1.keras实现-->自己训练卷积模型实现猫狗二分类(CNN)
原数据集:包含 25000张猫狗图像,两个类别各有12500
新数据集:猫、狗 (照片大小不一样)
- 训练集:各1000个样本
- 验证集:各500个样本
- 测试集:各500个样本
1= 狗,0= 猫
# 将图像复制到训练、验证和测试的目录 import os,shutil orginal_dataset_dir = 'kaggle_original_data/train' |

|
#将猫狗分类的小型卷积神经网络实例化 |
该问题为二分类问题,所以网咯最后一层是使用sigmoid激活的 单一单元,大小为1的Dense层。
|
from keras import optimizers model.compile(loss='binary_crossentropy', |
loss: binary_crossentropy 优化器: RMSprop 度量:acc精度 |
#使用ImageDataGenerator从目录中读取图像 |

用flow_from_directory最值得注意的是directory这个参数:
它的目录格式一定要注意是包含一个子目录下的所有图片这种格式, driectoty路径只要写到标签路径上面的那个路径即可。
|
for data_batch,labels_batch in train_generator: |
data batch shape: (20, 150, 150, 3) |
#利用批量生成器拟合模型 #保存模型 |
|
|
from keras.models import load_model |
手残,误操作,还好我已经保存了模型,用这句话就可以载入模型 |
#绘制损失曲线和精度曲线 |

过拟合太严重了,原因可能是训练样本较少 |
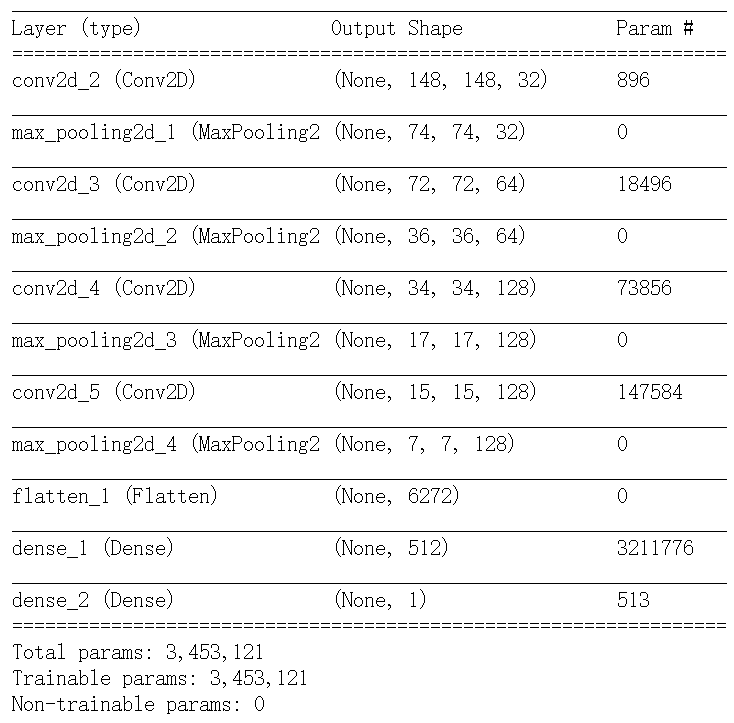

#因为数据样本较少,容易过拟合,因此我们使用数据增强来减少过拟合 #利用ImageDataGenerator来设置数据增强 |
数据增强是从现有的训练样本中生成更多的训练数据,其方法是 利用多种能够生成可信图像的随机变换来增加样本。其目标是, 模型在训练时不会两次查看完全相同的图像。这让模型能够观察 到数据的更多内容,从而具有更好的泛化能力。 |
#显示几个随机增强后的训练图像 |
 
