Matting任务里的Gradient与Connectivity指标
Matting任务里的Gradient与Connectivity指标
主要背景
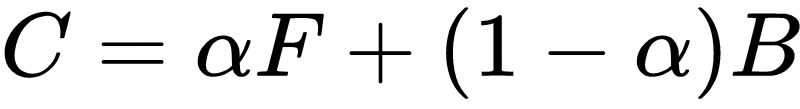
Matting任务就是把α(不透明度, 也就是像素属于前景的概率)、F(前景色)和B(背景色)三个变量给解出来.
C为图像当前可观察到的颜色, 这是已知的. 问题是一个等式解不出三个变量, 因此就必须引入额外的约束使这个方程可解, 这个额外的约束就是由用户指定的trimap(有人译为三元图)图, 或者是仅仅在前景和背景画几笔的草图(scribbles).
主要的手段
- 传统方法: Poisson Matting/Bayes Matting/Closed Form Matting/KNN Matting
- Color sampling方法, 以Bayesian Matting为代表, 通过对前景和背景的颜色采样构建高斯混合模型, 但是这种方法需
要高质量的trimap, 不易获取 - Propagation的方法, 根据像素亲和度将用户绘制的信息传播到不确定像素, 以Poisson Matting和KNN matting为代
表, 但是也不是自动抠图
- Color sampling方法, 以Bayesian Matting为代表, 通过对前景和背景的颜色采样构建高斯混合模型, 但是这种方法需
- CNN方法:
- Natural Image Matting Using Deep CNN(ECCV 2016)
- Deep Automatic Portrait Matting(ECCV 2016)
- Automatic Portrait Segmentation for Image Stylization(2016)
- Deep Image Matting(CVPR 2017)
- Semantic Human Matting(2018)等
主要评价指标
来自于论文: Christoph Rhemann, Carsten Rother, Jue Wang, Margrit Gelautz, Pushmeet Kohli, Pamela Rott. A Perceptually Motivated Online Benchmark for Image Matting. Conference on Computer Vision and Pattern Recognition (CVPR), June 2009.
- Gradient
- Connectivity
- SAD
- MSE
一些相关的术语, 来自参考链接[1]
SAD(Sum of Absolute Difference)= SAE(Sum of Absolute Error)即绝对误差和
SATD(Sum of Absolute Transformed Difference)即hadamard变换后再绝对值求和
SSD(Sum of Squared Difference)= SSE(Sum of Squared Error)即差值的平方和
MAD(Mean Absolute Difference)= MAE(Mean Absolute Error)即平均绝对差值
MSD(Mean Squared Difference)= MSE(Mean Squared Error)即平均平方误差
大致内容
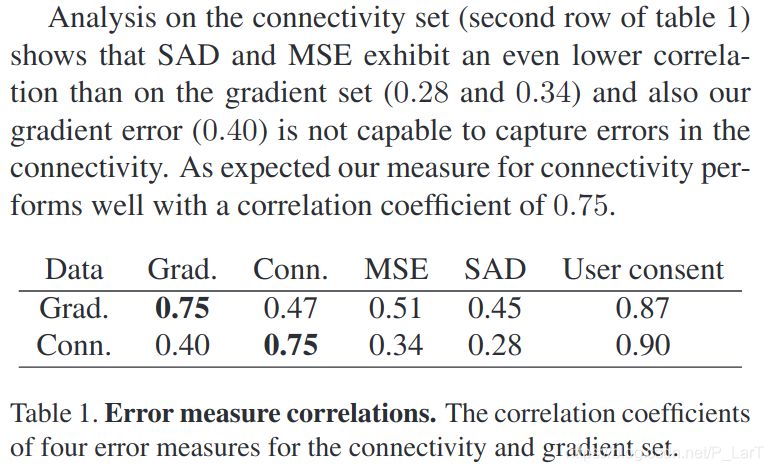
因为若是仅仅考虑SAD和MSE指标, 在和人类判断的对比中, 发现, 并不能很好地反映人类的实际判断标准. 为此文章引入了两个新的指标, 梯度和连通性. 先来说下连通性.
Connectivity
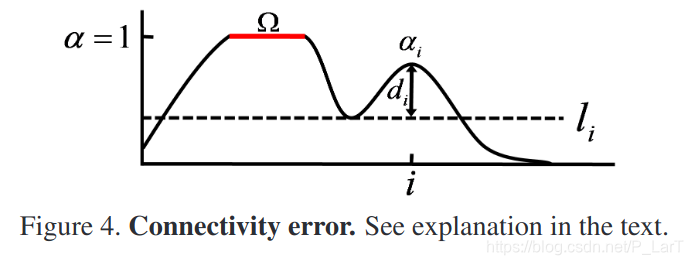
这个图基于matting任务中获得的alpha matte图, 这是一个灰度图, 表示的就是前面的公式里的\(\alpha\).
