spark学习之路1--用IDEA编写第一个基于java的程序打包,放standalone集群,client和cluster模式上运行
1,首先确保hadoop和spark已经运行。(如果是基于yarn,hdfs的需要启动hadoop,否则hadoop不需要启动)。
2.打开idea,创建maven工程。编辑pom.xml文件。增加dependency.
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0</version>
</dependency>
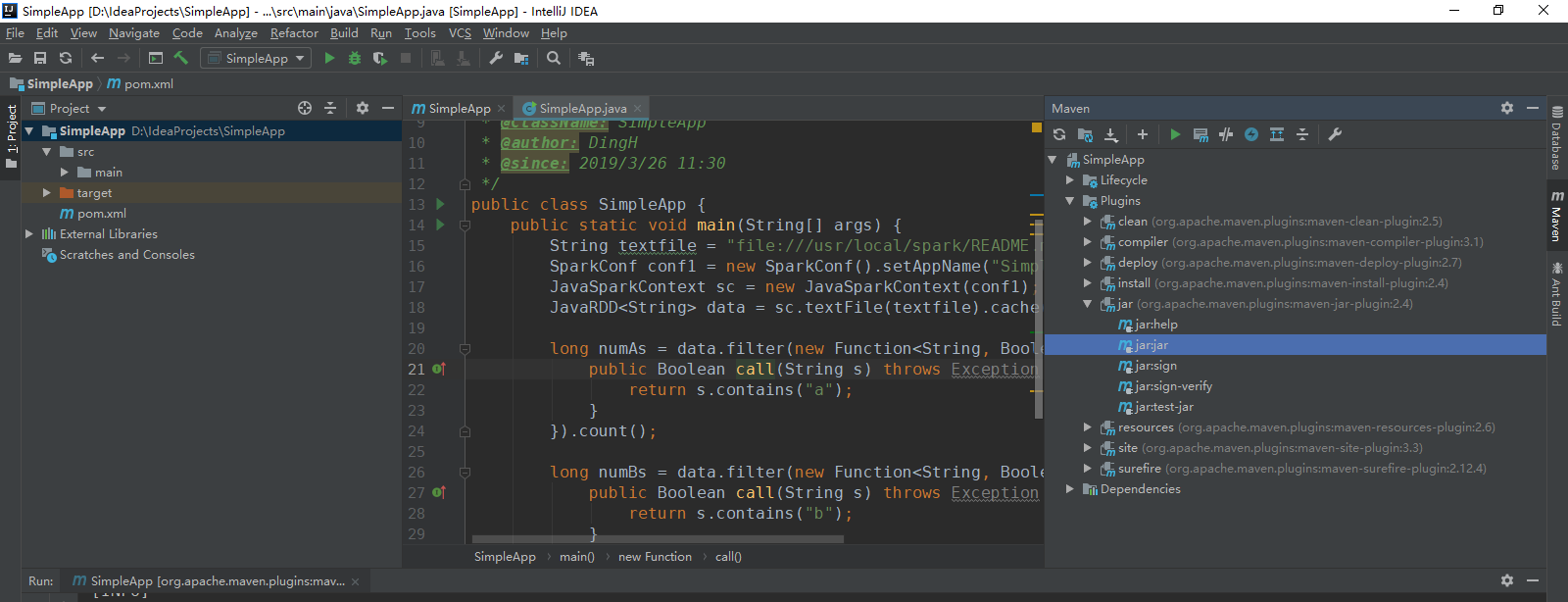
3.编写SimpleApp.java
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function; /**
* TODO
*
* @ClassName: SimpleApp
* @author: DingH
* @since: 2019/3/26 11:30
*/
public class SimpleApp {
public static void main(String[] args) {
String textfile = "file:///usr/local/spark/README.md";
SparkConf conf1 = new SparkConf().setAppName("SimpleApp");
JavaSparkContext sc = new JavaSparkContext(conf1);
