Python request 和response 初使用

request的get方法
r=request.get(url)构造一个向服务器请求资源的Request对象,
返回一个包含服务器资源的Response对象。
Request对象由Request库自动生成的。
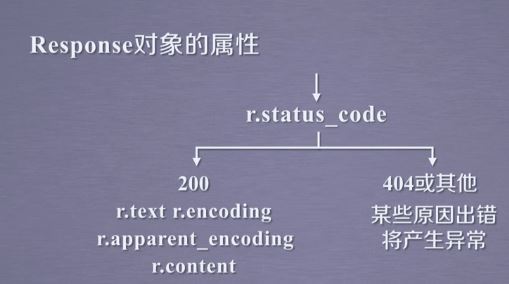
Response对象包含从服务器返回的所有相关资源
同时包含我们向服务器请求获得页面的request信息
request.get(url,params=None,**kwargs)
url:拟获取页面的url链接
params:url中的额外参数,字典或字节格式,可选
**kwargs:12个控制访问的参数
get方法源代码用request方法进行封装
request库提供了七个常用方法,除了第一个request方法是基础方法外
其他方法都是通过调用request方法来实现的
也可以这样认为:request库只由一个方法就是request方法
为了编写程序方便,提供了其他6个方法来调用request方法
request库的2个重要对象
r=requests.get(url)
使用request对象,返回response对象
response对象包含爬虫返回的全部内容
网络上的资源,他有他的编码
如果没有编码,我们将没办法用有效的解析方式使得人类可读这样的内容
r.encoding的编码方式是从Http header中charset字段获得的
如果Http header中有这样一个字段,说明我们访问的服务器对它资源的编码是有要求的
而这样的编码会获得回来存在r.encoding中
但不是所有的服务器对他的相关资源编码都是有这样的要求
如果header中不存在charset字段,则认为编码为ISO-8859-1
但是这样的编码并不能解析中文
所以Request库提供一个备选编码叫apparent_encoding
apparent_encoding做的事情是根据Http的内容部分(而不是头部分)
分析内容中出现文本的可能的编码形式
原则上来说,apparent_encoding比encoding更为准确
因为encoding并没有分析内容,他只是从header的相关字段中提取编码数
而apparent_encoding在分析内容且找到其中可能的编码
运用实例:
Python 3.6.5 (v3.6.5:f59c0932b4, Mar 28 2018, 17:00:18) [MSC v.1900 64 bit (AMD64)] on win32
Type "copyright", "credits" or "license()" for more information.
>>> import requests
>>> r = requests.get("http://www.baidu.com")
>>> print(r.status_code)
#在这里,如果返回的是200表示访问成功。如果不是200则出现了错误
200
>>> type(r)
<class 'requests.models.Response'>
>>> r.headers
{'Server': 'bfe/1.0.8.18', 'Date': 'Thu, 03 May 2018 23:52:26 GMT', 'Content-Type': 'text/html', 'Last-Modified': 'Mon, 23 Jan 2017 13:27:32 GMT', 'Transfer-Encoding': 'chunked', 'Connection': 'Keep-Alive', 'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Pragma': 'no-cache', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Content-Encoding': 'gzip'}
>>> r.text
'<!DOCTYPE html>\r\n<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>ç\x99¾åº¦ä后面不管是啥了,反正出现了乱码'
#由于出现乱码,查看一下编码
>>> r.encoding
'ISO-8859-1'
>>> r.apparent_encoding
'utf-8'
#改一下r.encoding编码
>>> r.encoding='utf-8'
>>> r.text
'<!DOCTYPE html>\r\n<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head>'乱码已修改好
>>>


Python request 和response 初使用的更多相关文章
- python的scrapy框架的使用 和xpath的使用 && scrapy中request和response的函数参数 && parse()函数运行机制
这篇博客主要是讲一下scrapy框架的使用,对于糗事百科爬取数据并未去专门处理 最后爬取的数据保存为json格式 一.先说一下pyharm怎么去看一些函数在源码中的代码实现 按着ctrl然后点击函数就 ...
