记一次svg反爬学习
网址:http://www.porters.vip/confusion/food.html
打开开发者工具后

页面源码并不是真实的数字,随便点一个d标签查看其样式
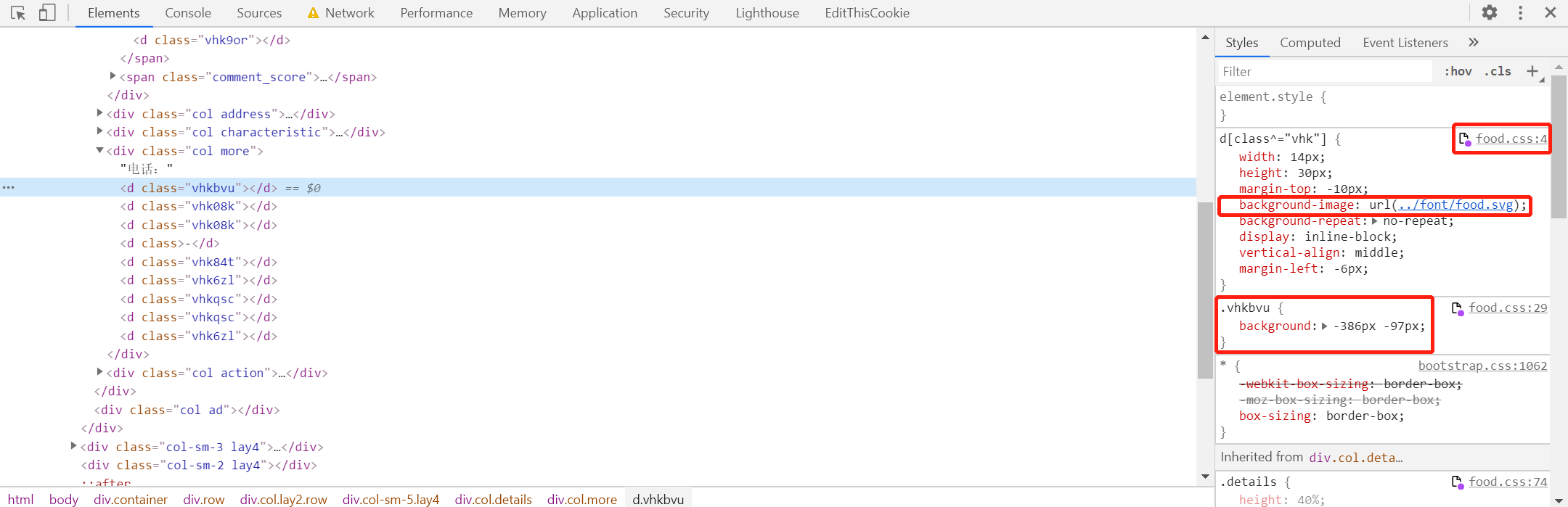
我们需要找到两个文件,food.css和food.svg文件,点开第一个红框会在Sources面板打开该文件,鼠标放到food.css文件名上,显示的就是food.css的地址
鼠标放到第二个红框的url上面,得到的就是food.svg的地址,也可以右键Copy link address获取地址
svg_url = 'http://www.porters.vip/confusion/font/food.svg'
css_url = 'http://www.porters.vip/confusion/css/food.css'
这里我们打开svg的地址后是这样的

我们会看到四行毫无规律的数字,查看源码发现又是一堆看着像加密的代码(其实不是,这里是svg-font的坐标)
然后打开css文件
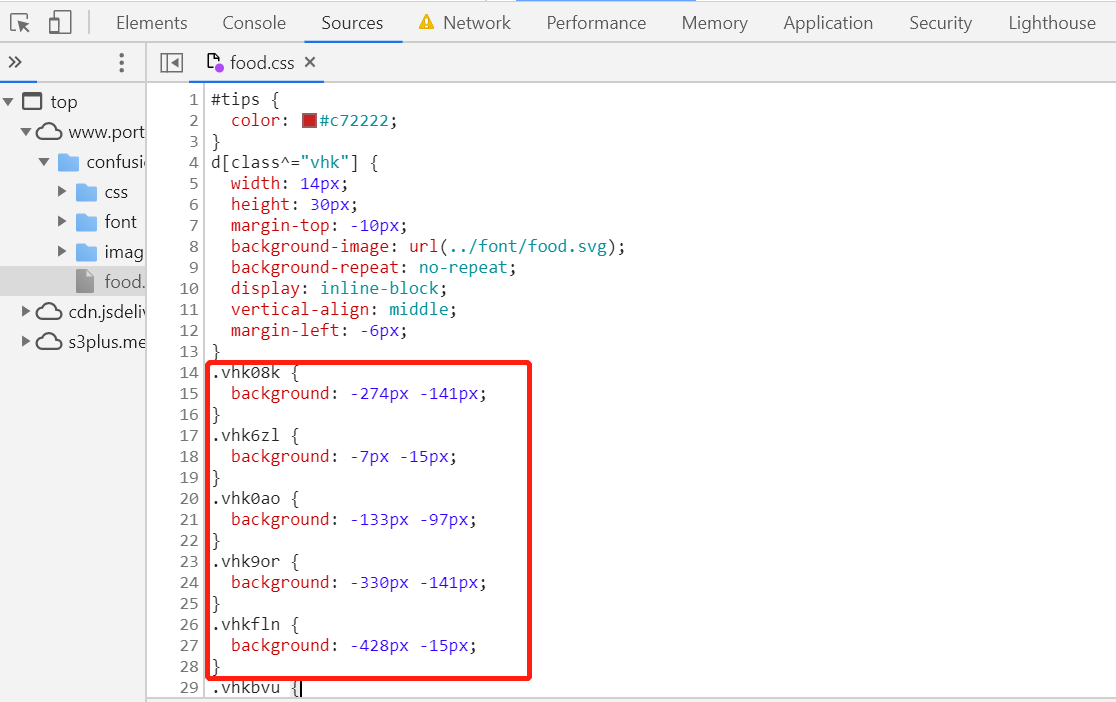
这里的background的css渲染数字的坐标
到此,需要解释一下为什么会有两个坐标,及字符定位的问题:
浏览器根据css样式中设定的坐标和元素宽高来确定svg中对应的数字。
接下来我们就只获取下面图中的电话号码
因为获取d标签的class属性比较容易,这里就简单构造一个电话号SVG列表
获取svg文件和css文件,以及构造电话号svg列表(这里比较简单,没什么解释的)
def get_file(url):
resp = requests.get(url=url)
content = resp.text
return content svg_url = 'http://www.porters.vip/confusion/font/food.svg'
css_url = 'http://www.porters.vip/confusion/css/food.css'
css_content = get_file(css_url)
svg_content = get_file(svg_url) # 获取源码中电话号的SVG列表
svg_list = ['vhkbvu', 'vhk08k', 'vhk08k', 'vhk84t', 'vhk6zl', 'vhkqsc', 'vhkqsc', 'vhk6zl']
for svg_name in svg_list:
print(svg_name)
...
