NOIP 2016 洛谷 P2827 蚯蚓 题解
题目描述
输入格式
输出格式
输入输出样例
样例输入一
样例输出一
样例输入二
样例输出二
样例输入三
//空行
样例输出三
说明/提示


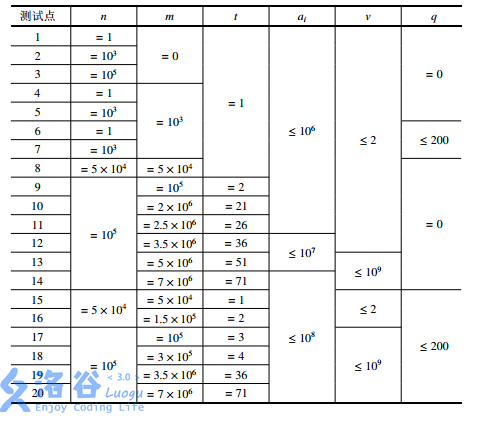
【数据范围】
分析
m的最大值已经达到了7e6,这道题我们如果直接枚举的话肯定会超时
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<iostream>
#include<queue>
using namespace std;
typedef long long ll;
const int maxn=+;
ll a[maxn];
bool cmp(ll aa,ll bb){ return aa>bb; }
priority_queue<ll> qq,xi,da;
int main(){
ll n,m,q,u,v,t;
scanf("%lld%lld%lld%lld%lld%lld",&n,&m,&q,&u,&v,&t);
for(ll i=;i<=n;i++){
scanf("%lld",&a[i]);
}
sort(a+,a++n,cmp);
ll head=,tail=n;
ll js=,ad=;
while(m--){
js++;
ll ans=-0x3f3f3f3f3f3f3f3f;
ll bb=ans,cc=ans,dd=ans;
if(!xi.empty()) bb=xi.top();
if(!da.empty()) cc=da.top();
if(head<=tail) dd=a[head];
ans=max(max(ans,bb),max(cc,dd));
if(ans==bb) xi.pop();
else if(ans==cc) da.pop();
else head++;
ans+=ad;
if(js%t==) printf("%lld ",ans);
ad=js*q;
ll left=u*ans/v;
ll right=ans-left;
left-=ad,right-=ad;
xi.push(min(left,right));
da.push(max(left,right));
}
printf("\n");
for(ll i=head;i<=tail;i++) {qq.push(a[i]);}
while(!xi.empty()) {qq.push(xi.top()),xi.pop();}
while(!da.empty()) {qq.push(da.top()),da.pop();}
ll cnt=;
while(!qq.empty()){
cnt++;
if(cnt%t==) printf("%lld ",qq.top()+ad);
qq.pop();
}
printf("\n");
return ;
}
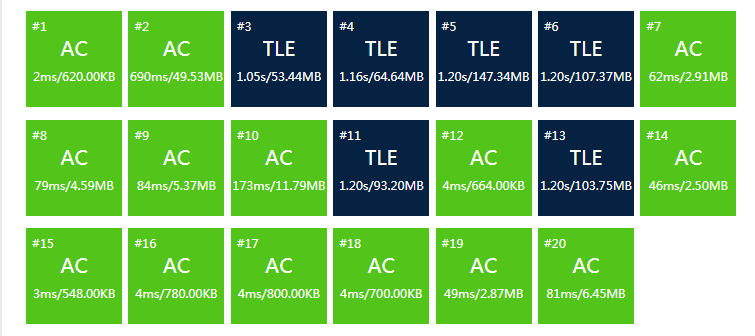
这样写T掉是必然的,因为你用优先队列的话,每次插入时间复杂度都为O(logn)
这样的效率肯定会有数据T掉
那么我们再仔细想想,发现其实是没有必要用优先队列的
因为我们每一次都是先把最长的蚯蚓切割,所以先切的蚯蚓一定长于后切的蚯蚓
所以先切的蚯蚓的较长的部分一定长于后切的蚯蚓较长的部分,所以先切的蚯蚓的较短的部分一定长于后切的蚯蚓较短的部分
所以用来储存切割后两部分的两个堆都具有单调性,因此我们可以用数组模拟,这样会快很多
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<iostream>
#include<queue>
using namespace std;
#define maxn 7000005
#define ll long long
ll a[maxn],xi[maxn],da[maxn];
bool cmp(ll aa,ll bb){ return aa>bb; }
int main(){
ll n,m,q,u,v,t;
scanf("%lld%lld%lld%lld%lld%lld",&n,&m,&q,&u,&v,&t);
for(register ll i=;i<=n;++i){
scanf("%lld",&a[i]);
}
sort(a+,a++n,cmp);
ll ha=,ta=n,hx=,hd=,tx=,td=;
ll js=,ad=;
ll mm=m;
while(mm--){
js++;
ll ans=-0x3f3f3f3f3f3f3f3f;
if(ha<=ta && a[ha]>=ans) ans=a[ha];
if(hx<=tx && xi[hx]>=ans) ans=xi[hx];
if(hd<=td && da[hd]>=ans) ans=da[hd];
if(a[ha]==ans && ha<=ta) ha++;
else if(xi[hx]==ans && hx<=tx) hx++;