- 【转】Django中的request与response对象
关于request与response 前面几个 Sections 介绍了关于 Django 请求(Request)处理的流程分析,我们也了解到,Django 是围绕着 Request 与 Respon ...
- 【Django】django 的request和response(转)
当请求一个页面时,Django 把请求的 metadata 数据包装成一个 HttpRequest 对象,然后 Django 加载合适的 view 方法,把这个 HttpRequest 对象作为第一个 ...
- Django中的Request和Response
接触Django这么久了,从来没有好好学习关于Django中的Request和Response对象.借着文件上传下载的相关工作,现在总结一下也不错. 当一个页面请求过来,Django会自动创建一个Re ...
- 二,Request和Response
概述 在DRF中,引入了一个Request和Response对象进行请求和响应,这两个对象分别继承于Djaong中常规的HttpRequest和SimpleTemplateResponse,相比其父类 ...
- Scrapy爬虫入门Request和Response(请求和响应)
开发环境:Python 3.6.0 版本 (当前最新)Scrapy 1.3.2 版本 (当前最新) 请求和响应 Scrapy的Request和Response对象用于爬网网站. 通常,Request对 ...
- DRF (Django REST framework) 中的Request 与 Response
DRF中的Request 与 Response 1. Request - REST framework 传入视图的request对象不再是Django默认的HttpRequest对象,而是REST f ...
- Python+Request库+第三方平台实现验证码识别示例
1.登录时经常的出现验证码,此次结合Python+Request+第三方验证码识别平台(超级鹰识别平台) 2.首先到超级鹰平台下载对应语言的识别码封装,超级鹰平台:http://www.chaojiy ...
- Request 和 Response 原理
* Request 和 Response 原理: * request对象和response对象由服务器创建,我们只需要在service方法中使用这两个对象即可 * 继承体系结构: ...
随机推荐
- BackgroundWorker 组件 -- 进度条
代码: BackgroundWorker bw = new BackgroundWorker(); public MainWindow() { InitializeComponent(); bw.Wo ...
- Robot Return to Origin
There is a robot starting at position (0, 0), the origin, on a 2D plane. Given a sequence of its mov ...
- 网站图片的轮播JS代码
这是几个网站的轮播JS效果,实现图片按照时间来切换,目前有几个站实现该功能,特别是浴室柜网站改版前,以下就是JS具体内容可以自己改下路径就可以用的linkarr = new Array();picar ...
- 23. Merge k Sorted Lists (JAVA)
Merge k sorted linked lists and return it as one sorted list. Analyze and describe its complexity. E ...
- 20175126《Java程序设计》第三学习总结
# 20175126 2016-2017-2 <Java程序设计>第三周学习总结 ##课余收获——利用JAVA编写最简单的斗地主程序 -由于最近身边的朋友都在玩手机上的斗地主小游戏,我也就 ...
- Month format:number to English abbre
``` DATA LV_MONTH TYPE FCKTX. CLEAR:LV_MONTH,lv_date. SELECT SINGLE KTX INTO LV_MONTH FROM T247 WHER ...
- 对palindrome的常用判断
判断String是否为palindrome:Two Pointers(left & right) 同时边扫边check 当前两边的char是否相同 code public boolean is ...
- 使用Spring Cache缓存出现的小失误
前文:今天在使用Spring Boot项目使用Cache中出现的小失误,那先将自己创建项目的过程摆出来 1.首先创建一个Spring Boot的项目(我这里使用的开发工具是Intellij IDEA) ...
- OO_多项式求导_单元总结
概述: 面向对象第一单元的作业是三次难度依次递增的多项式求导.第一次作业是仅包含带符号整数和幂函数的多项式求导,例如:-1+xˆ233-xˆ06:第二次是在前面的基础上增加了三角函数的求导,例如:-1 ...
- Google弃用HttpClient 而推荐使用HttpURLConnection的原因
因为兼容性问题,谷歌不愿意维护HttpClient,而使用HttpURLConnection HttpURLConnection的API包小而简便,更适合安卓 HttpURLConnection能够提 ...