在上一步,我们已经可以通过循环拿到每一个svg_name,接下来就是通过正则获取css文本中,对应的svg_name的样式(坐标)
def get_css_coordinates(css_content, svg_name):
res = re.findall('\.%s\s{\s+background:\s-(\d+)px\s-(\d+)px;\s}' % svg_name, css_content)
if bool(res):
x, y = res[0]
return (int(x), int(y))
得到css_x和css_y坐标后,拿着css_y坐标去定位上面svg文件中四行数字,获取css_x,css_y坐标对应的数字
from parsel import Selector
def get_svg_text_content(svg_content, css_y):
# 获取svg中字符的font-size属性,后面会用到
font_size = svg_content.split('font-size:')[1].split('px;')[0]
svg_data = Selector(svg_content)
# 获取svg文件 text元素的y属性列表
svg_y_list = svg_data.xpath('//text/@y').getall()
# 取到大于css_y且最近的一个
new_svg_y_list = [svg_y for svg_y in svg_y_list if css_y <= int(svg_y)]
# print(new_svg_y_list[0])
# 获取目标svg_y在原svg_y_list中的下标
index = svg_y_list.index(new_svg_y_list[0])
# print(svg_data.xpath('//text/text()').getall())
text_content = svg_data.xpath('//text/text()').getall()[index]
return text_content, font_size
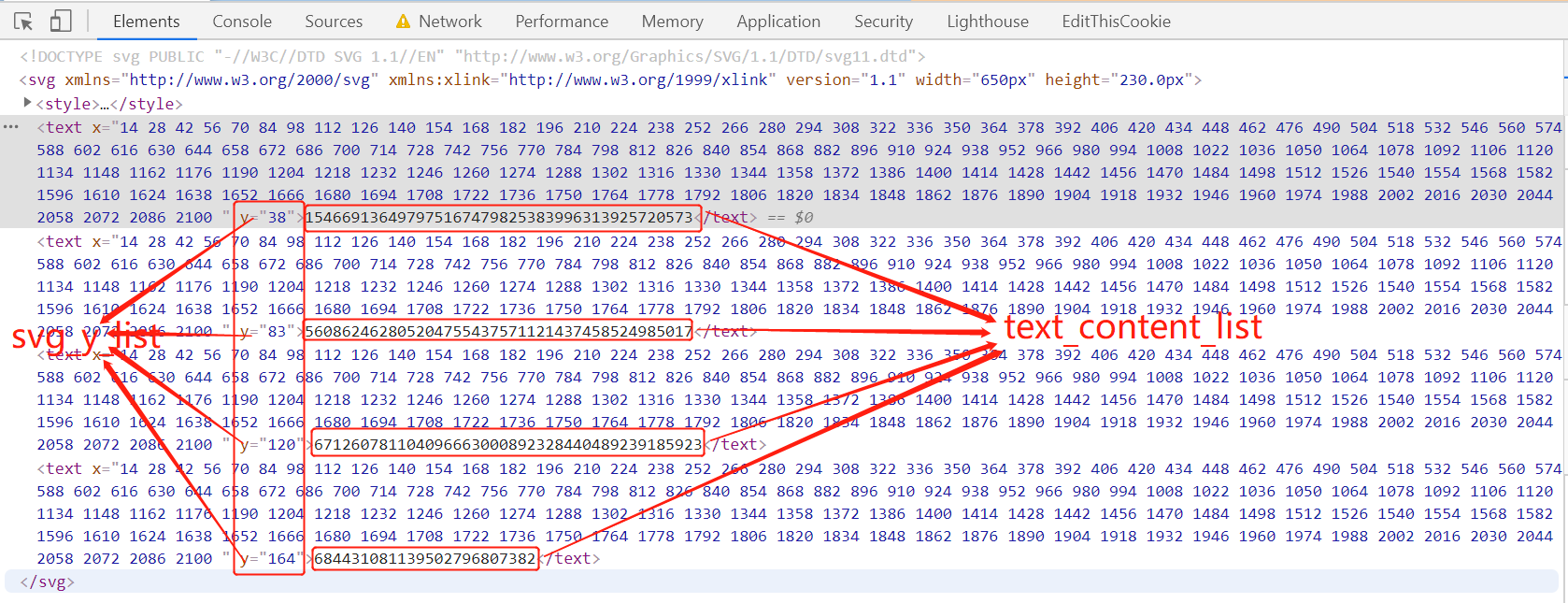
解释一下,在上面所示代码中,在电话号svg列表中第一个元素vhkbvu,对应的css_y的值为97,而我们获得的svg_y_list为 ['38', '83', '120', '164'],在此列表大于97且最近接的就是120,
因此我们确定svg_y的值为120,同时也确定了我们需要的是第三行数据,通过svg_y,也就是纵坐标的值已经确定
现在我们获取到了text_content为:671260781104096663000892328440489239185923,也就是上图中的第三个text标签中的文本,而font-size为14px
font-size也可以打开svg文件后找到style,查看里面font-size的值
下面我们来确定横坐标,横坐标确定后,我们就可以找到具体的数字值,从而完成破解
def get_char(text_content, css_x, font_size):
text_chars = list(text_content)
# 利用x轴的坐标确定是第几个元素
n = css_x // int(font_size)
print(text_chars[n])
return text_chars[n]
至此,我们的svg反爬破解完成,下面是完整代码
import requests
import re
from parsel import Selector def get_file(url):
resp = requests.get(url=url)
# print(resp.text)
content = resp.text
return content def get_css_coordinates(css_content, svg_name):
res = re.findall('\.%s\s{\s+background:\s-(\d+)px\s-(\d+)px;\s}' % svg_name, css_content)
if bool(res):
x, y = res[0]
return (int(x), int(y)) def get_svg_text_content(svg_content, css_y):
