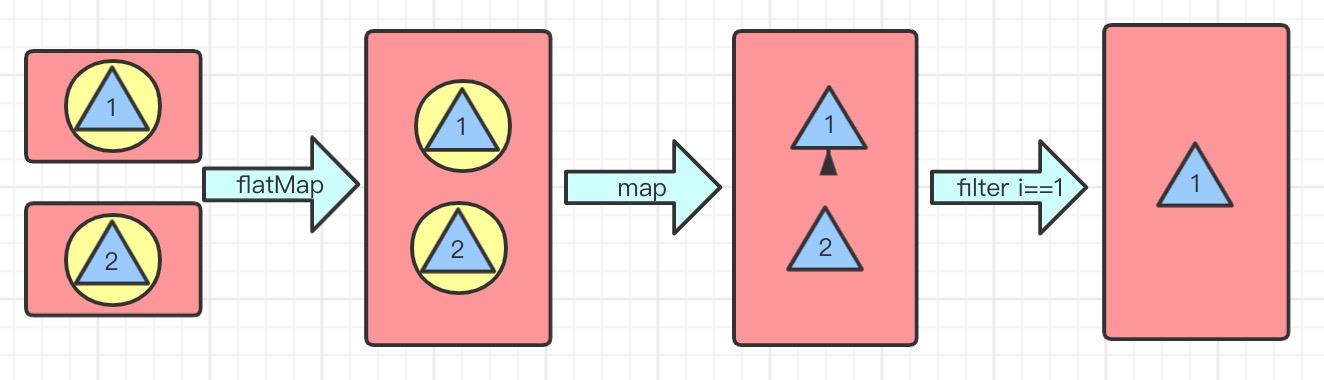
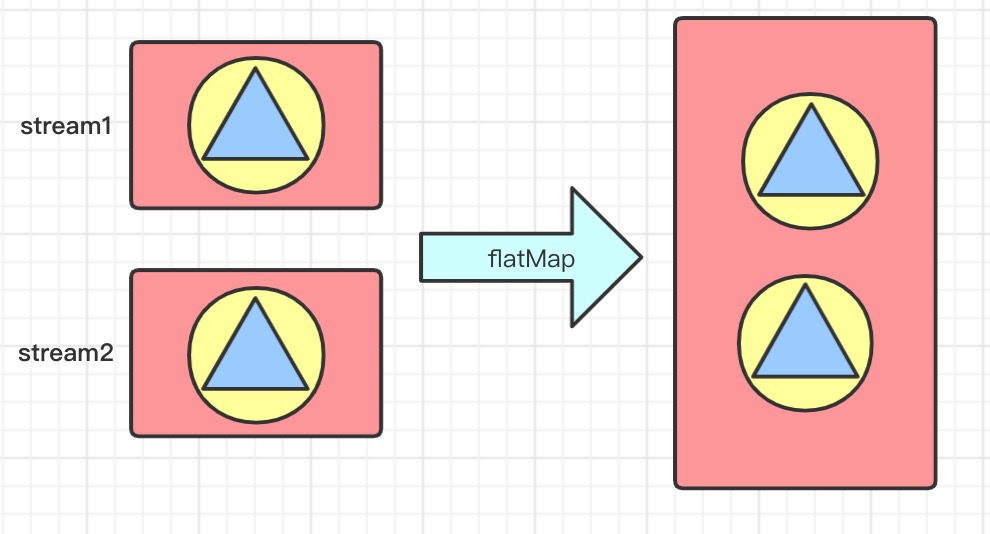
//获取年龄大于15的所有俱乐部成员
List<Student> collect2 = Stream.of(basketballClub, computerClub, pingpongClub)
.flatMap(e -> e.stream().filter(s -> s.getAge() > 15))
.collect(Collectors.toList());
collect2.forEach(System.out::println);
//用双层list获取所有年龄大于15的俱乐部成员
List<Student> collect3 = allClubStu.stream()
.flatMap(e -> e.stream().filter(s -> s.getAge() > 15))
.collect(Collectors.toList());
collect3.forEach(System.out::println);
- peek(Consumer c) 获取流中元素,操作流中元素,与foreach不同的是不会截断流,可继续操作流
//篮球俱乐部所有成员名 + 赞助商商标^_^,并且获取所有队员详细内容
List<Student> collect = basketballClub.stream()
.peek(e -> e.setName(e.getName() + "^_^"))
.collect(Collectors.toList());
collect.forEach(System.out::println);
//Student{idNum='2015134012', name='小c^_^', age=13, classNum='1503'}
//Student{idNum='2015134013', name='小s^_^', age=14, classNum='1503'}
//Student{idNum='2015134015', name='小d^_^', age=15, classNum='1504'}
//Student{idNum='2015134018', name='小y^_^', age=16, classNum='1505'}
distinct() 通过流所生成元素的equals和hashCode去重
limit(long val) 截断流,取流中前val个元素
sorted(Comparator) 产生一个新流,按照比较器规则排序
sorted() 产生一个新流,按照自然顺序排序
List<String> list = Arrays.asList("b","b","c","a");
list.forEach(System.out::print); //bbca
List<String> collect = list.stream().distinct().sorted().collect(Collectors.toList());
collect.forEach(System.out::print);//abc
//获取list中排序后的top2 即截断取前两个
List<String> collect1 = list.stream().distinct().sorted().limit(2).collect(Collectors.toList());
collect1.forEach(System.out::print);//ab
匹配
- booelan allMatch(Predicate) 都符合
- .boolean anyMatch(Predicate) 任一元素符合
