MapReduce框架Hadoop应用(一)
Google对其的定义:MapReduce是一种变成模型,用于大规模数据集(以T为级别的数据)的并行运算。用户定义一个map函数来处理一批Key-Value对以生成另一批中间的Key-Value对,再定义一个reduce函数将所有这些中间的有相同Key的value合并起来。“Map”(映射)和“Reduce”(简化)的概念和它们的主要思想都是从函数式编程语言借用而来的,还有从矢量编程语言借来的特性。在实现过程中,需指定一个map函数,用来把一组键值对映射成一组新的键值对,再指定并发的reduce函数,用来保证所有映射的每一个键值对共享相同的键组。在函数式编程中认为,应当保持数据不可变性,避免再多个进程或线程间共享数据,这就意味着,map函数虽然很简单,却可以通过两个或多个线程再同一个列表上同时执行,由于列表本身并没有改变,线程之间互不影响。
MapReduce模型:
Hadoop MapReduce模型主要有Mapper和Reducer两个抽象类。Mapper主要负责对数据的分析处理,最终转化为Key-Value的数据结构;Reducer主要负责获取Mapper出来的结果,对结果进行进一步统计。Hadoop MapReduce 实现存储的均衡,但为实现计算的均衡,这是其天生的缺陷,因此,通常采用规避的办法来解决此问题,由程序员来保证。


MapReduce框架构成:

(注:TaskTracker都运行在HDFS的DataNode上)
1、JobClient
用户编写的MapReduce程序通过JobClient提交到JobTracker端 ;同时,用户可通过Client提供的一些接口查看作业运行状态。在Hadoop内部用“作业” (Job)表示MapReduce程序。一个 MapReduce程序可对应若干个作业,而每个作业会被分解成若干个Map/Reduce任务(Task)。每一个Job都会在用户端通过JobClient类将应用程序以及配置参数Configuration打包成JAR文件存储在HDFS里,并把路径提交到JobTracker的master服务,然后由master创建每一个Task(即MapTask和ReduceTask)并将它们分发到各个TaskTracker服务中去执行。
2、Mapper和Reducer
运行在Hadoop上的MapReduce程序最基本的组成部分包括:一个Mapper和一个Reducer以及创建的JobConf执行程序,其实还可以包括Combiner,Combiner实际上也是Reducer的实现。
3、JobTracker
JobTracker是一个master服务, 主要负责接受Job,并负责资源监控和作业调度。JobTracker 监控所有 TaskTracker 与作业Job的健康状况,一旦发现失败情况后,其会将相应的任务转移到其他节点;同时,JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空闲时,选择合适的任务使用这些资源。一般情况应该把JobTracker部署在单独的机器上。
4、TaskTracker
TaskTracker是运行在多个节点上的slaver服务,会周期性地通过Heartbeat将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker发送过来的命令并执行相应的操作(如启动新任务、杀死 任务等),即接受作业并负责直接执行每一个任务。
5、JobInprogress
JobClient提交Job后,JobTracker会创建一个JobInProgress来跟踪和调度这个Job,并把它添加到Job队列里。JobInProgress会根据提交的任务JAR中定义的数据集来创建对应的一批TaskInProgress用于监控和调度MapTask,同事创建指定数目的TaskInProgress用于监控和调度ReduceTask。
6、TaskInProgress
JobTracker启动任务时通过每一个TaskInProgress来运行Task,这时会把Task对象(即MapTask和ReduceTask)序列化写入相应的TaskTracker服务中,TaskTracker收到后会创建对应的TaskInProgress用于监控和调度该Task。启动具体的Task进程需要通过TaskInProgress管理,通过TaskRunner对象来运行。TaskRunner会自动装载任务JAR文件并设置好环境变量后,启动一个独立的子进程来执行Task,即MapTask或ReduceTask,但它们不一定在同一个TaskTracker上运行。
7、MapTask和ReduceTask
一个完整的Job会自动一次执行Mapper、Combiner(在JonConf指定Combiner时执行)和Reducer。其中,Mapper和Combiner是由MapTask调用执行的,Reducer是由ReduceTask调用执行,Combiner实际上也是Reducer接口类实现的。Mapper会根据Job JAR中定义的输入数据集按<k1,v1>对读入,处理完成生成临时的<k2,v2>对,如果定义了Combiner,MapTask会在Mapper完成调用,该Combiner将相同Key的值做一定的合并处理,以减少输出结果集。MapTask的任务完成即交给ReduceTask进程调用Reducer处理,生成最终结果<k3,v3>对。下面来看无Combiner的简单处理:
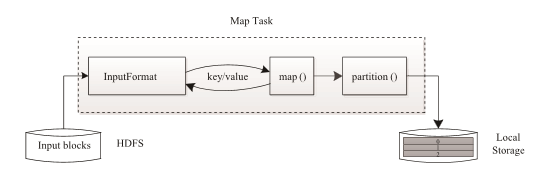
Map Task 执行过程如下图所示。由该图可知,Map Task 先将对应的split (MapReduce处理单元)迭代解析成一 个个 key/value 对,依次调用用户自定义的map() 函数进行处理,最终将临时结果存放到本地磁盘上,其中临时数据被分成若干个partition(分片),每个partition 将被一个Reduce Task处理。
Reduce Task 执行过程如下图所示。该过程分为三个阶段:
①从远程节点上读取Map Task 中间结果(称为“Shuffle阶段”);
②按照key对key/value 对进行排序(称为“Sort阶段”);
③依次读取 <key, value list>,调用用户自定义的 reduce() 函数处理,并将最终结果存到HDFS上(称为“Reduce 阶段”)。