# 获取svg中字符的font-size属性,后面会用到
font_size = svg_content.split('font-size:')[1].split('px;')[0]
svg_data = Selector(svg_content)
# 获取svg文件 text元素的y属性列表
svg_y_list = svg_data.xpath('//text/@y').getall()
# 取到大于css_y且最近的一个
new_svg_y_list = [svg_y for svg_y in svg_y_list if css_y <= int(svg_y)]
# print(new_svg_y_list[0])
# 获取目标svg_y在原svg_y_list中的下标
index = svg_y_list.index(new_svg_y_list[0])
# print(svg_data.xpath('//text/text()').getall())
text_content = svg_data.xpath('//text/text()').getall()[index]
return text_content, font_size def get_char(text_content, css_x, font_size):
text_chars = list(text_content)
# 利用x轴的坐标确定是第几个元素
n = css_x // int(font_size)
print(text_chars[n])
return text_chars[n] def get_phone():
result = ''
svg_url = 'http://www.porters.vip/confusion/font/food.svg'
css_url = 'http://www.porters.vip/confusion/css/food.css'
css_content = get_file(css_url)
svg_content = get_file(svg_url) # 获取源码中电话号的SVG列表
svg_list = ['vhkbvu', 'vhk08k', 'vhk08k', 'vhk84t', 'vhk6zl', 'vhkqsc', 'vhkqsc', 'vhk6zl']
for svg_name in svg_list:
coordinate = get_css_coordinates(css_content, svg_name)
if coordinate is not None:
css_x, css_y = coordinate
print(css_x, css_y)
text_content, font_size = get_svg_text_content(svg_content, css_y)
num = get_char(text_content, css_x, font_size)
result += num
print(result) if __name__ == '__main__':
get_phone()
最后说明:此案例只是我在学习《Python3反爬虫原理与绕过实战》里面svg反爬的学习心得以及实践,供参考,不喜勿喷
记一次svg反爬学习的更多相关文章
- 字体反爬--css+svg反爬
这个验证码很恶心,手速非常快才能通过.. 地址:http://www.dianping.com/shop/9964442 检查一下看到好多字没有了,替代的是<x class="xxx& ...
- 记一次CSS反爬
目标网址:猫眼电影 主要流程 爬取每一个电影所对应的url 爬取具体电影所对应的源码 解析源码,并下载所对应的字体 使用 fontTools 绘制所对应的数字 运用机器学习的方法识别对应的数字 在源码 ...
- js反爬学习(一)谷歌镜像
1. url:https://ac.scmor.com/ 2. target:如下链接 3. 过程分析: 3.1 打开chrome调试,进行元素分析.随便定位一个“现在访问” 3.2 链接不是直接挂在 ...
- 记一次css字体反爬
前段时间在看css反爬的时候,发现很多网站都做了css反爬,比如,设置字体反爬的(58同城租房版块,实习僧招聘https://www.shixiseng.com/等)设置雪碧图反爬的(自如租房http ...
