Spark学习之路(七)—— 基于ZooKeeper搭建Spark高可用集群
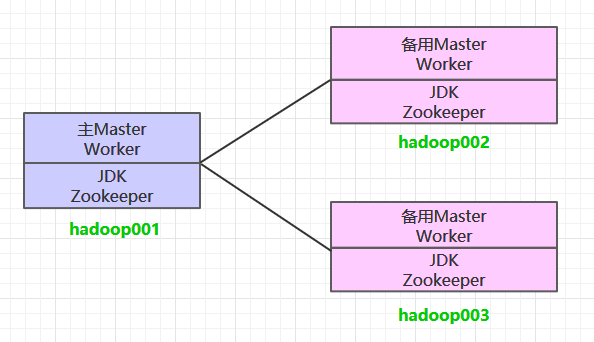
一、集群规划
这里搭建一个3节点的Spark集群,其中三台主机上均部署Worker服务。同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002和hadoop003上分别部署备用的Master服务,Master服务由Zookeeper集群进行协调管理,如果主Master不可用,则备用Master会成为新的主Master。
二、前置条件
搭建Spark集群前,需要保证JDK环境、Zookeeper集群和Hadoop集群已经搭建,相关步骤可以参阅:
三、Spark集群搭建
3.1 下载解压
下载所需版本的Spark,官网下载地址:http://spark.apache.org/downloads.html
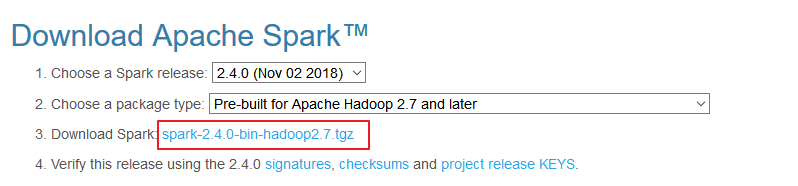
下载后进行解压:
# tar -zxvf spark-2.2.3-bin-hadoop2.6.tgz
3.2 配置环境变量
# vim /etc/profile
添加环境变量:
export SPARK_HOME=/usr/app/spark-2.2.3-bin-hadoop2.6
export PATH=${SPARK_HOME}/bin:$PATH
使得配置的环境变量立即生效:
# source /etc/profile
3.3 集群配置
进入${SPARK_HOME}/conf目录,拷贝配置样本进行修改:
1. spark-env.sh
cp spark-env.sh.template spark-env.sh
# 配置JDK安装位置
JAVA_HOME=/usr/java/jdk1.8.0_201
# 配置hadoop配置文件的位置
HADOOP_CONF_DIR=/usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop
# 配置zookeeper地址
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop001:2181,hadoop002:2181,hadoop003:2181 -Dspark.deploy.zookeeper.dir=/spark"
2. slaves
cp slaves.template slaves
配置所有Woker节点的位置:
hadoop001
hadoop002
hadoop003
3.4 安装包分发
将Spark的安装包分发到其他服务器,分发后建议在这两台服务器上也配置一下Spark的环境变量。
scp -r /usr/app/spark-2.4.0-bin-hadoop2.6/ hadoop002:usr/app/
scp -r /usr/app/spark-2.4.0-bin-hadoop2.6/ hadoop003:usr/app/
四、启动集群
4.1 启动ZooKeeper集群
分别到三台服务器上启动ZooKeeper服务:
zkServer.sh start
4.2 启动Hadoop集群
# 启动dfs服务
start-dfs.sh
# 启动yarn服务
start-yarn.sh
4.3 启动Spark集群
进入hadoop001的${SPARK_HOME}/sbin目录下,执行下面命令启动集群。执行命令后,会在hadoop001上启动Maser服务,会在slaves配置文件中配置的所有节点上启动Worker服务。
start-all.sh
分别在hadoop002和hadoop003上执行下面的命令,启动备用的Master服务:
# ${SPARK_HOME}/sbin 下执行
start-master.sh
4.4 查看服务
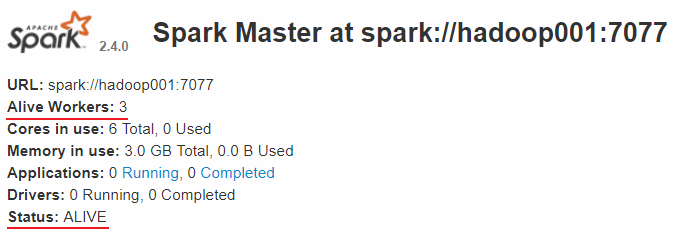
查看Spark的Web-UI页面,端口为8080。此时可以看到hadoop001上的Master节点处于ALIVE状态,并有3个可用的Worker节点。
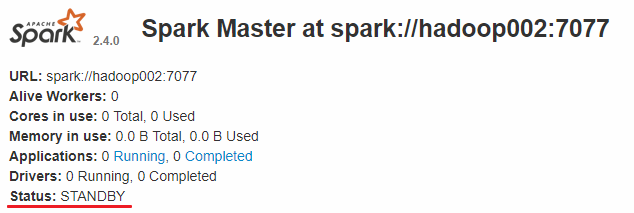
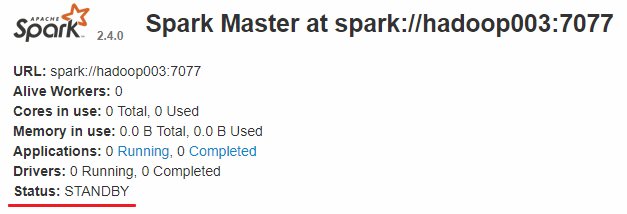
而hadoop002和hadoop003上的Master节点均处于STANDBY状态,没有可用的Worker节点。
五、验证集群高可用
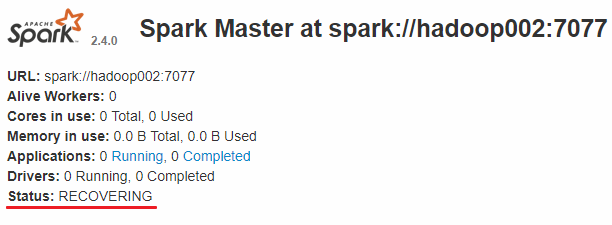
此时可以使用kill命令杀死hadoop001上的Master进程,此时备用Master会中会有一个再次成为主Master,我这里是hadoop002,可以看到hadoop2上的Master经过RECOVERING后成为了新的主Master,并且获得了全部可以用的Workers。
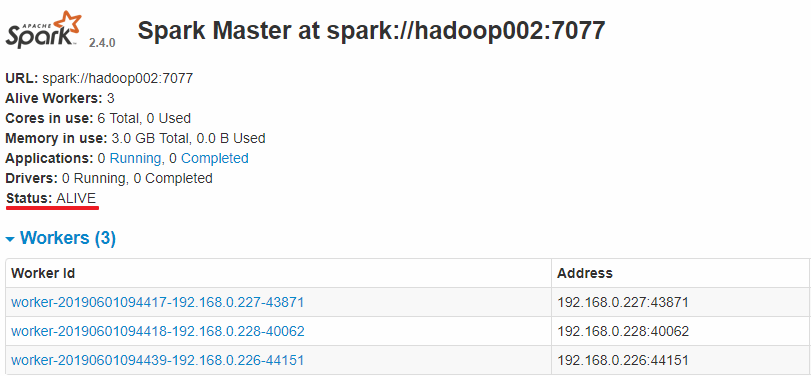
Hadoop002上的Master成为主Master,并获得了全部可以用的Workers。
此时如果你再在hadoop001上使用start-master.sh启动Master服务,那么其会作为备用Master存在。
六、提交作业
和单机环境下的提交到Yarn上的命令完全一致,这里以Spark内置的计算Pi的样例程序为例,提交命令如下:
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--executor-memory 1G \
--num-executors 10 \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Spark学习之路(七)—— 基于ZooKeeper搭建Spark高可用集群的更多相关文章
- Hadoop 学习之路(八)—— 基于ZooKeeper搭建Hadoop高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Kafka 学习之路(二)—— 基于ZooKeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本Zookeep ...
