ClickHouse安装使用(单机、集群、高可用)
Clickhouse版本:20.3.6.40-2

安装包地址:https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/
一、单机版
1、安装依赖
yum install libicu.x86_64
2、下载安装包
http://repo.yandex.ru/clickhouse/rpm/
3、安装
rpm -ivh *.rpm --force --nodeps
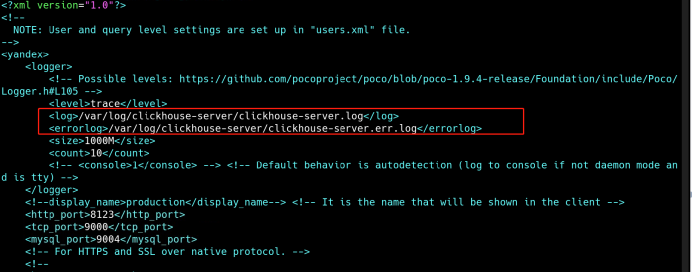
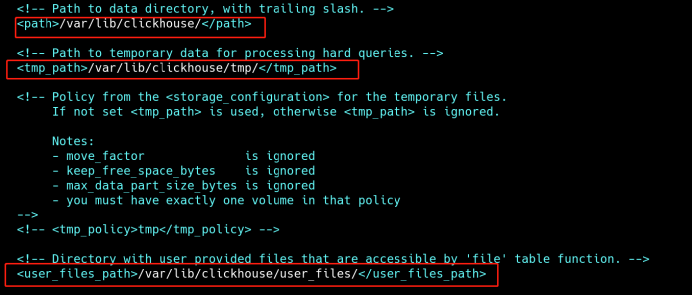
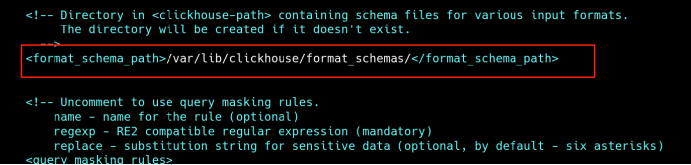
4、修改数据、日志目录
vi /etc/clickhouse-server/config.xml
5、创建相关目录
只需创建log文件目录即可
mkdir /bigdata/clickhouse
mkdir /bigdata/clickhouse/log
chown clickhouse:clickhouse /bigdata/clickhouse
chown clickhouse:clickhouse /bigdata/clickhouse/log
6、启动
/etc/init.d/clickhouse-server start
/etc/init.d/clickhouse-server stop
7、登录
由于9000与其它服务端口冲突,故tcp端口更改为9011
clickhouse-client --host localhost --port 9011
二、集群版
1、修改配置文件(三分片、单副本)
分别在三个节点都创建文件,红色字体每个节点配置不一样
vim /etc/metrika.xml
<yandex>
<clickhouse_remote_servers>
<cluster-01>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>spbsjzy19</host>
<port>9011</port>
<user>rt</user>
<password>SPBsjzy@)@)</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>spbsjzy20</host>
<port>9011</port>
<user>rt</user>
<password>SPBsjzy@)@)</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>spbsjzy21</host>
<port>9011</port>
<user>rt</user>
<password>SPBsjzy@)@)</password>
</replica>
</shard>
</cluster-01>
</clickhouse_remote_servers>
<zookeeper-servers>
<node index="1">
<host>spbsjzy33</host>
<port>2181</port>
</node>
<node index="2">
<host>spbsjzy34</host>
<port>2181</port>
</node>
<node index="3">
<host>spbsjzy35</host>
<port>2181</port>
</node>
</zookeeper-servers>
<macros>
<cluster>cluster-01</cluster>
<shard>01</shard>
<replica>spbsjzy19</replica>
<!-- <shard>02</shard>
<replica>spbsjzy20</replica>
<shard>03</shard>
<replica>spbsjzy21</replica>
-->
