Python图表数据可视化Seaborn:4. 结构化图表可视化
1.基本设置
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
% matplotlib inline sns.set_style("ticks")
sns.set_context("paper")
# 设置风格、尺度 import warnings
warnings.filterwarnings('ignore')
# 不发出警告
# 1、基本设置
# 绘制直方图 tips = sns.load_dataset("tips")
print(tips.head())
# 导入数据 g = sns.FacetGrid(tips, col="time", row="smoker")
# 创建一个绘图表格区域,设置好row、col并分组 g.map(plt.hist, "total_bill",alpha = 0.5,color = 'k',bins = 10)
# 以total_bill字段数据分别做直方图统计

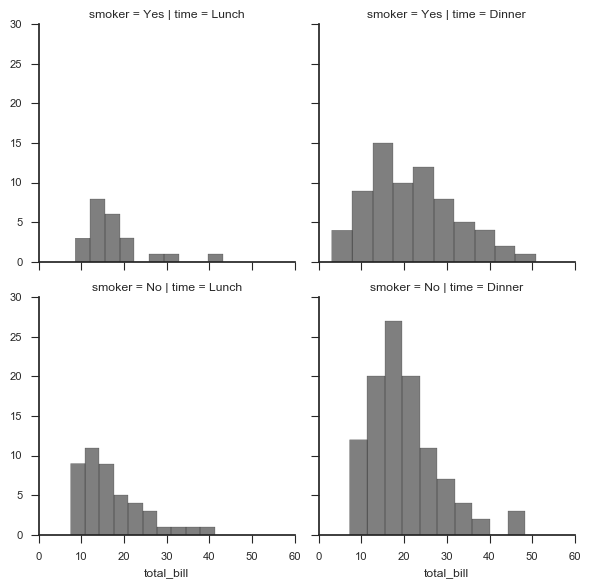
# 1、基本设置
# 绘制直方图 g = sns.FacetGrid(tips, col="day",
size=4, # 图表大小
aspect=.5) # 图表长宽比 g.map(plt.hist, "total_bill", bins=10,
histtype = 'step', #'bar', 'barstacked', 'step', 'stepfilled'
color = 'k')
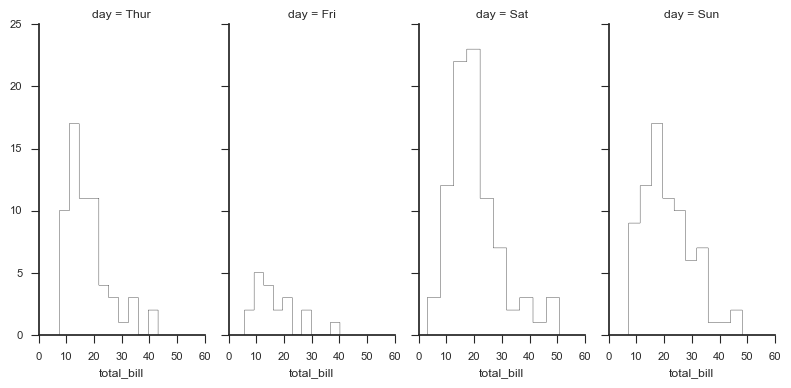
# 1、基本设置
# 绘制散点图 g = sns.FacetGrid(tips, col="time", row="smoker")
# 创建一个绘图表格区域,设置好row、col并分组 g.map(plt.scatter,
"total_bill", "tip", # share{x,y} → 设置x、y数据
edgecolor="w", s = 40, linewidth = 1) # 设置点大小,描边宽度及颜色
g.add_legend()
# 添加图例
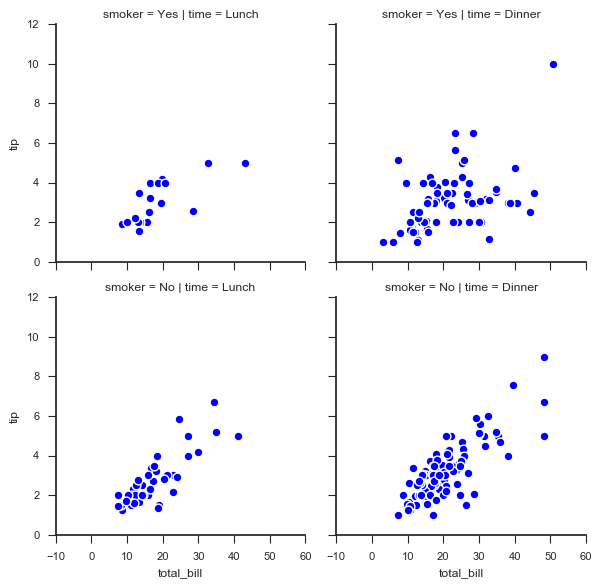
# 1、基本设置
# 分类 g = sns.FacetGrid(tips, col="time", hue="smoker")
# 创建一个绘图表格区域,设置好col并分组,按hue分类 g.map(plt.scatter,
"total_bill", "tip", # share{x,y} → 设置x、y数据
edgecolor="w", s = 40, linewidth = 1) # 设置点大小,描边宽度及颜色
g.add_legend()
# 添加图例
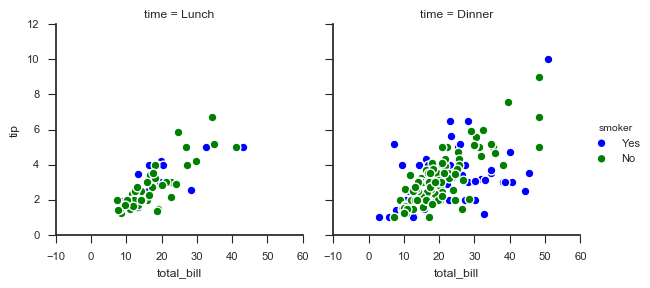
2. 图表矩阵
# 2、图表矩阵
attend = sns.load_dataset("attention")
print(attend.head())
# 加载数据
g = sns.FacetGrid(attend, col="subject", col_wrap=5, # 设置每行的图表数量
size=1.5)
g.map(plt.plot, "solutions", "score",
marker="o",color = 'gray',linewidth = 2)
# 绘制图表矩阵
g.set(xlim = (0,4),
ylim = (0,10),
xticks = [0,1,2,3,4],
yticks = [0,2,4,6,8,10]
)
# 设置x,y轴刻度

Python图表数据可视化Seaborn:4. 结构化图表可视化的更多相关文章
- seaborn线性关系数据可视化:时间线图|热图|结构化图表可视化
一.线性关系数据可视化lmplot( ) 表示对所统计的数据做散点图,并拟合一个一元线性回归关系. lmplot(x, y, data, hue=None, col=None, row=None, p ...