(注:本文参考:Hadoop应用开发技术详解)
MapReduce框架Hadoop应用(一)的更多相关文章
- Hadoop 之 MapReduce 框架演变详解
经典版的MapReduce 所谓的经典版本的MapReduce框架,也是Hadoop第一版成熟的商用框架,简单易用是它的特点,来看一幅图架构图: 上面的这幅图我们暂且可以称谓Hadoop的V1.0版本 ...
- hadoop 学习笔记:mapreduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop学习笔记:MapReduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- 更快、更强——解析Hadoop新一代MapReduce框架Yarn(CSDN)
摘要:本文介绍了Hadoop 自0.23.0版本后新的MapReduce框架(Yarn)原理.优势.运作机制和配置方法等:着重介绍新的Yarn框架相对于原框架的差异及改进. 编者按:对于业界的大数据存 ...
- Hadoop 新 MapReduce 框架 Yarn 详解
Hadoop 新 MapReduce 框架 Yarn 详解: http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/ Ap ...
- 【Big Data - Hadoop - MapReduce】hadoop 学习笔记:MapReduce框架详解
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop 新 MapReduce 框架 Yarn 详解【转】
[转自:http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/] 简介: 本文介绍了 Hadoop 自 0.23.0 版本 ...
- Hadoop mapreduce框架简介
传统hadoop MapReduce架构(老架构) 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 1.首先用户程序 (JobClient) 提交了一个 job,job ...
- 下一代Apache Hadoop MapReduce框架的架构
背景 随着集群规模和负载增加,MapReduce JobTracker在内存消耗,线程模型和扩展性/可靠性/性能方面暴露出了缺点,为此需要对它进行大整修. 需求 当我们对Hadoop MapReduc ...
随机推荐
- Linux: 安装NVIDIA显卡驱动
Linux(Fedora25, 64bit)台式机配备了NVIDIA显卡GTX950,但是仅仅使用开源驱动nouveau,无法发挥NVIDIA显卡的性能,所以可以考虑使用官方提供的显卡驱动. # 先安 ...
- shell中source与sh区别
shell中使用source conf.sh,是直接运行conf.sh的命令,不创建子shell,类似与html中include,而sh是则创建子shell, 子shell里面 的变量父shell无法 ...
- 大话Session
[原创]转载请保留出处:shoru.cnblogs.com 晋哥哥的私房钱 引言 在web开发中,session是个非常重要的概念.在许多动态网站的开发者看来,session就是一个变量,而且其表现像 ...
- MySQL(一)--基本语法与常用语句
将大量数据保存起来,通过计算机加工而成的可以进行高效访问的数据集合称为数据库(Database,DB). 将姓名.住址.电话号码.邮箱地址.爱好和家庭构成等数据保存到数据库中,就可以随时迅速获取想要的 ...
- python3的正则表达式(regex)
正则表达式提供了一种紧凑的表示法,可用于表示字符串的组合,一个单独的正则表达式可以表示无限数量的字符串.常用的5种用途:分析.搜索.搜索与替代.字符串的分割.验证. (一)正则表达式语言python中 ...
- 实现一个简单的Log框架
实际上算不上框架,只是自己对日志框架的一点理解. 核心接口:Logger,供调用者完成不同等级的日志输出 package com.lichmama.log.service; public interf ...
- 004.Create a web app with ASP.NET Core MVC using Visual Studio on Windows --【在 windows上用VS创建mvc web app】
Create a web app with ASP.NET Core MVC using Visual Studio on Windows 在 windows上用VS创建mvc web app 201 ...
- 基本的传染病模型:SI、SIS、SIR及其Python代码实现
本文主要参考博客:http://chengjunwang.com/en/2013/08/learn-basic-epidemic-models-with-python/.该博客有一些笔误,并且有些地方 ...
- css 定位属性position的使用方法实例-----一个层叠窗口
运行结果: <!DOCTYPE html> <html> <head> <title>重叠样式窗口</title> <style ty ...
- canvas一周一练 -- canvas基础学习
从上个星期开始,耳朵就一直在生病,里面长了个疙瘩,肿的一碰就疼,不能吃饭不能嗨 (┳_┳)……在此提醒各位小伙伴,最近天气炎热,一定要注意防暑上火,病来如山倒呀~ 接下来我正在喝着5块一颗的药学习ca ...