02_Flume1.6.0安装及单节点Agent实践
Flume1.6.0的安装
1、上传Flume-1.6.0-tar.gz到待部署的所有机器
以我的为例: /usr/local/src/
2、解压得到flume文件夹
# tar -xzvf flume-1.6.0-tar.gz
3、修改文件夹名称,属主,及权限
# mv flume-1.6.0 flume
# chown -R root:root flume
# chmod 755 flume
4、安装完毕,解压后可以直接使用,通过flume/conf下的配置文件修改就可以各种调戏了~
实践1 - 单节点Agent

1、配置文件
# -flume-netcat-test
# agent name: a1
# source: netcat
# channel: memory
# sink: logger, local console # define source,channel,sink name
a1.sources = r1
a1.channels = c1
a1.sinks = k1 # define source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost # ip地址也OK
a1.sources.r1.port = # define sink
a1.sinks.k1.type = logger # flume sink将拉取到的信息,event形式打印到自己被启动时的终端 # define channel
a1.channels.c1.type = memory
# number of events in memory queue 内存队列中的最大event数值
a1.channels.c1.capacity =
# number of events for commit(每次向memory queuet放入event,取出event的最大值),所以肯定是比内存队列中的event小
a1.channels.c1.transactioncapacity = # bind source,sink to channel
a1.sources.r1.channels = c1 # 1个source可以有多个channel
a1.sinks.k1.channel = c1 # 1个sink只能从1个channel取数据
2、启动本节点上的flume agent
# bin/flume-ng agent --conf conf --conf-file ./conf/flume-netcat.properties --name a1 -Dflume.root.logger=INFO,console
解读:使用conf目录下的flume-netcat.properties文件,启动agent, agent的名称为a1;
flume向console打印INFO级别及以上的日志信息
3、观察Flume agent的启动
flume启动过程中会向当前console打印INFO及以上级别的日志,在日志的最后可以看到a1启动,并且netcat source启动了1个serversocket,监听本机的4444端口

4、测试该Agent
再开启1个到telnet到Agent所在机器的命令行窗口,连接建立后输入数据,查看flume是否向console打印出了输入数据
1) telnet输入
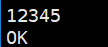
2) Flume输出event到console

3) telnet输入16个以上字符

4) Flume的logger sink, 输出event只有16个字符

telnet退出:ctrl+], 然后quit
通过flume的Git源码发现,默认情况下logger sink能够输出的最大字符数为16,该问题已经被提交修改,但flume-1.6.0版本并没有解决该问题
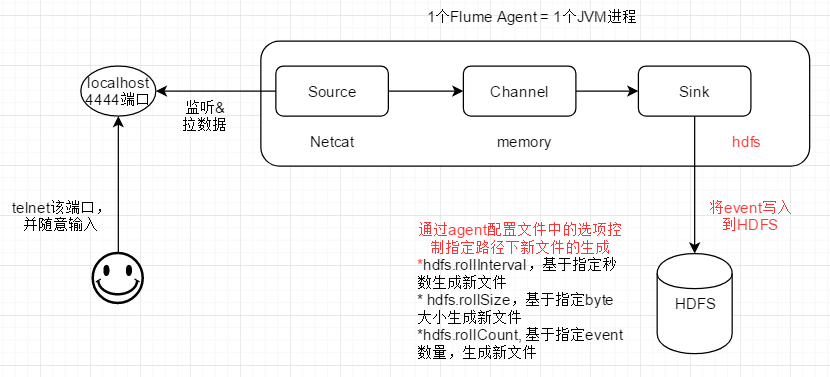
实践2 - 单节点Agent
exec source:执行配置文件中给定的命令,监听命令的输出,输出的每一行被作为一个event
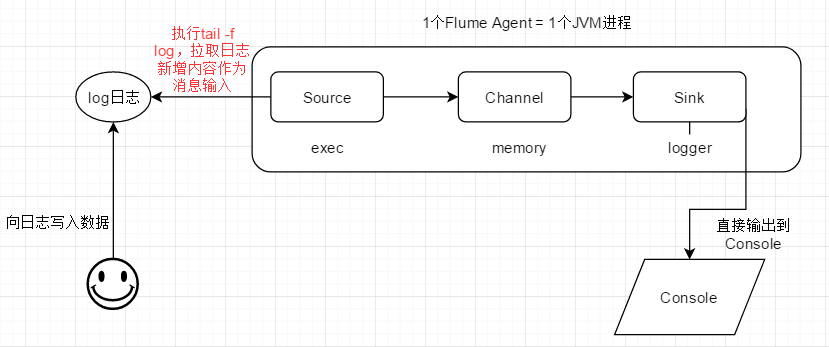
1、停止前一个flume agent进程
# ps -aux | grep flume 找到该进程的pid
# kill pid 不要kill -9 pid
2、配置文件
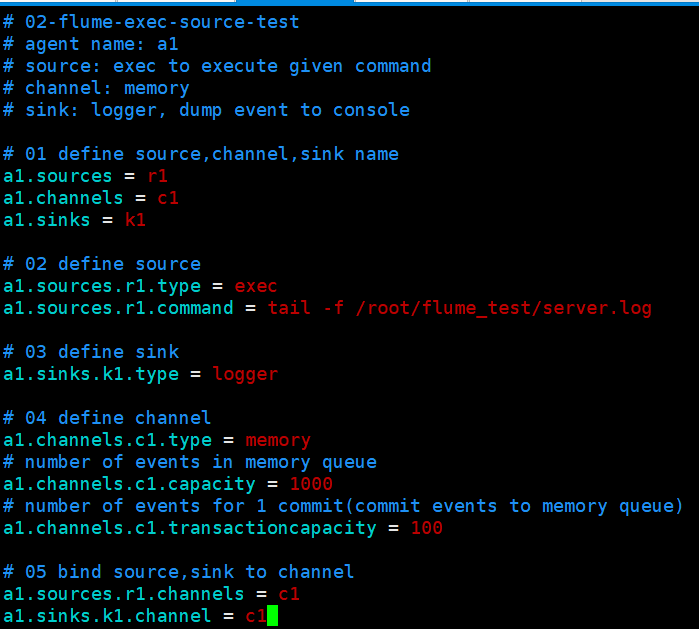
3、在agent运行的主机上创建测试用log文件,和配置文件中的路径及名称保持一致:/root/flume_test/server.log
4、启动本节点上的flume agent
# bin/flume-ng agent --conf conf --conf-file ./conf/flume-exec.properties --name a1 -Dflume.root.logger=INFO,console
解读:
使用conf目录下的flume-exec.properties文件,启动agent, agent的名称为a1;
flume向console打印INFO级别及以上的日志信息
5、根据flume agent启动时的日志,判断exec agent是否正常启动,执行给定命令,并监听输出(一行为一个event)