else hd++;
ans+=ad;
if(js%t==) printf("%lld ",ans);
ll left=u*ans/v;
ll right=ans-left;
ad=js*q;
left-=ad,right-=ad;
xi[++tx]=min(left,right);
da[++td]=max(left,right);
}
printf("\n");
ll now=n+m;
for(ll i=;i<=now;++i){
ll ans=-0x3f3f3f3f3f3f3f3f;
if(ha<=ta && a[ha]>=ans) ans=a[ha];
if(hx<=tx && xi[hx]>=ans) ans=xi[hx];
if(hd<=td && da[hd]>=ans) ans=da[hd];
if(a[ha]==ans && ha<=ta) ha++;
else if(xi[hx]==ans && hx<=tx) hx++;
else hd++;
if(i%t==) printf("%lld ",ans+ad);
}
printf("\n");
return ;
}

这样的话,我们交到洛谷上可以过,但是在Vjudge上会T掉
于是,我又加上了读入优化、输出优化,以及register、inline等等,但发现还是会T

就像上面这样
后来我发现,其实没有必要写额外的读入优化、输出优化
一开始,我为了不炸int,把所有的变量都开成了long long
但实际上,有很多变量只用int就能解决,而且int比long long要快
只要把不必要的long long改成int就可以AC了

代码
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<iostream>
#include<queue>
using namespace std;
#define maxn 7000005
#define ll long long
int a[maxn];
ll xi[maxn],da[maxn];
int cmp(int aa,int bb){ return aa>bb; }
int main(){
int n,m,q,u,v,t;
scanf("%d%d%d%d%d%d",&n,&m,&q,&u,&v,&t);
for(int i=;i<=n;++i){
scanf("%d",&a[i]);
}
sort(a+,a++n,cmp);
int ha=,ta=n,hx=,hd=,tx=,td=;
ll js=,ad=;
int mm=m;
while(mm--){
js++;
ll ans=-0x3f3f3f3f3f3f3f3f;
if(ha<=ta && a[ha]>=ans) ans=a[ha];
if(hx<=tx && xi[hx]>=ans) ans=xi[hx];
if(hd<=td && da[hd]>=ans) ans=da[hd];
if(a[ha]==ans && ha<=ta) ha++;
else if(xi[hx]==ans && hx<=tx) hx++;
else hd++;
ans+=ad;
if(js%t==) printf("%lld ",ans);
ll left=u*ans/v;
ll right=ans-left;
ad=js*q;
left-=ad,right-=ad;
xi[++tx]=min(left,right);
da[++td]=max(left,right);
}
printf("\n");
int now=n+m;
for(int i=;i<=now;++i){
ll ans=-0x3f3f3f3f3f3f3f3f;
if(ha<=ta && a[ha]>=ans) ans=a[ha];
if(hx<=tx && xi[hx]>=ans) ans=xi[hx];
if(hd<=td && da[hd]>=ans) ans=da[hd];
if(a[ha]==ans && ha<=ta) ha++;
else if(xi[hx]==ans && hx<=tx) hx++;
else hd++;
if(i%t==) printf("%lld ",ans+ad);
}
printf("\n");
return ;
}
NOIP 2016 洛谷 P2827 蚯蚓 题解的更多相关文章
- 洛谷P2827 蚯蚓 题解
洛谷P2827 蚯蚓 题解 题目描述 本题中,我们将用符号 ⌊c⌋ 表示对 c 向下取整. 蛐蛐国最近蚯蚓成灾了!隔壁跳蚤国的跳蚤也拿蚯蚓们没办法,蛐蛐国王只好去请神刀手来帮他们消灭蚯蚓. 蛐蛐国里现 ...
- 洛谷p2827蚯蚓题解
题目 算法标签里的算法什么的都不会啊 什么二叉堆?? qbxt出去学习的时候讲的,一段时间之前做的,现在才写到博客上的 维护3个队列,队列1表示最开始的蚯蚓,队列2表示每一次被切的蚯蚓被分开的较长的那 ...