- Python爬虫入门教程 63-100 Python字体反爬之一,没办法,这个必须写,反爬第3篇
背景交代 在反爬圈子的一个大类,涉及的网站其实蛮多的,目前比较常被爬虫coder欺负的网站,猫眼影视,汽车之家,大众点评,58同城,天眼查......还是蛮多的,技术高手千千万,总有五花八门的反爬技术 ...
- 【Python3爬虫】大众点评爬虫(破解CSS反爬)
本次爬虫的爬取目标是大众点评上的一些店铺的店铺名称.推荐菜和评分信息. 一.页面分析 进入大众点评,然后选择美食(http://www.dianping.com/wuhan/ch10),可以看到一页有 ...
- k 近邻算法解决字体反爬手段|效果非常好
字体反爬,是一种利用 CSS 特性和浏览器渲染规则实现的反爬虫手段.其高明之处在于,就算借助(Selenium 套件.Puppeteer 和 Splash)等渲染工具也无法拿到真实的文字内容. 这种反 ...
- 【Python必学】Python爬虫反爬策略你肯定不会吧?
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 正文 Python爬虫反爬策略三部曲,拥有这三步曲就可以在爬虫界立足了: ...
- 破解另一家网站的反爬机制 & HMAC 算法
零.写在前面 本文涉及的反爬技术,仅供个人技术学习,禁止并做到: 干扰被访问网站的正常运行 抓取受到法律保护的特定类型的数据或信息 搜集到的数据禁止传播.交给第三方使用.或者牟利 如有可能,在爬到数据 ...
随机推荐
- html/css解决inline-block内联元素间隙的多种方法总汇
序 display有几种属性:inline是内联对象,比如<a/> . <span/>标签等,可以“堆在一起”显示,宽高由内容决定,不能设置:block是块对象,比如<d ...
- C#字符串拼接
var name = "李哈哈"; var t = $"我是{name}";
- rabbitmq部署及配置与验证
1. 场景描述 朋友项目需要弄个测试环境,稍微帮忙了下,系统不复杂,但是需要自己安装mysql.Reids.Es.RabbitMq等,Mq主要用在同步用户信息与发送站内消息和短信上,RabbitMq以 ...
- python分块读取大数据,避免内存不足
- 基层教师 - CMD命令之net命令与IPC连接
1)建立空连接: net use \\IP\ipc$ "" /user:"" (一定要注意:这一行命令中包含了3个空格) 2)建立非空连接: net use \ ...
- java规范总结
1.所有的相同类型的包装类对象之间值的比较,全部使用 equals 方法比较. 说明:对于 Integer var = ? 在-128 至 127 范围内的赋值,Integer 对象是在 Intege ...
- 数据可视化基础专题(十):Matplotlib 基础(二) 自定义配置文件和绘图风格(rcParams和style)
https://matplotlib.org/api/rcsetup_api.html#module-matplotlib.rcsetup 一.什么是rcParams?我们在使用matplotlibl ...
- 爬虫前篇 /https协议原理剖析
爬虫前篇 /https协议原理剖析 目录 爬虫前篇 /https协议原理剖析 1. http协议是不安全的 2. 使用对称秘钥进行数据加密 3. 动态对称秘钥和非对称秘钥 4. CA证书的应用 5. ...
- Unity-ECS(一)浅谈CPU缓存命中和Unity面向数据技术栈(DOTS)--笔记
一,缓存类型 概念:局部性. 时间局部性:当前用到的一个存储器位置,不久的将来会被用到. 空间局部性:当前用到的一个存储器位置,附近的位置会被用到. 那么在CPU的层面,这两个局部性的特性就会被Cac ...
- c++运行程序 改变字和背景的颜色与窗口大小和位置 (c++)(windows)
关于改变字体的颜色和背景颜色: 在#include <windows.h> 库里 0=黑色 1=蓝色 2=绿色 3=湖蓝色 4=红色 5=紫色 6=黄色 7=白色 8=灰色 9=淡蓝色 A ...