6、向flume agent机器上的测试log日志,写入内容,查看flume是否将新的输出转换为event,最终输出到终端
1)管道追加方式向server.log文件写入数据

2)flume输出event到自身被启动时的终端

3)再追加一次

4)查看flume是否输出event到自身被启动时的终端

5)查看server.log的文件结构,验证是否一行数据对应一个event
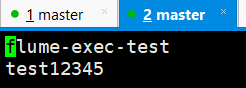
管道方式追加,在文件中生成了2行记录,分别对应一个flume event (命令执行结果的每一行输出,对应一个event)
实践3 - 单节点Agent
1、停止前一个flume agent进程
# ps -aux | grep flume 找到该进程的pid
# kill pid 不要kill -9 pid
2、配置文件


3、在HDFS上创建event落地的目录
# hadoop fs -mkdir /flume_hdfs_sink

4、启动本节点上的flume agent
# bin/flume-ng agent --conf conf --conf-file ./conf/flume-hdfs.properties --name a1 -Dflume.root.logger=INFO,console
解读:
使用conf目录下的flume-hdfs.properties文件,启动agent, agent的名称为a1;
flume向console打印INFO级别及以上的日志信息
5. 再开启1个到telnet到Agent所在机器的命令行窗口,连接建立后输入数据,查看flume是否在HDFS目录上生成文件,将event写入
1) telnet输入

2) Flume输出

HDFS上此时存在临时文件,数据还没有真正写入

3) telnet多次输入,第11次写入时,HDFS上落地生成新文件(rollCount=10此时满足)

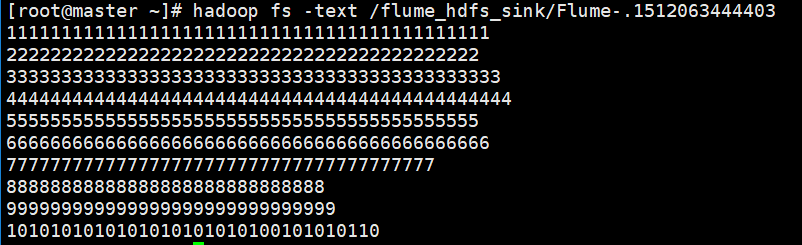
查看HDFS文件的内容
落地到HDFS文件中的内容,将只保留实际数据,不再是event形式
HDFS Sink的配置项参考(来自flume官网用户手册)


