kafka 知识点整理
一个partition只能被同一个消费组内一个消费者消费,所以在同一时间点上,订阅到同一个partition的consumer必然属于不同的Consumer Group.
因此,如果设置的partition的数量小于consumer的数量,就会有消费者消费不到数据。所以,推荐partition的数量一定要大于同时运行的consumer的数量
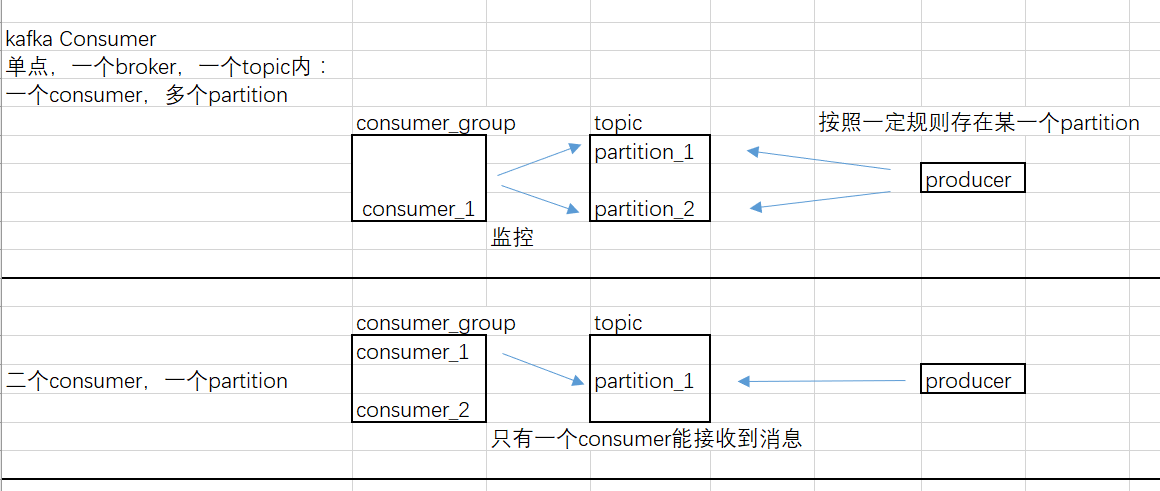
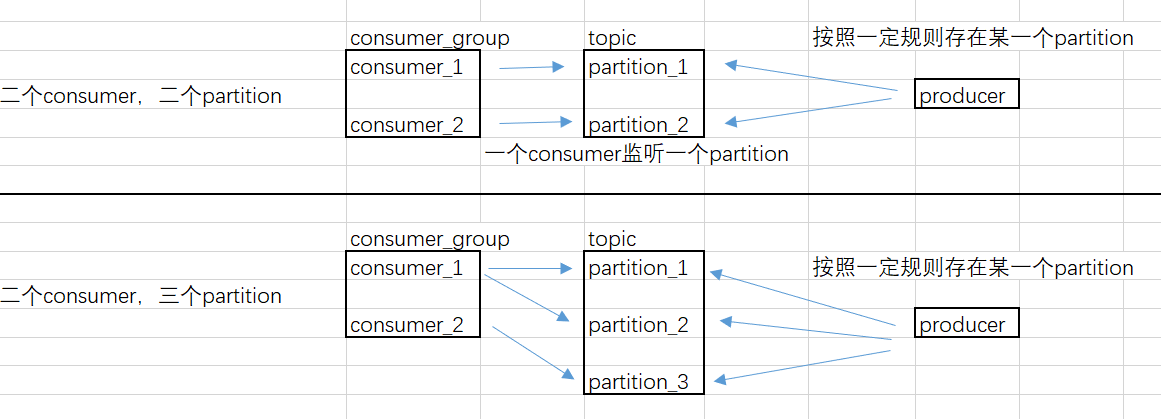
Consumer Group与Consumer的关系是动态维护的:
当一个Consumer 进程挂掉 或者是卡住时,该consumer所订阅的partition会被重新分配到该group内的其它的consumer上。当一个consumer加入到一个consumer group中时,同样会从其它的consumer中分配出一个或者多个partition 到这个新加入的consumer。当启动一个Consumer时,会指定它要加入的group,使用的是配置项:group.id。
为了维持Consumer 与 Consumer Group的关系,需要Consumer周期性的发送heartbeat到coordinator(协调者,在早期版本,以zookeeper作为协调者。后期版本则以某个broker作为协调者)。当Consumer由于某种原因不能发Heartbeat到coordinator时,并且时间超过session.timeout.ms时,就会认为该consumer已退出,它所订阅的partition会分配到同一group 内的其它的consumer上。而这个过程,被称为rebalance。
poll 方法
Consumer读取partition中的数据是通过调用发起一个fetch请求来执行的。而从KafkaConsumer来看,它有一个poll方法。但是这个poll方法只是可能会发起fetch请求。原因是:Consumer每次发起fetch请求时,读取到的数据是有限制的,通过配置项max.partition.fetch.bytes来限制的。而在执行poll方法时,会根据配置项个max.poll.records来限制一次最多pool多少个record.