|
#向模型中添加一个Dropout层,添加到密集连接分类器之前 |
|
#利用数据增强生成器训练卷积神经网络 |
|
#绘制损失曲线和精度曲线 |

使用了数据增强和dropout之后,模型不再过拟合,训练曲线紧紧跟着验证曲线 |
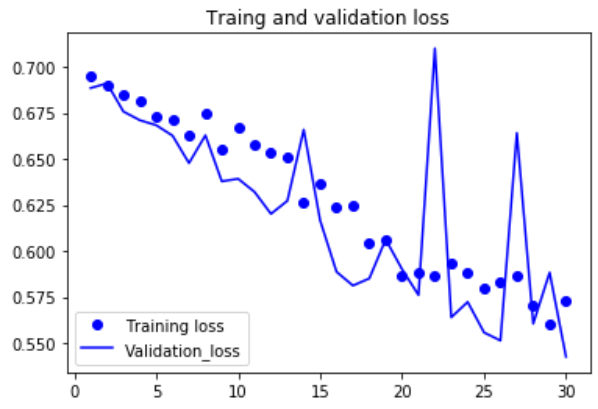
但只靠从头开始训练自己的卷积神经网络,再想提高精度就十分困难,因为可用的数据太少。想要在这个问题上进一步提高精度,下一步需要使用预训练的模型。
1.keras实现-->自己训练卷积模型实现猫狗二分类(CNN)的更多相关文章
- Kaggle系列1:手把手教你用tensorflow建立卷积神经网络实现猫狗图像分类
去年研一的时候想做kaggle上的一道题目:猫狗分类,但是苦于对卷积神经网络一直没有很好的认识,现在把这篇文章的内容补上去.(部分代码参考网上的,我改变了卷积神经网络的网络结构,其实主要部分我加了一层 ...
- 深度学习原理与框架-猫狗图像识别-卷积神经网络(代码) 1.cv2.resize(图片压缩) 2..get_shape()[1:4].num_elements(获得最后三维度之和) 3.saver.save(训练参数的保存) 4.tf.train.import_meta_graph(加载模型结构) 5.saver.restore(训练参数载入)
1.cv2.resize(image, (image_size, image_size), 0, 0, cv2.INTER_LINEAR) 参数说明:image表示输入图片,image_size表示变 ...
- keras系列︱Sequential与Model模型、keras基本结构功能(一)
引自:http://blog.csdn.net/sinat_26917383/article/details/72857454 中文文档:http://keras-cn.readthedocs.io/ ...
- 使用 keras 和 tfjs 构建血细胞分类模型
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识!
- Deep Learning模型之:CNN卷积神经网络(一)深度解析CNN
http://m.blog.csdn.net/blog/wu010555688/24487301 本文整理了网上几位大牛的博客,详细地讲解了CNN的基础结构与核心思想,欢迎交流. [1]Deep le ...
- Keras 如何利用训练好的神经网络进行预测
分成两种情况,一种是公开的训练好的模型,下载后可以使用的,一类是自己训练的模型,需要保存下来,以备今后使用. 如果是第一种情况,则参考 http://keras-cn.readthedocs.i ...
- 使用GPU训练TensorFlow模型
查看GPU-ID CMD输入: nvidia-smi 观察到存在序号为0的GPU ID 观察到存在序号为0.1.2.3的GPU ID 在终端运行代码时指定GPU 如果电脑有多个GPU,Tensorfl ...
- Keras框架下的保存模型和加载模型
在Keras框架下训练深度学习模型时,一般思路是在训练环境下训练出模型,然后拿训练好的模型(即保存模型相应信息的文件)到生产环境下去部署.在训练过程中我们可能会遇到以下情况: 需要运行很长时间的程序在 ...
- 【猫狗数据集】使用预训练的resnet18模型
数据集下载地址: 链接:https://pan.baidu.com/s/1l1AnBgkAAEhh0vI5_loWKw提取码:2xq4 创建数据集:https://www.cnblogs.com/xi ...
随机推荐
- find中的-print0和xargs中-0的奥妙
原文地址:find中的-print0和xargs中-0的奥妙作者:改变自己 默认情况下, find 每输出一个文件名, 后面都会接着输出一个换行符 ('n'), 因此我们看到的 find 的输出都是一 ...
- 重载i++,++i操作符
#include <iostream> using namespace std; class Time { public: Time(){min=;sec=;} Time(int m,in ...
- LeetCode 27 Remove Element (移除数组中指定元素)
题目链接: https://leetcode.com/problems/remove-element/?tab=Description Problem : 移除数组中给定target的元素,返回剩 ...
- linux netcat命令使用技巧
netcat是网络工具中的瑞士军刀,它能通过TCP和UDP在网络中读写数据.通过与其他工具结合和重定向,你可以在脚本中以多种方式使用它.使用netcat命令所能完成的事情令人惊讶. netcat所做的 ...
- Mac下一款门罗币挖矿木马的简要分析
背景 最近在应急中发现了一款Mac上的挖矿木马,目标是挖门罗币,经过走访,受害用户都有从苹果电脑上安装第三方dmg的经历(其中可以确定一款LOL Mac私服安装app会导致该木马),怀疑在网上很多第三 ...
- java代码中实现android背景选择的selector-StateListDrawable的应用
首先定义一个获得StateListDrawable对象的方法: private StateListDrawable addStateDrawable(Context context, int idNo ...
- 【Android】 导入项目报错的解决方案
1.打项目的properties -->android 为其指一个运版本, 2.修改default properties 文件 ,改相应版本等级 3.选中项目,单击右键,选中properties ...
- 关于IP地址子网的划分
- Shell转义字符与变量替换
转义字符 含义 \\ 反斜杠 \a 警报,响铃 \b 退格(删除键) \f 换页(FF),将当前位置移到下页开头 \n 换行 \r 回车 \t 水平制表符(tab键) \v 垂直制表符 vim te ...
- POJ-1456 Supermarket(贪心,并查集优化)
Supermarket Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 10725 Accepted: 4688 Descript ...