02_Flume1.6.0安装及单节点Agent实践的更多相关文章
- hbase伪分布式安装(单节点安装)
hbase伪分布式安装(单节点安装) http://hbase.apache.org/book.html#quickstart 1. 前提配置好java,环境java变量 上传jdk ...
- Elasticsearch.安装(单节点)
Elasticsearch.安装(单节点) 环境Linux 7.x jdk 1.8 elasticsearch 5.x 环境目录结构(根目录多了两个文件夹): /resources /** 存放 ...
- Ubuntu 12.04 Openstack Essex 安装(单节点)
这是陈沙克一篇非常好的博文,当时在进行openstack排错的时候,多亏了这篇文章里面有些内容 帮我找到了问题的所在: 原文:http://www.chenshake.com/ubuntu-12-04 ...
- 离线安装Cloudera Manager 5和CDH5(最新版5.9.3) 完全教程(四)数据库安装(单节点)
一.卸载CentOS自带的MySQL 1.1 查看之前是否安装过mysql [root@master mysql]# rpm -qa|grep -i mysql mysql-libs--.el6.x8 ...
- Dubbo入门到精通学习笔记(八):ActiveMQ的安装与使用(单节点)、Redis的安装与使用(单节点)、FastDFS分布式文件系统的安装与使用(单节点)
文章目录 ActiveMQ的安装与使用(单节点) 安装(单节点) 使用 目录结构 edu-common-parent edu-demo-mqproducer edu-demo-mqconsumer 测 ...
- .netcore consul实现服务注册与发现-单节点部署
原文:.netcore consul实现服务注册与发现-单节点部署 一.Consul的基础介绍 Consul是HashiCorp公司推出的开源工具,用于实现分布式系统的服务发现与配置.与其他分 ...
- 02_Kafka单节点实践
1.实践场景 开始前的准备条件: 1) 确认各个节点的jdk版本,将jdk升级到和kafka配套的版本(解压既完成安装,修改/etc/profile下的JAVA_HOME,source /etc/pr ...
- kafka系列一:单节点伪分布式集群搭建
Kafka集群搭建分为单节点的伪分布式集群和多节点的分布式集群两种,首先来看一下单节点伪分布式集群安装.单节点伪分布式集群是指集群由一台ZooKeeper服务器和一台Kafka broker服务器组成 ...
- Cloudera Manager安装之利用parcels方式安装单节点集群(包含最新稳定版本或指定版本的安装)(添加服务)(CentOS6.5)(四)
不多说,直接上干货! 福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 ...
随机推荐
- WordPress已占全球网站平台18.9%的份额
Automattic创始人马特·穆伦维格(Matt Mullenweg)在旧金山的WordCamp会议上谈到了旗下博客平台WordPress的最新发展情况.WordPress平台已成为全球18.9%网 ...
- 论存储IOPS和Throughput吞吐量之间的关系
论存储IOPS和Throughput吞吐量之间的关系 http://www.csdn.net/article/2015-01-14/2823552 IOPS和Throughput吞吐量两个参数是衡量存 ...
- [sh]sh最佳实战(含grep)
sh虐我千百遍,我待sh如初恋. sh复习资料 http://www.cnblogs.com/iiiiher/p/5385108.html http://blog.csdn.net/iiiiher/a ...
- 机器学习理论基础学习19---受限玻尔兹曼机(Restricted Boltzmann Machine)
一.背景介绍 玻尔兹曼机 = 马尔科夫随机场 + 隐结点 二.RBM的Representation BM存在问题:inference 精确:untractable: 近似:计算量太大 因此为了使计算简 ...
- [lr] 直方图
直方图基础知识 • 直方图的特征和作用 ▪ 直方图的x轴从左到右代表亮度逐渐增加,即从最暗到最亮:y轴代表某个亮度值下颜色像素的多少(密度). ▪ 直方图由红绿蓝三种颜色组成,分别表示红绿蓝通道:其中 ...
- pycharm Unresolved reference 无法引入包
1. 问题描述: 在项目中P存在文件夹A.B.C,A有文件夹a和b,在a中引入b的一个类, a.py: from b import func1 虽然运行成功,但是在Pycharm中显示: Unreso ...
- nginx安装,反向代理配置
1.centos 版本 下载最新稳定版 https://www.nginx.com/resources/wiki/start/topics/tutorials/install/# 2.执行语句: ./ ...
- LR和SVM的相同和不同
之前一篇博客中介绍了Logistics Regression的理论原理:http://www.cnblogs.com/bentuwuying/p/6616680.html. 在大大小小的面试过程中,经 ...
- Windows下使用MakeFile(Mingw)文件
下面是我基于<C++GUI QT4编程(第二版)> 2.3节快速设计对话框编写例子地址: https://files.cnblogs.com/files/senior-engineer/g ...
- python之路----进程三
IPC--PIPE管道 #创建管道的类: Pipe([duplex]):在进程之间创建一条管道,并返回元组(conn1,conn2),其中conn1,conn2表示管道两端的连接对象,强调一点:必须在 ...