JavaRDD<String> data = sc.textFile(textfile).cache(); long numAs = data.filter(new Function<String, Boolean>() {
public Boolean call(String s) throws Exception {
return s.contains("a");
}
}).count(); long numBs = data.filter(new Function<String, Boolean>() {
public Boolean call(String s) throws Exception {
return s.contains("b");
}
}).count(); System.out.println("Lines with a: " + numAs + ", lines with b: " + numBs);
}
}
4.执行程序(肯定会有错,因为这个路径是ubuntu上spark的readme文件路径,如果想要在本地实验,修改本地文件系统中的一个文件路径就行,这个同时还有conf.setmaster("local")),打包。
5.将目标路径下的target文件夹拷贝到服务器端。
6.如果是client模式,直接执行:
ubuntu@master:/usr/local/spark$ ./bin/spark-submit --class "SimpleApp" --deploy-mode client --master spark://172.19.57.221:7077 ~/target/SimpleApp-1.0-SNAPSHOT.jar

7.如果是cluster上,则需要把target上传到slave01的用户目录下。然后执行:
ubuntu@master:/usr/local/spark$ ./bin/spark-submit --class "SimpleApp" --deploy-mode cluster --master spark://172.19.57.221:7077 ~/target/SimpleApp-1.0-SNAPSHOT.jar
这个方式执行的结果只能在webUI上看。
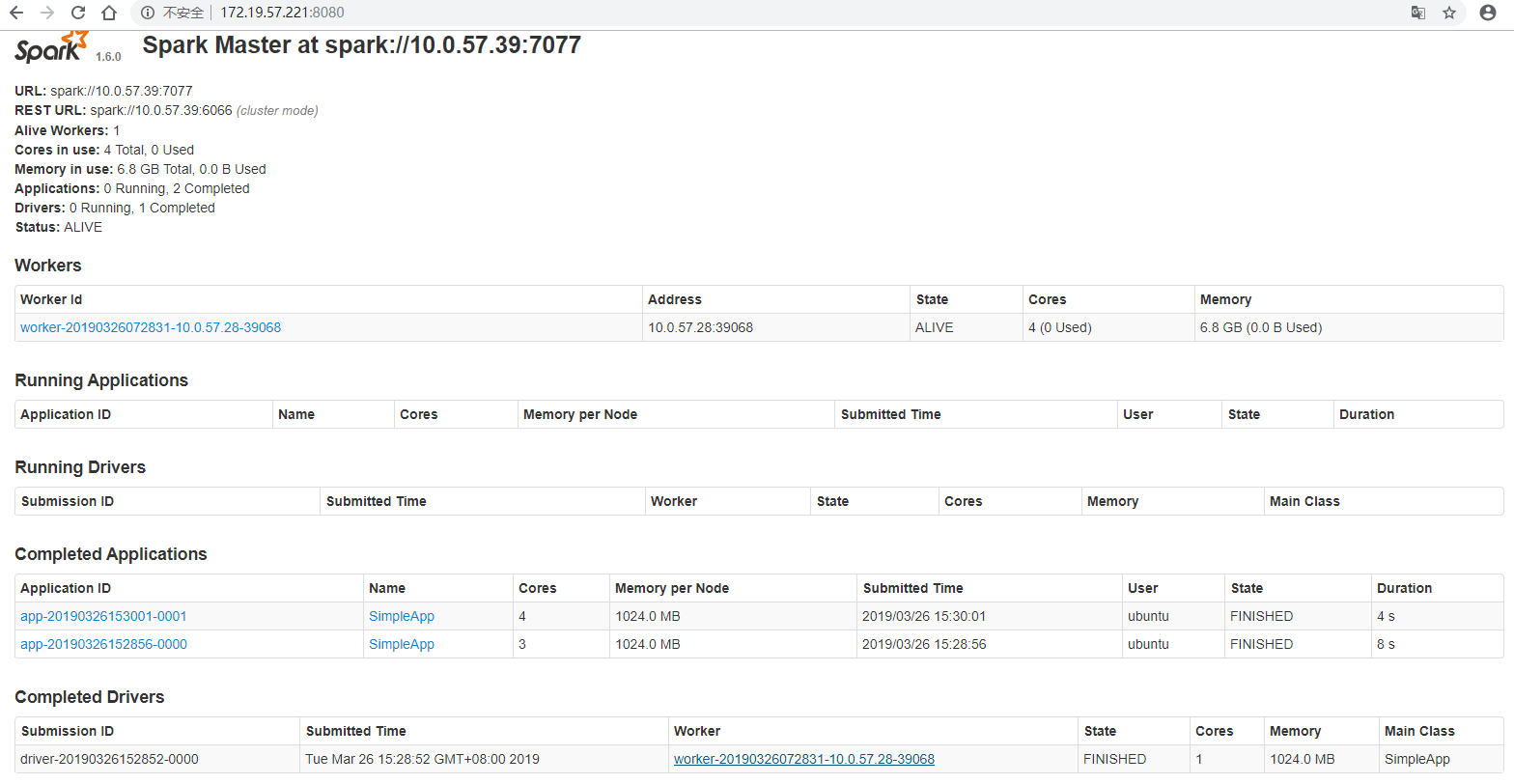
在http://172.19.57.221:8080/上,可以看到spark master。
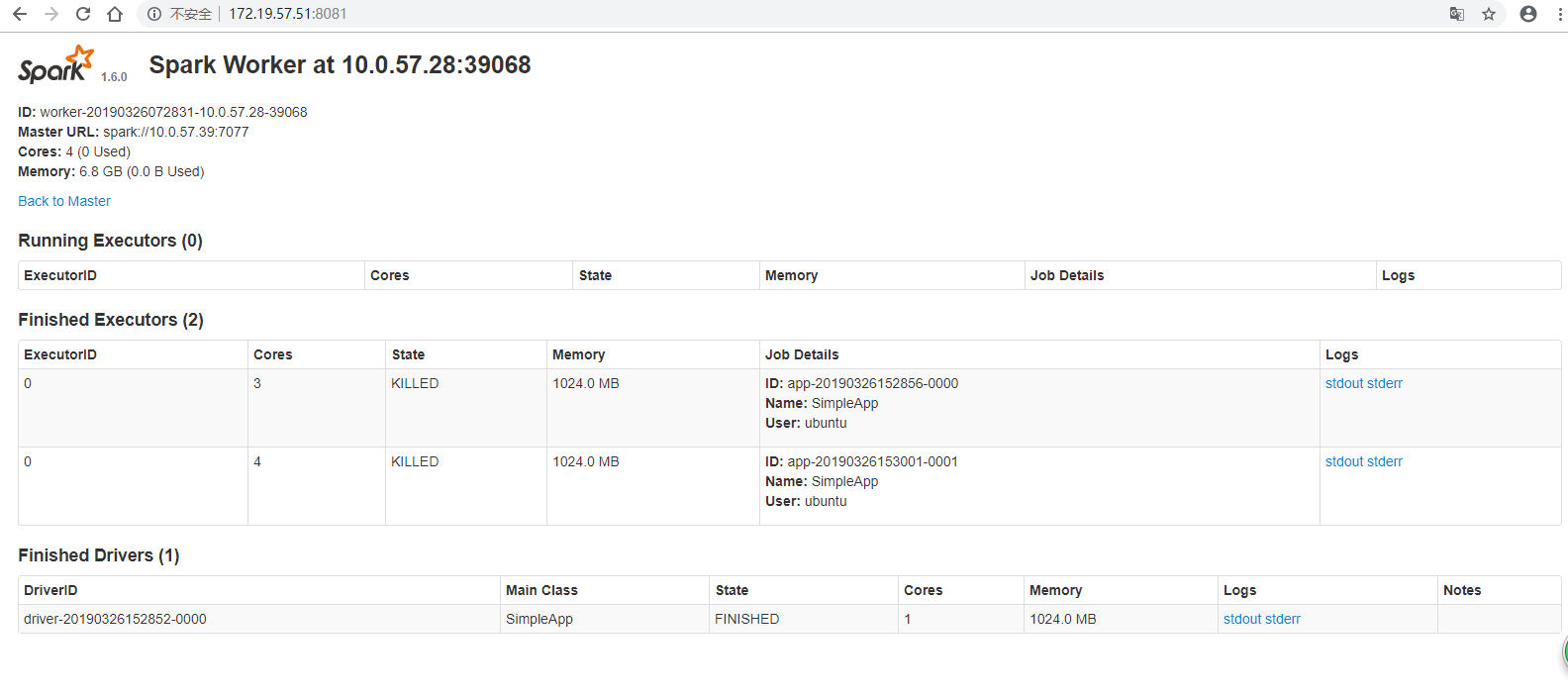
在http://172.19.57.51:8081/上,可以看到spark worker。
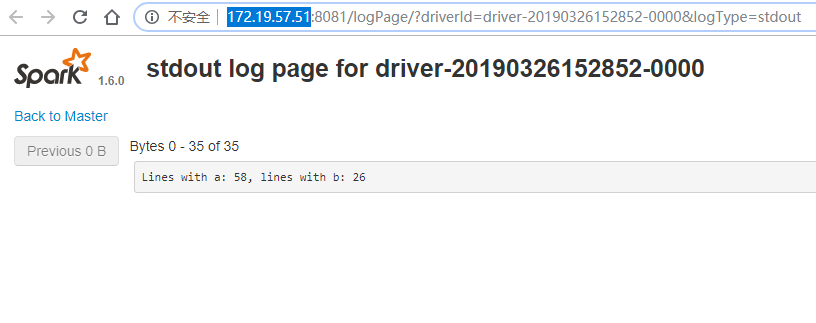
点击Finished Drivers里面的stdout就可以查看执行的结果。
完结~
spark学习之路1--用IDEA编写第一个基于java的程序打包,放standalone集群,client和cluster模式上运行的更多相关文章
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习之路 (十二)SparkCore的调优之资源调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 一.概述 在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都 ...