- 结构化数据(structured),半结构化数据(semi-structured),非结构化数据(unstructured)
概念 结构化数据:即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据. 半结构化数据:介于完全结构化数据(如关系型数据库.面向对象数据库中的数据)和完全无结构的数据(如声音.图像文件等)之 ...
- 结构化数据、半结构化数据、非结构化数据——Hadoop处理非结构化数据
刚开始接触Hadoop ,指南中说Hadoop处理非结构化数据,学习数据库的时候,老师总提结构化数据,就是一张二维表,那非结构化数据是什么呢?难道是文本那样的文件?经过上网搜索,感觉这个帖子不错 网址 ...
- 数据挖掘(二)用python实现数据探索:汇总统计和可视化
今天我们来讲一讲有关数据探索的问题.其实这个概念还蛮容易理解的,就是我们刚拿到数据之后对数据进行的一个探索的过程,旨在了解数据的属性与分布,发现数据一些明显的规律,这样的话一方面有助于我们进行数据预处 ...
- WordPress插件--WP BaiDu Submit结构化数据插件又快又全的向百度提交网页
一.WP BaiDu Submit 简介 WP BaiDu Submit帮助具有百度站长平台链接提交权限的用户自动提交最新文章,以保证新链接可以及时被百度收录. 安装WP BaiDu Submit后, ...
- H5中使用Web Storage来存储结构化数据
在上一篇对Web Storage的介绍中,可以看到,使用Storage保存key—value对时,key.value只能是字符串,这对于简单的数据来说已经够了,但是如果需要保存更复杂的数据,比如保存类 ...
- My SQL随记 001 常用名词/结构化语言
DBMS (Database Management System) 字段/域(列名或者列头 如:姓名身高性别为字段) 姓名 身高 性别 小周周 157 女 记录(一行数据 如:小周周 157 女 ) ...
- p2p gossip 结构化 非结构化
p2p P2P中文名字叫对等网络,网络中节点地位一致. QQ其实不算P2P,因为QQ利用了中央服务器. Hbase这样的分布式系统,因为有Hmaster节点,也不算是P2P网络: cas ...
- C# 添加、修改、删除Excel图表数据标签
图表中,图表数据标签以数据化形式表现图表中的特定数据,可增强图表的可读性.我们可以对图表添加数据标签,也可以对已有的数据标签进行修改或者删除,下面将通过C#代码形式来实现. 使用工具:Spire.XL ...
随机推荐
- Django 笔记(六)mysql增删改查
注:增删改查表数据在 views.py 内 添加表数据: 删表数据: 改表数据: 查表数据: 常用的查询方法: 常用的查询条件: 相当于SQL语句中的where语句后面的条件 语法:字段名__规则
- python-函数入门(二)
一.函数对象 什么是函数? 函数是第一类对象,指的是函数名指向的值(函数)可以被当做数据去使用 1.函数的特性 1.函数可以被引用,即函数可以把值赋值给一个变量 def foo(): print('f ...
- Confluence 6 配置管理员联系页面
管理员联系页面是一个格式化的页面,这个页面能够允许 Confluence 用户在 Confluence 中向管理员发送消息(在这部分的内容,管理员是默认管理员用户组的成员). 有关用户组的解释,请参考 ...
- Json数据和对象互转
1.创建UserTest类 package com.cppdy; public class UserTest { private String name; private String sex; pu ...
- java 命令行JDBC连接Mysql
环境:Windows10 + java8 + mysql 8.0.15 + mysql-connector-java-8.0.15.jar mysql驱动程序目录 项目目录 代码: //package ...
- MySQL----数据库简单操作
启动服务 net start mysql57断开服务 net stop mysql57连接服务 mysql -u root -p断开连接 exit|quit查看版本 select version(); ...
- Linux基础一:Linux的安装及相关配置
1. 计算机操作系统简介 1) 操作系统的定义:操作系统是一个用来协调.管理和控制计算机硬件和软件资源的系统程序,它位于硬件和应用程序之间. 2) 操作系统的内核的定义:操作系统的内核是一 ...
- js获取url协议、url, 端口号等信息路由信息
以路径为 http://www.baidu.com 为例 console.log("location:"+window.location.href); >> &quo ...
- 函数函数sigaction、signal
函数函数sigaction 1. 函数sigaction原型: int sigaction(int signum, const struct sigaction *act, struct sigact ...
- CentOS6.9安装HDFS
1.安装依赖包 yum install -y gcc openssh-clients 2.升级glib2.14 升级glibc-2.14用到的rpm 下载地址:https://pan.baidu.co ...