scrapy(一):基础用法
Scrapy 框架
Scrapy 简介
- Scray 是用python写的为了爬取网站数据,提取结构性数据的应用框架
Scrapy框架原理图
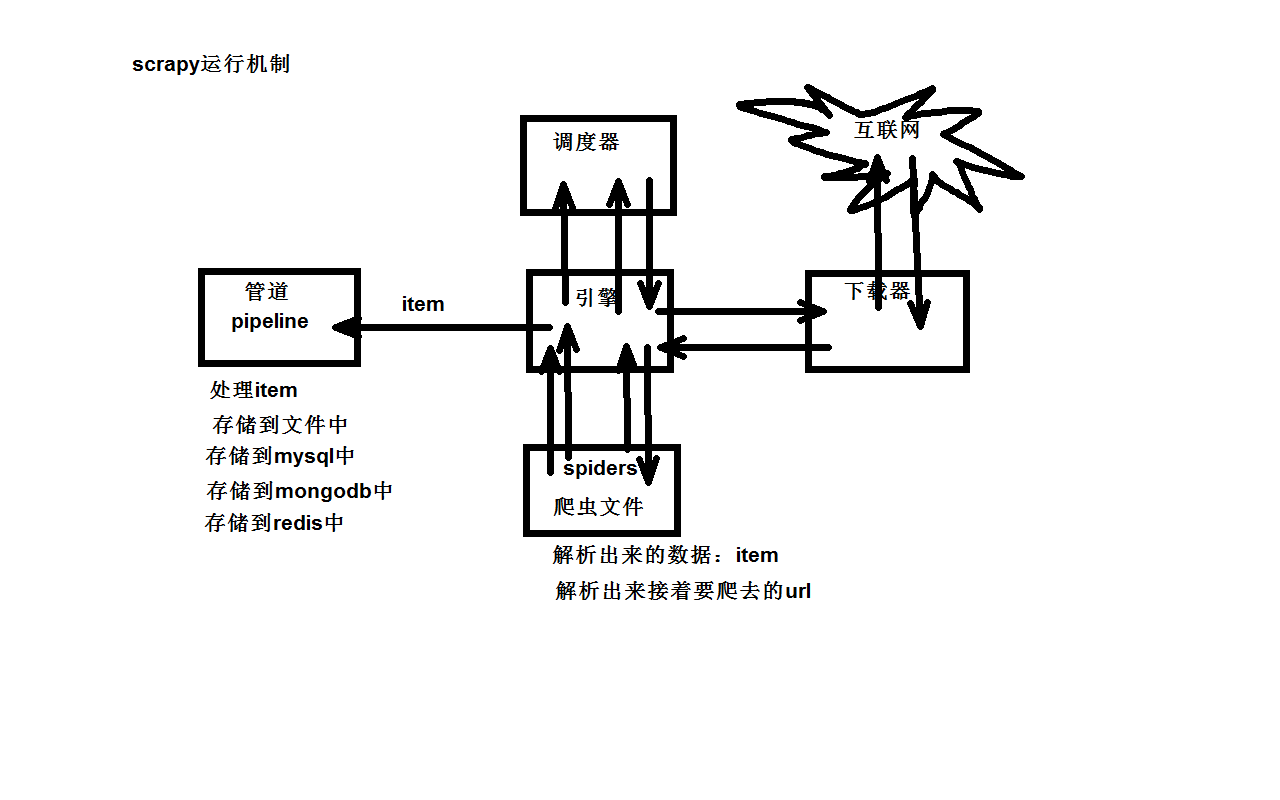
白话讲解Scrapy 运作流程
代码写好,程序开始运行...
- 引擎
:Hi!Spider`, 你要处理哪一个网站? Spider:老大要我处理xxxx.com。引擎:你把第一个需要处理的URL给我吧。Spider:给你,第一个URL是xxxxxxx.com。引擎:Hi!调度器,我这有request请求你帮我排序入队一下。调度器:好的,正在处理你等一下。引擎:Hi!调度器,把你处理好的request请求给我。调度器:给你,这是我处理好的request引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。引擎:Hi !管道我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。管道``调度器:好的,现在就做!