由于这里的图上出现了几个参数, $\alpha_i , \Omega, d_i, l_i, i$, 下面结合具体的公式来理解.
\[
\sum_{i}\left(\varphi\left(\alpha_{i}, \Omega\right)-\varphi\left(\alpha_{i}^{*}, \Omega\right)\right)^{p}
\]
这里的p是自定义参数. 具体见后.
该公式给出了连通性误差的计算方法, 这里是对整个预测出来的alpha matte图和对应的真值的图的对应的差异的累和. 这里的关键是里面的\(\varphi\left(\alpha_{i}, \Omega\right)\)函数.
首先要解释这里的\(\Omega\), 它表示的是对于预测结果图和真值共有的最大的值为1的连通区域, 被称为"源域(source region)", 也就是在上图中红线区域大致表示的范围. 这里的\(\varphi\)计算的是有着透明度\(\alpha_i\)的像素i, 与源域的连通度(degree of connectivity), 当其为1则认为该像素与源域全连通, 等于0表示完全不连通. 另一个加星号的表示真值图上的对应像素的连通度的计算. 二者计算差异, 来累计误差. 好的结果应该有着更低的误差, 更相似的连通情况.
公式里的\(l_i\)表示像素i四连通到源域所需要的最大阈值, 也就是上图中的虚线, 用它对alpha matte进行二值化, 正好处于使像素i与源域连通(实际需要四连通)/不连通的临界. 若是对于一个像素而言, 它的\(l=\alpha\), 那么就可以认为它与源域是全连通的.
而公式里的\(d_i\)如图所示, 表示的就是像素i处的\(\alpha\)值和对应的临界阈值\(l_i\)的差距.
\[
\varphi\left(\alpha_{i}, \Omega\right)=1-\left(\lambda_{i} \cdot \delta\left(d_{i} \geq \theta\right) \cdot d_{i}\right)
\]
这里的\(\theta\)是自定义参数, 具体见后. 它用在指示函数\(\delta\)里作为一个阈值, 来忽略小于它的\(d_i\)的情况, 认为小于它就已经是全连通了, 使得误差计算更为灵活.
其中的\(\lambda_{i}=\frac{1}{|K|} \sum_{k \in K} dist_{k}(i)\)用来对\(d_i\)进行加权, 这里的K表示\(l_i\)到\(\alpha_i\)之间的离散\(\alpha\)值的集合, \(dist_k\)计算了设置为阈值\(k\)时, 对于像素i距离最近的连通到源域的像素, 与像素i之间的标准化欧式距离. 实际情况中, 远离连通区域的像素, 获得的权重\(\lambda\)也应该相应会更大些, 这样导致得到的\(\varphi\)会更小些, 也就是认为连通度更小.
Gradient
主要计算的是预测的alpha matte \(\alpha\)和ground truth \(\alpha^{*}\)的之间的梯度差异, 定义如下:
\[
\sum_{i}\left(\nabla \alpha_{i}-\nabla \alpha_{i}^{*}\right)^{q}
\]
这里的q是自定义参数. 具体见后
这里的\(\nabla \alpha_{i}\)和\(\nabla \alpha_{i}^{*}\)表示的是对应的alpha matte的归一化梯度, 这是通过将matte与具有方差\(σ\)的一阶Gaussian导数滤波器进行卷积计算得到的. 二者计算差异, 进而累计损失. 总体越相似, 指标值越小.
这里的方差\(σ\)也是自定义参数, 具体见后
关于参数的选择
对于这里存在四个需要人工设置的参数: \(\theta, p, q\), 在参考文章3中, 有进一步的测试与设定, 文章最终选择了这样的设定: \(\sigma=1.4, q=2, \theta=0.15, p=1\).
参考文章
- https://zhidao.baidu.com/question/1701594942558730300.html
- http://alphamatting.com/index.html
- Christoph Rhemann, Carsten Rother, Jue Wang, Margrit Gelautz, Pushmeet Kohli, Pamela Rott. A Perceptually Motivated Online Benchmark for Image Matting. Conference on Computer Vision and Pattern Recognition (CVPR), June 2009.`
Matting任务里的Gradient与Connectivity指标的更多相关文章
- .Net内存泄露原因及解决办法
.Net内存泄露原因及解决办法 1. 什么是.Net内存泄露 (1).NET 应用程序中的内存 您大概已经知道,.NET 应用程序中要使用多种类型的内存,包括:堆栈.非托管堆和托管堆.这里我们需 ...