</macros>
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
注意:
1) <macros> </macros>中的shard名
三个节点配置相同则在任意一个节点插入数据,其他节点都会查询到;不相同的话复制表之间数据不会同步(插入分布表,数据会随机分配到某个节点的复制表;插入任意一个节点的复制表,分布表可以查询到,其他节点复制表无法查到)
2) <macros> </macros>中 <cluster>表示集群名称,<shard>表示分片编号,<replica>表示副本标识,这里使用了cluster{cluster}-{shard}-{replica}的表示方式
3) <internal_replication>
如果设置为true,则往本地表写入数据时,总是写入到完整健康的副本里,然后由表自身完成复制,这就要求本地表是能自我复制的(推荐)。如果设置为false,则写入数据时,是写入到所有副本中。这时,是无法保证一致性的
4) <user></user><password></password>
添加完后使用默认default用户也可以查询分布表。
相关报错信息:
ru.yandex.clickhouse.except.ClickHouseException: ClickHouse exception, code: 516, host: spbsjzy20, port: 8123; Code: 516, e.displayText() = DB::Exception: Received from spbsjzy19:9011. DB::Exception: default: Authentication failed: password is incorrect or there is no user with such name. (version 20.3.6.40 (official build))
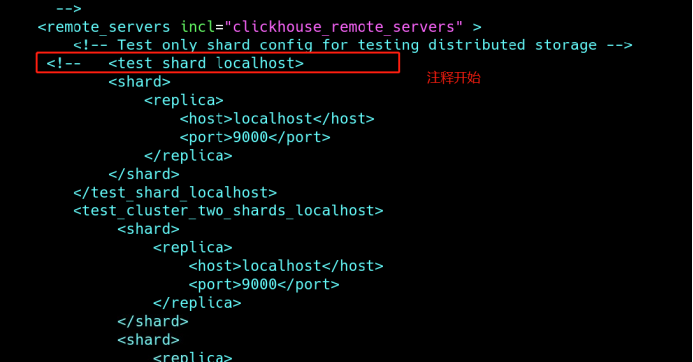
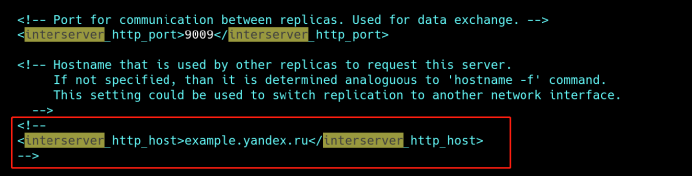
2、修改配置
vim /etc/clickhouse-server/config.xml
把注释打开,否则节点之间无法访问,分布表也无法查询其它节点数据
3、建议
生产中建议一般采用复制表和分布表;先创建复制表而后创建分布表,复制表用来存储数据,分布表用来查询和写入
ReplacingMergeTree:

4、创建表
分别在三个节点创建复制表:
分别在三个节点创建复制表:
CREATE TABLE default.test (`eventdate` Date, `company` String, `deliveryno` String, `usercardtype` String, `id` String, `name` String, `mob` String, `orgcode` String, `creditcode` String, `taxregno` String, `type` String, `cardid` String, `staffna` String, `staffmob` String, `staffaddress` String, `checkdate` String, `method` String, `address` String, `utcdate` DateTime DEFAULT now()) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/test', '{replica}', eventdate, (eventdate, company, deliveryno, id, mob, name), 8192)
在一个节点创建分布表:
CREATE TABLE default.test_all (`eventdate` Date, `company` String, `deliveryno` String, `usercardtype` String, `id` String, `name` String, `mob` String, `orgcode` String, `creditcode` String, `taxregno` String, `type` String, `cardid` String, `staffna` String, `staffmob` String, `staffaddress` String, `checkdate` String, `method` String, `address` String, `utcdate` DateTime DEFAULT now()) ENGINE = Distributed('{cluster}', 'default', 'test', rand())
5、插入表
insert into test(eventdate,company,deliveryno,id) VALUES('2020-12-05','ff','vv','xx');
insert into test_all(eventdate,company,deliveryno,id) VALUES('2020-12-06','xx','vv','xx');
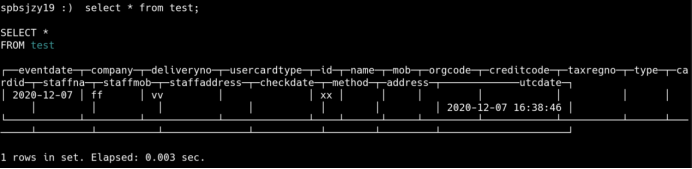
6、数据分布测试
(1)三张复制表分别执行
insert into test(eventdate,company,deliveryno,id) VALUES('2020-12-07','ff','vv','xx');
insert into test(eventdate,company,deliveryno,id) VALUES('2020-12-08','ff','vv','xx');
insert into test(eventdate,company,deliveryno,id) VALUES('2020-12-09','ff','vv','xx');
查询复制表:
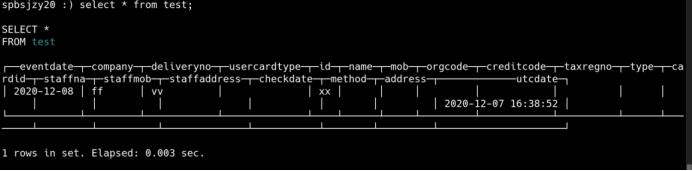
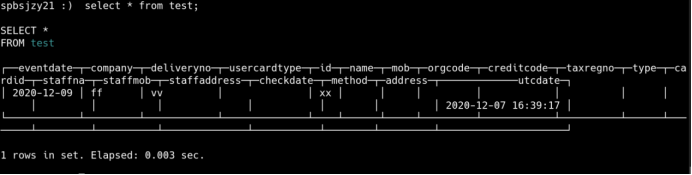
查询分布表
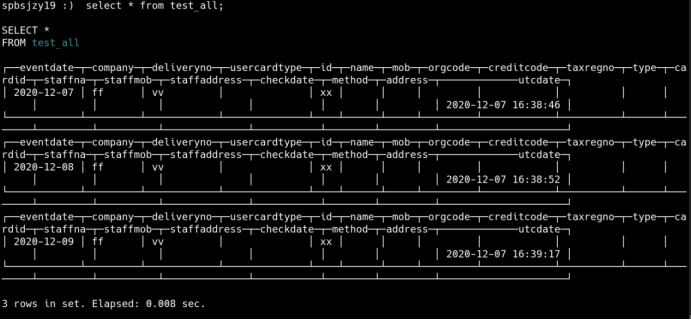
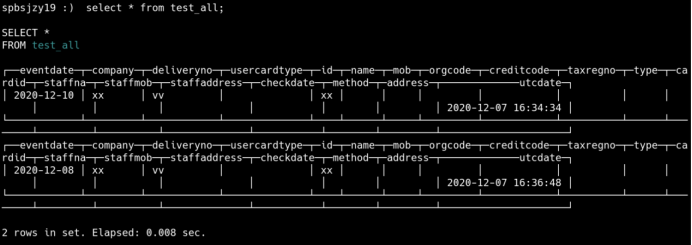
(2)插入分布表(随机分布)
insert into test_all(eventdate,company,deliveryno,id) VALUES('2020-12-07','xx','vv','xx');
insert into test_all(eventdate,company,deliveryno,id) VALUES('2020-12-08','xx','vv','xx');
查询复制表
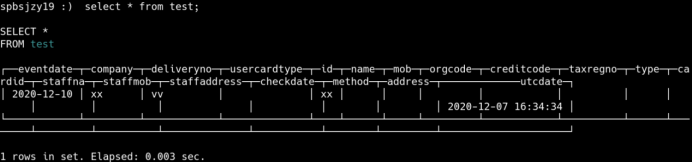
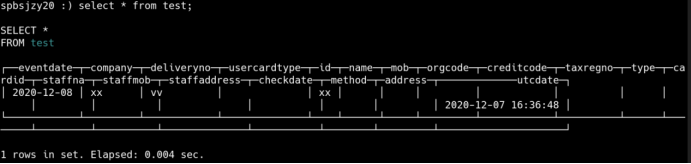
查询分布表
7、节点宕机测试
ClickHouse安装使用(单机、集群、高可用)的更多相关文章
- openstack pike 集群高可用 安装 部署 目录汇总
# openstack pike 集群高可用 安装部署#安装环境 centos 7 史上最详细的openstack pike版 部署文档欢迎经验分享,欢迎笔记分享欢迎留言,或加QQ群663105353 ...
- Rabbitmq集群高可用测试
Rabbitmq集群高可用 RabbitMQ是用erlang开发的,集群非常方便,因为erlang天生就是一门分布式语言,但其本身并不支持负载均衡. Rabbit模式大概分为以下三种:单一模式.普通模 ...
- 浅谈MySQL集群高可用架构
前言 高可用架构对于互联网服务基本是标配,无论是应用服务还是数据库服务都需要做到高可用.对于一个系统而言,可能包含很多模块,比如前端应用,缓存,数据库,搜索,消息队列等,每个模块都需要做到高可用,才能 ...