制作Scrapy爬虫步骤
1.新建项目
scrapy startproject mySpider
- 此时会出现一个目录结构(以下对各文件进行解释)
scrapy.cfg :项目的配置文件
mySpider/ :项目的Python模块,将会从这里引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ :存储爬虫代码目录```
2.制作爬虫
scrapy genspider ItCast www.itcast.cn
- 此时会创建一个 爬虫文件夹,打开ItCast.py 爬虫文件会看到以下代码:
class ItcastSpider(scrapy.Spider):
name = "itcast" #爬虫的名字
allowed_domains = ["itcast.cn"] # 是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。
start_urls = (
'http://www.itcast.cn/',
) # 爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成
def parse(self, response): # 解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数
pass
3. 明确目标(mySpider/items.py)
- 想要爬取那些信息,在Item里定义结构化数据字段,保存爬取到的数据
4.保存数据(pipelines.py)
- 在管道文件中设置保存数据的方法,可以保存到本地或者数据库
5.运行爬虫程序
一个简单例子
(1) items.py
- 想要爬取的信息
import scrapy
class ItcastItem(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
(2) itcastspider.py
- 写爬虫程序
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import scrapy
from mySpider.items import ItcastItem
# 创建一个爬虫类
class ItcastSpider(scrapy.Spider):
# 爬虫名
name = "itcast"
# 允许爬虫作用的范围
allowd_domains = ["http://www.itcast.cn/"]
# 爬虫其实的url
start_urls = [
"http://www.itcast.cn/channel/teacher.shtml#aandroid",
]
def parse(self, response):
#with open("teacher.html", "w") as f:
# f.write(response.body)
# 通过scrapy自带的xpath匹配出所有老师的根节点列表集合
teacher_list = response.xpath('//div[@class="li_txt"]')
# 遍历根节点集合
for each in teacher_list:
# Item对象用来保存数据的
item = ItcastItem()
# name, extract() 将匹配出来的结果转换为Unicode字符串
# 不加extract() 结果为xpath匹配对象
name = each.xpath('./h3/text()').extract()
# title
title = each.xpath('./h4/text()').extract()
# info
info = each.xpath('./p/text()').extract()
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
yield item
(3) setting.py 修改
ROBOTSTXT_OBEY = True
DOWNLOAD_DELAY = 4 #防止爬取过快丢失数据
DEFAULT_REQUEST_HEADERS = {
"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;",
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
}
ITEM_PIPELINES = {
'tencent.pipelines.TencentPipeline': 300,
}
(4) pipelines.py
- 数据保存到本地
# -*- coding: utf-8 -*-
import json
class ItcastPipeline(object):
# __init__方法是可选的,做为类的初始化方法
def __init__(self):
# 创建了一个文件
self.filename = open("teacher.json", "w")
# process_item方法是必须写的,用来处理item数据
def process_item(self, item, spider):
jsontext = json.dumps(dict(item), ensure_ascii = False) + "\n"
self.filename.write(jsontext.encode("utf-8"))
return item
# close_spider方法是可选的,结束时调用这个方法
def close_spider(self, spider):
self.filename.close()
(5)运行爬虫程序
scrapy crawl itcast
scrapy(一):基础用法的更多相关文章
- scrapy之基础概念与用法
scrapy之基础概念与用法 框架 所谓的框架就是一个项目的半成品.也可以说成是一个已经被集成了各种功能(高性能异步下载.队列.分布式.解析.持久化等)的具有很强通用性的项目模板. 安装 Linux: ...
- 小白学 Python 爬虫(35):爬虫框架 Scrapy 入门基础(三) Selector 选择器
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(38):爬虫框架 Scrapy 入门基础(六) Item Pipeline
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- PropertyGrid控件由浅入深(二):基础用法
目录 PropertyGrid控件由浅入深(一):文章大纲 PropertyGrid控件由浅入深(二):基础用法 控件的外观构成 控件的外观构成如下图所示: PropertyGrid控件包含以下几个要 ...