- 洛谷 P2827 蚯蚓 题解
每日一题 day32 打卡 Analysis 我们可以想一下,对于每一秒除了被切的哪一个所有的蚯蚓都增长Q米,我们来维护3个队列,队列1表示最开始的蚯蚓,队列2表示每一次被切的蚯蚓被分开的较长的那一部 ...
- 洛谷 P2827 蚯蚓 解题报告
P2827 蚯蚓 题目描述 本题中,我们将用符号 \(\lfloor c \rfloor\) 表示对 \(c\) 向下取整,例如:\(\lfloor 3.0 \rfloor = \lfloor 3.1 ...
- 洛谷——P2827 蚯蚓
P2827 蚯蚓 题目描述 本题中,我们将用符号 \lfloor c \rfloor⌊c⌋ 表示对 cc 向下取整,例如:\lfloor 3.0 \rfloor = \lfloor 3.1 \rflo ...
- 洛谷P2827 蚯蚓——思路题
题目:https://www.luogu.org/problemnew/show/P2827 思路... 用优先队列模拟做的话,时间主要消耗在每次的排序上: 能不能不要每次排序呢? 关注先后被砍的两条 ...
- 洛谷 P2827 蚯蚓
题目描述 本题中,我们将用符号\lfloor c \rfloor⌊c⌋表示对c向下取整,例如:\lfloor 3.0 \rfloor= \lfloor 3.1 \rfloor=\lfloor 3.9 ...
- 洛谷P2827 蚯蚓(单调队列)
题意 初始时有$n$个蚯蚓,每个长度为$a[i]$ 有$m$个时间,每个时间点找出长度最大的蚯蚓,把它切成两段,分别为$a[i] * p$和$a[i] - a[i] * p$,除这两段外其他的长度都加 ...
- 洛谷P2827蚯蚓
题目 堆+模拟,还有一个小优化(优化后跟堆关系不大,而是类似于贪心). 如果不加优化的话,卡常可以卡到85. 思路是对于对每一秒进行模拟,用堆来维护动态的最大值,然后对于每个长度都加q的情况可以用一个 ...
随机推荐
- 分享一个新出炉的JVM里不痛不痒的BUG(Attach机制相关)
本文来自: PerfMa技术社区 PerfMa(笨马网络)官网 概述 老早之前写过一篇文章,关于attach机制的,可以看下这篇老文章了解一下JVM源码分析之Attach机制实现完全解读,比如大家常用 ...
- 智能家居巨头 Aqara 基于 KubeSphere 打造物联网微服务平台
背景 从传统运维到容器化的 Docker Swarm 编排,从 Docker Swarm 转向 Kubernetes,然后在 Kubernetes 运行 SpringCloud 微服务全家桶,到最终拥 ...
- DES/3DES/AES 三种对称加密算法实现
1. 简单介绍 3DES(或称为Triple DES)是三重数据加密算法(TDEA,Triple Data Encryption Algorithm)块密码的通称.它相当于是对每个数据块应用三次DES ...
- Spring事务之@Transactional
参考源API : https://docs.spring.io/spring/docs/current/javadoc-api/ org.springframework.transaction.ann ...
- Censoring【KMP算法+堆栈模拟】
Censoring 传送门:链接 来源:UPC8203 题目描述 Farmer John has purchased a subscription to Good Hooveskeeping ma ...
- @Results用法总结
MyBatis中使用@Results注解来映射查询结果集到实体类属性. (1)@Results的基本用法.当数据库字段名与实体类对应的属性名不一致时,可以使用@Results映射来将其对应起来.col ...
- mysql日期和时间类型
TIME 类型 TIME 类型用于只需要时间信息的值,在存储时需要 3 个字节.格式为 HH:MM:SS.HH 表示小时,MM 表示分钟,SS 表示秒. TIME 类型的取值范围为 -838:59:5 ...
- Android学习笔记通过Toast显示消息提示框
显示消息提示框的步骤 这个很简单我就直接上代码了: Button show = (Button)findViewById(R.id.show); show.setOnClickListener(new ...
- 迁移AndroidX
1. 前言 AndroidX replaces the original support library APIs with packages in the androidx namespace. O ...
- S7-1200视频教程: S7-1200的功能与特点-跟我学 - 1/112
S7-1200视频教程: S7-1200的功能与特点-跟我学 - 1/112 观看连接: http://www.elearning.siemens.com.cn/video/Course/201012 ...