- bitmq集群高可用测试
Rabbitmq集群高可用 RabbitMQ是用erlang开发的,集群非常方便,因为erlang天生就是一门分布式语言,但其本身并不支持负载均衡. Rabbit模式大概分为以下三种:单一模式.普通模 ...
- mysql集群高可用架构
前言 高可用架构对于互联网服务基本是标配,无论是应用服务还是数据库服务都需要做到高可用.对于一个系统而言,可能包含很多模块,比如前端应用,缓存,数据库,搜索,消息队列等,每个模块都需要做到高可用,才能 ...
- hadoop+zookeeper集群高可用搭建
hadoop+zookeeper集群高可用搭建 Senerity 发布于 2 ...
- RabbitMQ从零到集群高可用(.NetCore5.0) -高可用集群构建落地
系列文章: RabbitMQ从零到集群高可用(.NetCore5.0) - RabbitMQ简介和六种工作模式详解 RabbitMQ从零到集群高可用(.NetCore5.0) - 死信队列,延时队列 ...
- Eureka 集群高可用配置.
SERVER:1 server: port: 1111 eureka: instance: hostname: ${spring.cloud.client.ip-address} instance-i ...
- 集群高可用之lvs+keepalive
集群高可用之lvs+keepalive keepalive简介: 负载均衡架构依赖于知名的IPVS内核模块,keepalive由一组检查器根据服务器的健康情况动态维护和管理服务器池.keepalive ...
- RabbitMQ从零到集群高可用(.NetCore5.0) - 死信队列,延时队列
系列文章: RabbitMQ从零到集群高可用(.NetCore5.0) - RabbitMQ简介和六种工作模式详解 RabbitMQ从零到集群高可用(.NetCore5.0) - 死信队列,延时队列 ...
随机推荐
- uni-app开发中的各种问题处理
特别注意: ※:在components下的组件,图片路径用 /static/img/back.png 这样的根路径形式,不要用../static 或者 ../../static 的形式,不然很坑, ...
- CAP、BASE、ACID
CAP定理 定义 CAP定理(CAP theorem),它指出对于一个分布式计算系统来说,不可能同时满足以下三点: 一致性(Consistency) (等同于所有节点访问同一份最新的数据副本:写操作之 ...
- vue 分支结构
分支循环结构 分支循环结构指令 v-if v-else v-else-if v-show v-if 指令 可以直接在元素中添加指令,添加判断的值 最后运行可以得到结果是: v-show v-show ...
- Spark内核-内存管理
Spark 集群会启动 Driver 和 Executor 两种 JVM 进程 我们只关注Executor的内存. 分为堆内内存和堆外内存 内存分为 存储内存 : 存储数据用的. 执行内存: 执行sh ...
- centos7安装Hive及其问题解决
本地如何安装hive (安装hive之前需要安装hadoop并启动hadoop的相关集群,mysql数据库) hadoop集群是两台,一台作为master,两台作为slaver,mysql单独占用一台 ...
- oracle rm -fr datafile 数据文件被误删的场景恢复(没有rman备份)
环境: Linux release 7.5 oracle19c (无pdb,从11.2.0.4升级上去的) 一:单个非系统表空间的数据文件被删除 我先备份一下,虽然是测试环境. [oracle@19c ...
- Python:值得学习的二十个技巧
本文为大家介绍20个值得记住的 Python 技巧,可以提升您编程技巧, 并为您节省大量时间. 在平常编程过程中,以下技巧大多非常有用. 1 字符串反转 使用切片反转字符串. str1="q ...
- MySQL中函数总结
SQL中提供的函数: version() 查询当前数据库版本 user() 查询当前登录用户 database() 查询当前所在数据库 uuid() 返回uuid的值,分布式情况下数据库 ...
- Jenkins自动化部署服务器及git 提交及git tag标签版本更新流程,超详细!
工作中部署的项目和服务器较多时就用上了Jenkins进行自动部署 优点 不用在连接单独的服务器进行更新项目,再启动项目服务的操作了 更新部署都是自动的,比较方便.适合大批量的部署 一.git流程部分 ...
- BOM主数据-用ECN实现可变BOM
用ECN变更号实现可变BOM:通过ECN变更号的参数类型来实现BOM的可变配置. 物料编号:2104 (1)首先BOM的父项物料主数据<基本数据1>必须设置栏位"参数有效值&qu ...