- logstash安装与基础用法
若是搭建elk,建议先安装好elasticsearch 来自官网,版本为2.3 wget -c https://download.elastic.co/logstash/logstash/packag ...
- elasticsearch安装与基础用法
来自官网,版本为2.3 注意elasticsearch依赖jdk,2.3依赖jdk7 下载rpm包并安装 wget -c https://download.elastic.co/elasticsear ...
- BigDecimal最基础用法
BigDecimal最基础用法 用字符串生成的BigDecimal是不会丢精度的. 简单除法. public class DemoBigDecimal { public static void mai ...
- Vue组件基础用法
前面的话 组件(Component)是Vue.js最强大的功能之一.组件可以扩展HTML元素,封装可重用的代码.根据项目需求,抽象出一些组件,每个组件里包含了展现.功能和样式.每个页面,根据自己所需, ...
- Smarty基础用法
一.Smarty基础用法: 1.基础用法如下 include './smarty/Smarty.class.php';//引入smarty类 $smarty = new Smarty();//实例化s ...
- 前端自动化测试神器-Katalon的基础用法
前言 最近由于在工作中需要通过Web端的功能进行一次大批量的操作,数据量大概在5000左右,如果手动处理, 完成一条数据的操作用时在20秒左右的话,大概需要4-5个人/天的工作量(假设一天8小时的工作 ...
随机推荐
- Qt自动生成.rc文件并配置对应属性 程序图标 版本 描述等
Qt项目配置文件pro里需要如下配置,进行qmake,build后会自动生成.rc文件,并将对应的信息写入文件中 VERSION = 1.0.0.1 RC_ICONS = "http.ico ...
- Ement 学习
<!DOCTYPE html><html lang="en"><head> <meta http-equiv="Content- ...
- PHP上传进度支持(Upload progress in sessions)
文件上传进度反馈, 这个需求在当前是越来越普遍, 比如大附件邮件. 在PHP5.4以前, 我们可以通过APC提供的功能来实现. 或者使用PECL扩展uploadprogress来实现. 从PHP的角度 ...
- jenkins环境安装(windows)
一.简介 Jenkins是一个开源软件项目,是基于Java开发的一种持续集成工具,用于监控持续重复的工作,旨在提供一个开放易用的软件平台,使软件的持续集成变成可能. 二. Jenkins功能 1. ...
- 消息队列——Kafka基本使用及原理分析
文章目录 一.什么是Kafka 二.Kafka的基本使用 1. 单机环境搭建及命令行的基本使用 2. 集群搭建 3. Java API的基本使用 三.Kafka原理浅析 1. topic和partit ...
- 基于docker-compose搭建gitlab
安装及配置 修改docker-compose文件 vim docker-compose.yml gitlab: image: 'gitlab/gitlab-ce:latest' restart: al ...
- Java并发编程的艺术(一、二章) ——学习笔记
第一章 并发编程的挑战 需要了解的一些概念 转自 https://blog.csdn.net/TzBugs/article/details/80921351 (1) 同步VS异步 同步和异步通常用来 ...
- ThinkPHP6 上传图片代码demo
本文展示了ThinkPHP6 上传图片代码demo, 代码亲测可用. HTML部分代码 <tr> <th class="font-size-sm" style=& ...
- 高性能IO —— Reactor(反应器)模式
讲到高性能IO绕不开Reactor模式,它是大多数IO相关组件如Netty.Redis在使用的IO模式, 为什么需要这种模式,它是如何设计来解决高性能并发的呢? 最最原始的网络编程思路就是服务器用一个 ...
- 【DP-动态代理】JDK&Cglib
需求:增强未知方法的代码 简单方案:继承或者聚合 继承,调用方法前后加增强逻辑 聚合 - 静态代理 持有被代理类对象 或者接口 可通过嵌套实现代理的组合 和 装饰器模式很像 高级方案 代理所有的类,不 ...