python爬虫学习之Scrapy框架的工作原理
一、Scrapy简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。 其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。这里贴出Scrapy框架官方中文文档的链接。
二、Scrapy架构概览
接下来的图展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示)。下面对每个组件都做了简单介绍,数据流如下所描述。
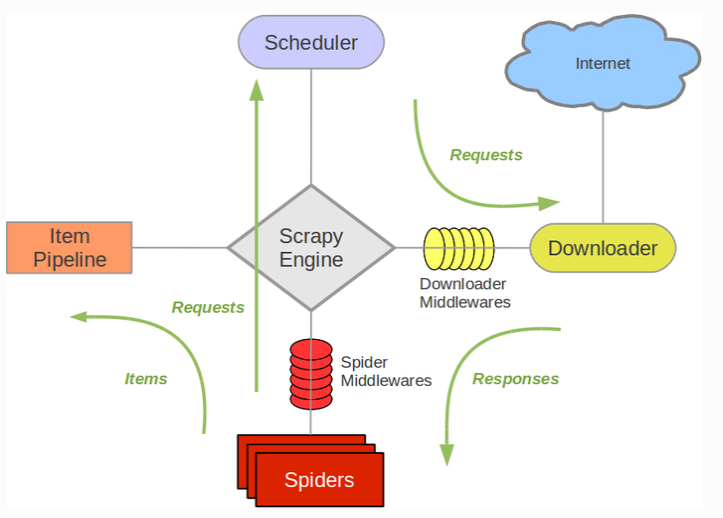
三、组件:
- Scrapy Engine:引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
- 调度器(Scheduler):调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
- 下载器(Downloader):下载器负责获取页面数据并提供给引擎,而后提供给spider。
- Spiders:Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
- Item Pipeline:Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
- 下载器中间件(Downloader middlewares):下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
- Spider中间件(Spider middlewares):Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能
四、数据流(Data flow):
Scrapy中的数据流由执行引擎控制,其过程如下:
1. 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
2. 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
3. 引擎向调度器请求下一个要爬取的URL。
4. 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
5. 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
6. 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
7. Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
8. 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
9. (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
python爬虫学习之Scrapy框架的工作原理的更多相关文章
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- Python爬虫-Scrapy框架的工作原理
Scrapy框架工作原理 Scrapy框架架构图 Scrapy框架主要由六大组件组成,分别为: 调度器(Scheduler),下载器(Downler),爬虫(Spiders),中间件(Middwa ...
- 零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- PYTHON 爬虫笔记十一:Scrapy框架的基本使用
Scrapy框架详解及其基本使用 scrapy框架原理 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- python 爬虫相关含Scrapy框架
1.从酷狗网站爬取 新歌首发的新歌名字.播放时长.链接等 from bs4 import BeautifulSoup as BS import requests import re import js ...
- Python爬虫知识点四--scrapy框架
一.scrapy结构数据 解释: 1.名词解析: o 引擎(Scrapy Engine)o 调度器(Scheduler)o 下载器(Downloader)o 蜘蛛(Spiders)o 项目管 ...
- 芝麻HTTP:Python爬虫进阶之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- 【Python爬虫实战】Scrapy框架的安装 搬运工亲测有效
windows下亲测有效 http://blog.csdn.net/liuweiyuxiang/article/details/68929999这个我们只是正确操作步骤详解的搬运工
随机推荐
- iview 路由权限判断的处理
主要是在main.vue做处理 其它地方不需要处理 menuList () { let getRouter = JSON.parse(sessionStorage.getItem('getUserDa ...
- Git实际操作
1.基本操作 git init 初始化仓库 git status 查看仓库状态 git add XXX.XX 向暂存区中添加文件XXX.XX git commit 保存仓库的历史记录 git log ...
- 聚簇索引(Clustered Index)和非聚簇索引 (Non- Clustered Index)
本文转自https://my.oschina.net/u/1866821/blog/297673 索引的重要性数据库性能优化中索引绝对是一个重量级的因素,可以说,索引使用不当,其它优化措施将毫无意义. ...
- 在MyEclipse中使用spring-boot+mybatis+freemarker实现基本的增删改查
一.基本环境 二.创建实体类 1.User.java package bjredcross.rainbowplans.model; import bjredcross.rainbowplans.com ...
- ICSE 2018 论文
仅简单分析自己感兴趣的论文. 9.6 Million Links in Source Code Comments: Purpose, Evolution, and Decay 分析了 source c ...
- Biopython 安装使用
Biopython 官网:https://biopython.org/ 安装 Biopython https://biopython.org/wiki/Download 可以使用 pip 进行安装, ...
- Play中JSON序列化
总的来说在scala体系下,对于习惯了java和c#这些常规开发的人来说,无论是akka-http还是play,就处理个json序列化与反序列化真他娘够费劲的. 根据经验,Json处理是比较简单的,但 ...
- 《Java并发编程的艺术》Java内存模型(三)
Java内存模型 一.Java内存模型的基础 1.并发编程模型的两个关键问题: 两个关键问题,线程之间如何通信和如何同步.两种方式,共享内存和消息传递.Java里线程的通信是通过共享内存,线程的同步是 ...
- godoc
Godoc-一个Go代码文档化工具 Python - Docstring Java - javadoc
- Intellij IDEA环境配置RestEasy,SpringMVC+RestEasy
在SpringMvc中配置RestEasy,需要以下步骤 1.通过maven导入restEasy所需要的jar包 2.在web.xml文件中添加相应的配置. 3.编写服务. 具体步骤: 1.通过mav ...