- 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 二.集群规划 三.前置条件 四.集群配置 五.启动集群 六.查看集群 七.集群的二次启动 一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS ...
- Hadoop 系列(八)—— 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Kafka —— 基于 ZooKeeper 搭建 Kafka 高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本Zookeep ...
- Kafka 系列(二)—— 基于 ZooKeeper 搭建 Kafka 高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- 入门大数据---基于Zookeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- 基于keepalived搭建MySQL高可用集群
MySQL的高可用方案一般有如下几种: keepalived+双主,MHA,MMM,Heartbeat+DRBD,PXC,Galera Cluster 比较常用的是keepalived+双主,MHA和 ...
- 基于Docker-compose搭建Redis高可用集群-哨兵模式(Redis-Sentinel)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_110 我们知道,Redis的集群方案大致有三种:1)redis cluster集群方案:2)master/slave主从方案:3) ...
- 基于docker实现redis高可用集群
基于docker实现redis高可用集群 yls 2019-9-20 简介 基于docker和docker-compose 使用redis集群和sentinel集群,达到redis高可用,为缓存做铺垫 ...
随机推荐
- Java编程思想里的泛型实现一个堆栈类
觉得作者写得太好了,不得不收藏一下. 对这个例子的理解: //类型参数不能用基本类型,T和U其实是同一类型. //每次放新数据都成为新的top,把原来的top往下压一级,通过指针建立链接. //末端哨 ...
- 用acharengine作Android图表
首先要下载acharengine的包,里面重要的有lib和一些简易的工具,等下我附在文件夹里,而这些包都必须调用的. 然后以下附上主要的作图代码: package org.achartengine.c ...
- A Byte of Python (for Python 3.0) 下载
在线阅读:http://www.swaroopch.org/notes/Python_en:Table_of_Contents 英文版 下载地址1:http://files.swaroopch.com ...
- AutoEncoder一些实验结果,并考虑
看之前Autoencoder什么时候,我做了一些练习这里:http://ufldl.stanford.edu/wiki/index.php/Exercise:Sparse_Autoencoder .其 ...
- 逻辑回归原理介绍及Matlab实现
原文:逻辑回归原理介绍及Matlab实现 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/laobai1015/article/details/781 ...
- CentOS6.8环境安装oracle 11G
本节所讲内容: oracle11g基础环境配置 数据库的三种安装方式(图形.静默.克隆) http://db-engines.com REDHAT6.5安装oracle11.2.4 ORACLE11G ...
- .net core注入服务
1.在Startup的ConfigureServices里面,通过IServiceCollection进行注入 public void ConfigureServices(IServiceCollec ...
- 最简单的IdentityServer实现——IdentityServer
1.新建项目 新建ASP .Net Core项目IdentityServer.EasyDemo.IdentityServer,选择.net core 2.0 1 2 引用IdentitySer ...
- Win10《芒果TV》商店版更新v3.2.7:修复下载任务和会员下载权限异常
在第89届奥斯卡颁奖典礼,<爱乐之城>摘获最佳导演.女主.摄影等六项大奖,<月光男孩>爆冷获最佳影片之际,Win10版<芒果TV>迅速更新至v3.2.7,主要是修复 ...
- WPF使用WindowChrome实现自定义标题框功能
代码: <Window x:Class="WpfDemo.MainWindow" xmlns="http://schemas.microsoft.com/winfx ...