- Spark学习之路 (十二)SparkCore的调优之资源调优[转]
概述 在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都可以在spark-submit命令中作为参数设置.很多Spark初学者,通常不知道该设置哪些必要的参数,以及如 ...
- Spark学习之路 (八)SparkCore的调优之开发调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark ...
- Spark学习之路 (七)Spark 运行流程
一.Spark中的基本概念 (1)Application:表示你的应用程序 (2)Driver:表示main()函数,创建SparkContext.由SparkContext负责与ClusterMan ...
- Spark学习之路(七)—— 基于ZooKeeper搭建Spark高可用集群
一.集群规划 这里搭建一个3节点的Spark集群,其中三台主机上均部署Worker服务.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002和hadoop00 ...
- Spark学习之路(五)—— Spark运行模式与作业提交
一.作业提交 1.1 spark-submit Spark所有模式均使用spark-submit命令提交作业,其格式如下: ./bin/spark-submit \ --class <main- ...
- Spark学习之路(四)—— RDD常用算子详解
一.Transformation spark常用的Transformation算子如下表: Transformation算子 Meaning(含义) map(func) 对原RDD中每个元素运用 fu ...
- Spark学习之路 (八)SparkCore的调优之开发调优[转]
前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算操作 ...
随机推荐
- JS:判断是否是移动端
通过User-Agent判断 代码: if(navigator.userAgent.match(/mobile/i)) { //业务层代码 $('body').removeClass("si ...
- LuoGu P1541 乌龟棋
题目传送门 乌龟棋我并不知道他为啥是个绿题0.0 总之感觉思维含量确实不太高(虽然我弱DP)(毛多弱火,体大弱门,肥胖弱菊,骑士弱梯,入侵弱智,沙华弱Dp) 总之,设计出来状态这题就很简单了 设 f[ ...
- Android&Java面试题大全—金九银十面试必备
声明本文由作者:Man不经心授权转载,转载请联系原文作者原文链接:https://www.jianshu.com/p/375ad14096b3, 类加载过程 Java 中类加载分为 3 个步骤:加载. ...
- spring各版本jar包和源码
spring各版本jar包和源码 spring历史版本源码:https://github.com/spring-projects/spring-framework/tags spring历史jar包和 ...
- Confluence 6 重构 ancestor 表
ancestor 表记录了上级和下级(子页面)页面之间的关系.这个表格同时被用来确定子页面是否具有从上级页面继承来的限制(restrictions)权限. 偶尔 ancestor 表格中的数据可能被损 ...
- vue.js----之router详解(一)
在vue1.0版本的超链接标签还是原来的a标签,链接地址由v-link属性控制 而vue2.0版本里超链接标签由a标签被替换成了router-link标签,但最终在页面还是会被渲染成a标签的 至于为什 ...
- Socket网络编程(二)
udp协议发送消息案例 1.创建UdpServer(udp服务器端) package com.cppdy.udp; import java.net.DatagramPacket; import jav ...
- mysql 安装问题一:由于找不到MSVCR120.dll,无法继续执行代码.重新安装程序可能会解决此问题。
这种错误是由于未安装 vcredist 引起的 下载 vcredist 地址:https://www.microsoft.com/zh-CN/download/details.aspx?id= ...
- 给artDialog插件增加动画效果
领导想给弹窗增加几种动画效果,以前用过layer弹窗,效果不错,它的动画是用的样式,实现很简单,所以把动画拷贝了过来,打包到现在的artDialog.js里... 使用方式:新增配置参数{anim:4 ...
- LeetCode(108):将有序数组转换为二叉搜索树
Easy! 题目描述: 将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树. 本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1. 示例: 给定有序数组 ...