- Elasticsearch 聚合统计与SQL聚合统计语法对比(一)
Es相比关系型数据库在数据检索方面有着极大的优势,在处理亿级数据时,可谓是毫秒级响应,我们在使用Es时不仅仅进行简单的查询,有时候会做一些数据统计与分析,如果你以前是使用的关系型数据库,那么Es的数据 ...
- 转:.Net内存泄露原因及解决办法
1. 什么是.Net内存泄露 (1).NET 应用程序中的内存 您大概已经知道,.NET 应用程序中要使用多种类型的内存,包括:堆栈.非托管堆和托管堆.这里我们需要简单回顾一下. 以运行库为目标 ...
- 解决连锁零售行业IT运维管理四大困境
解决连锁零售行业IT运维管理四大困境 中国近年来,连锁零售行业进入了行业的发展高潮,迅速崛起一批大型连锁业态.而随着IT技术的不断进步,连锁零售企业已经步入IT信息化快速发展的重要阶段:在面对激烈 ...
- TOP100summit:【分享实录】链家网大数据平台体系构建历程
本篇文章内容来自2016年TOP100summit 链家网大数据部资深研发架构师李小龙的案例分享. 编辑:Cynthia 李小龙:链家网大数据部资深研发架构师,负责大数据工具平台化相关的工作.专注于数 ...
- Android 计算器
首先在activity_main.xml加入一个EditText 通过xml的方式来沈成一个图像在drawable中新建一个white_bg.xml文件,同时选择一个shape标签corners设置圆 ...
- CloudStack 4.3功能前瞻
今天CloudStack 4.3已经Feature Freeze了,不会再有新功能加入到这个版本里.我们也可以坐下来看看哪些功能是值得期待的.首先,4.3的UI也秉承扁平化设计,看着更加简洁清爽.见下 ...
- 解决Net内存泄露原因
Net内存泄露原因及解决办法 https://blog.csdn.net/changtianshuiyue/article/details/52443821 什么是.Net内存泄露 (1).NET 应 ...
- (转)Linux 系统性能分析工具图解读(一、二)
Linux 系统性能分析工具图解读(一.二) 原文:http://oilbeater.com/linux/2014/09/08/linux-performance-tools.html 最近看了 Br ...
随机推荐
- WPF 耗时操作时,加载loging 动画 (BackgroundWorker 使用方法)
1.定义一个全局 BackgroundWorker private System.ComponentModel.BackgroundWorker bgMeet0; 2.设置执行耗时的任务为True b ...
- NOIP 2018 Day1
Fei2Xue@Lian$Tian! 三道原题qwq真的凉 半年前看到有人发说说,梦见省选打开题目,是Please contact lydsy2012@163.com! 没想到一语成谶 大众分300 ...
- Tomcat 控制台出现乱码
本地在启动tomcat时,控制台启动显示乱码 这是因为windows默认编码集为GBK,用startup.bat启动tomcat时,它会读取catalina.bat的代码并打开一个新窗口运行,打开的c ...
- 在下载SOPC代码的过程中遇到的一些错误
(1)Error (209015): Can't configure device. Expected JTAG ID code 0x02D120DD for device 2, but found ...
- Java数据类型(Primivite 和引用数据类型!)
一.byte(8位) short(16位) int(32位) long(64位) float(32位) double(64位) boolean(Java虚拟机决定) true 或者false! ...
- js 字符串截取函数substr,substring,slice之间的差异
js 字符串的截取,主要有三个函数,一般使用三个函数:substr,substring,slice. 而这三个函数是不完全一样的,平时很难记住,在这里做下笔记,下次遇到的时候,直接从这里参考,调用合适 ...
- Redis阻塞诊断基础
slowlog Redis慢查询 slowlog 参数 slowlog-log-slower-than: 慢查询时间阈值,超过这个阈值的查询将会被记录,默认值10000,但是微妙,也即10毫秒. sl ...
- mysql 采样查询 / 间隔查询 / 跳跃查询的两种实现思路
先创建一张测试表 CREATE TABLE `test` ( `id` ) DEFAULT NULL, `) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET= ...
- Virtualbox下克隆CentOS 网络配置
Virtualbox下克隆虚拟机非常容易,也使得我们在平常搭建测试环境方便了许多.不过克隆以后的虚机并不能够直接联网,这是由于网卡的MAC地址引起的.在"控制->复制"弹出的 ...
- AlphaGo的前世今生(三)AlphaGo Zero: AI Revolution and Beyond
这是本专题的第三节,在这一节我们将以David Silver等人的Natrue论文Mastering the game of Go without human knowledge为基础讲讲AlphaG ...