- boolean noneMatch(Predicate) 都不符合
boolean b = basketballClub.stream().allMatch(e -> e.getAge() < 20);
boolean b1 = basketballClub.stream().anyMatch(e -> e.getAge() < 20);
boolean b2 = basketballClub.stream().noneMatch(e -> e.getAge() < 20);
寻找元素
- findFirst——返回第一个元素
- findAny——返回当前流中的任意元素
Optional<Student> first = basketballClub.stream().findFirst();
if (first.isPresent()) {
Student student = first.get();
System.out.println(student);
}
Optional<Student> any = basketballClub.stream().findAny();
if (any.isPresent()) {
Student student2 = any.get();
System.out.println(student2);
}
Optional<Student> any1 = basketballClub.stream().parallel().findAny();
System.out.println(any1);
计数和极值
- count——返回流中元素的总个数
- max——返回流中最大值
- min——返回流中最小值
long count = basketballClub.stream().count();
Optional<Student> max = basketballClub.stream().max(Comparator.comparing(Student::getAge));
if (max.isPresent()) {
Student student = max.get();
}
Optional<Student> min = basketballClub.stream().min(Comparator.comparingInt(Student::getAge));
if (min.isPresent()) {
Student student = min.get();
}
java8 stream api流式编程的更多相关文章
- Java9第四篇-Reactive Stream API响应式编程
我计划在后续的一段时间内,写一系列关于java 9的文章,虽然java 9 不像Java 8或者Java 11那样的核心java版本,但是还是有很多的特性值得关注.期待您能关注我,我将把java 9 ...
- Stream流式编程
Stream流式编程 Stream流 说到Stream便容易想到I/O Stream,而实际上,谁规定“流”就一定是“IO流”呢?在Java 8中,得益于Lambda所带来的函数式编程,引入了一个 ...
- 20190827 On Java8 第十四章 流式编程
第十四章 流式编程 流的一个核心好处是,它使得程序更加短小并且更易理解.当 Lambda 表达式和方法引用(method references)和流一起使用的时候会让人感觉自成一体.流使得 Java ...
- JDK8新特性(二) 流式编程Stream
流式编程是1.8中的新特性,基于常用的四种函数式接口以及Lambda表达式对集合类数据进行类似流水线一般的操作 流式编程分为大概三个步骤:获取流 → 操作流 → 返回操作结果 流的获取方式 这里先了解 ...
- golang的极简流式编程实现
传统的过程编码方式带来的弊端是显而易见,我们经常有这样的经验,一段时间不维护的代码或者别人的代码,突然拉回来看需要花费较长的时间,理解原来的思路,如果此时有个文档或者注释写的很好的话,可能花的时间会短 ...
- 如何用Java8 Stream API找到心仪的女朋友
传统的的Java 集合操作是有些啰嗦的,当我们需要对结合元素进行过滤,排序等操作的时候,通常需要写好几行代码以及定义临时变量. 而Java8 Stream API 可以极大简化这一操作,代码行数少,且 ...
- 何用Java8 Stream API进行数据抽取与收集
上一篇中我们通过一个实例看到了Java8 Stream API 相较于传统的的Java 集合操作的简洁与优势,本篇我们依然借助于一个实际的例子来看看Java8 Stream API 如何抽取及收集数据 ...
- Fork/Join框架与Java8 Stream API 之并行流的速度比较
Fork/Join 框架有特定的ExecutorService和线程池构成.ExecutorService可以运行任务,并且这个任务会被分解成较小的任务,它们从线程池中被fork(被不同的线程执行)出 ...
- java8流式编程(一)
传送门 <JAVA8开发指南>为什么你需要关注 JAVA8 <Java8开发指南>翻译邀请 Java8初体验(一)lambda表达式语法 Java8初体验(二)Stream语法 ...
随机推荐
- 零基础学习python 你该怎么做
本人文科生,回顾自己近 2 年的Python 自学经历,有一些学习心得和避坑经验分享给大家,让大家在学习 Python 的过程中少走一些弯路!减少遇到不必要的学习困难! 首先,最开始最大的困难应该就是 ...
- 工作流学习之 IDEA 使用activiti插件 出现乱码
今天学习 工作流 (work flow ) 的时候遇到了一点小问题 就是在 activitit的插件的时候 出现了乱码,弄了很久,终于解决了,就做个总结 嘻嘻 当场懵了,我记得我改了编码呀 - (Se ...
- LightningChart解决方案:XY和3D图表(Polymer Char GPC-IR®-工程案例)
LightningChart解决方案:XY和3D图表(Polymer Char GPC-IR-工程案例) 所在行业:石化公司成立时间:1992年LightningChart解决方案:XY和3D图表 P ...
- javascript笔记day01
JavaScript基础语法 HTML :标记语言 JavaScript :编程语言 序言 JavaScript发展历史(JS) 1. 1994年,网景公司(Netscape)发布了Navigator ...
- 聊聊 HTTP 常见的请求方式
在互联网已经渗透了生产.生活各个角落的今天,人们可以登录微信语音聊天,可以随手"扫"到各种功能的二维码,可以通过方便快捷的无人超市购物--这种互联网领域的跨越式发展,不仅满足了人们 ...
- python函数收集不确定数量的值
python写函数的时候,有时候会不确定到底传入多少值. 首先是,*args,单星号参数收集参数: 1 #!usr/bin/python 2 #-*-coding:utf-8-*- 3 4 #定义一个 ...
- Entity Framework 更新失败,调试后发现是AsNoTracking的原因
public override int SaveChanges() { var changedEntities = ChangeTracker.Entries().Where(e => e.St ...
- WIN7远程桌面连接提示:“发生身份验证错误。要求的函数不受支持”
问题 WIN7远程桌面连接–"发生身份验证错误.要求的函数不受支持" 最近WIN7升级补丁后发现远程桌面无法连接了,报"发生身份验证错误.要求的函数不受支持"的 ...
- EF5中使用UnitOfWork
前言 每次提交数据库都会打开一个连接,造成结果是:多个连接无法共用一个数据库级别的事务,也就无法保证数据的原子性.一致性. 解决办法是:在ObjectContext的CRUD操作基础上再包装一层,提供 ...
- 如何用tep完成增删改查接口自动化
tep的设计理念是让人人都可以用Python写自动化,本文就来介绍如何用tep完成增删改查接口自动化. 环境变量 编辑fixtures/fixture_admin.py: "qa" ...