那么就可能出现这样的情况: 在满足max.partition.fetch.bytes限制的情况下,假如fetch到了100个record,放到本地缓存后,由于max.poll.records限制每次只能poll出15个record。那么KafkaConsumer就需要执行7次才能将这一次通过网络发起的fetch请求所fetch到的这100个record消费完毕。其中前6次是每次pool中15个record,最后一次是poll出10个record。
在consumer中,还有另外一个配置项:max.poll.interval.ms ,它表示最大的poll数据间隔,如果超过这个间隔没有发起pool请求,但heartbeat仍旧在发,就认为该consumer处于 livelock状态。就会将该consumer退出consumer group。所以为了不使Consumer 自己被退出,Consumer 应该不停的发起poll(timeout)操作。而这个动作 KafkaConsumer Client是不会帮我们做的,这就需要自己在程序中不停的调用poll方法了。
offset存储
在kafka 0.9版本之后,kafka为了降低zookeeper的io读写,减少network data transfer,也自己实现了在kafka server上存储consumer,topic,partitions,offset信息将消费的 offset 迁入到了 Kafka 一个名为 __consumer_offsets 的Topic中。
kafka高可用
为了保证kafka的高可用(当leader节点挂了之后,kafka依然能提供服务)kafka提供了备份的功能。这个备份是针对partition的。
每个partition会选举一个Leader,其它Replicas作为Follower,只有Leader负责数据读写,Follower只向Leader顺序Fetch数据(N条通路)
通过kafka manager可以很直观看到,如下:
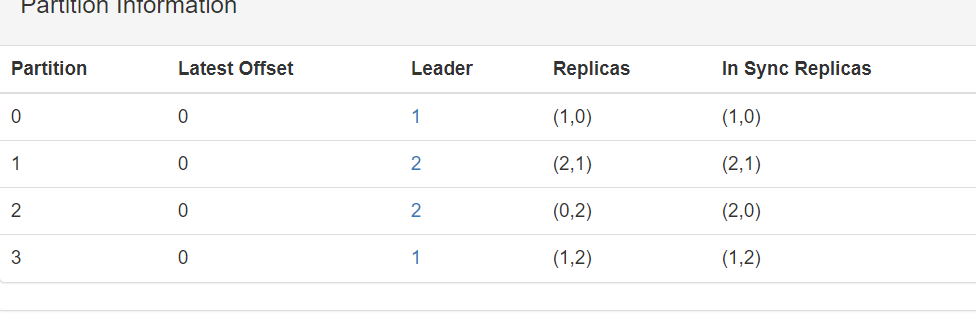
Partition 1,Leader是broker 1,其它Replicas是Follower。
kafka 知识点整理的更多相关文章
- kafka知识点整理总结
kafka知识点整理总结 只不过是敷衍 2017-11-22 21:39:59 kafka知识点整理总结,以备不时之需. 为什么要使用消息系统: 解耦 并行 异步通信:想向队列中放入多少消息就放多少, ...
- 大数据 -- kafka学习笔记:知识点整理(部分转载)
一 为什么需要消息系统 1.解耦 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险.许多 ...
- kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- [Big Data - Kafka] kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- ACM个人零散知识点整理
ACM个人零散知识点整理 杂项: 1.输入输出外挂 //读入优化 int 整数 inline int read(){ int x=0,f=1; char ch=getchar(); while(ch& ...
- Android 零散知识点整理
Android 零散知识点整理 为什么Android的更新试图操作必须在主线程中进行? 这是因为Android系统中的视图组件并不是线程安全的.通常应该让主线程负责创建.显示和更新UI,启动子线程,停 ...
- vue前端面试题知识点整理
vue前端面试题知识点整理 1. 说一下Vue的双向绑定数据的原理 vue 实现数据双向绑定主要是:采用数据劫持结合发布者-订阅者模式的方式,通过 Object.defineProperty() 来劫 ...
- kafka知识点
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- JSP页面开发知识点整理
刚学JSP页面开发,把知识点整理一下. ----------------------------------------------------------------------- JSP语法htt ...
随机推荐
- js获取select下拉框中的值
现在有一id为userType的下拉框,怎么获取选中的值: 用户类型: <select name="type" id="userType"> < ...
- 1705. [Usaco2007 Nov]Telephone Wire 架设电话线
传送门 显然 $dp$,首先设 $f[i][j]$ 表示当前考虑到第 $i$ 个电线杆,高度为 $j$ 时的最小代价 那么有转移 $f[i][j]=f[i-1][k]+cost+C(j-k)$,其中 ...
- 攻防世界--simple-check-100
测试文件:https://adworld.xctf.org.cn/media/task/attachments/2543a3658d254c30a89e4ea7b8950c27.zip 这道题很坑了, ...
- NancyFx 2.0的开源框架的使用-ConstraintRouting
新建一个空的Web项目 然后在Nuget库中安装下面两个包 Nancy Nancy.Hosting.Aspnet 然后在根目录添加三个文件夹,分别是models,Module,Views 然后往Mod ...
- APP性能
一.APP性能维度分析 APP类型众多,根据具体类型划分,性能指标的维度和优先级各不相同.视频类APP归属于娱乐游戏型的APP,因此性能测试维度优先级排序为:流畅度.crash.内存.流量.响应时长 ...
- linux使用v 2ray
一.安装配置服务端程序 是时候使用 了,因为相对安全,使用方法很简单,使用root权限执行以下命令即可 $ sudo -i 一顿安装后如图 输入 命令可以查看链接,然后在客户端使用这个链接就能配置好了 ...
- Codeforces Round #425 (Div. 2) - A
题目链接:http://codeforces.com/contest/832/problem/A 题意:有n个棍子,两个人轮流取这些棍子,每个人每次只能去恰好k个棍子(不足k个则不能取),问先手取的棍 ...
- OGG-00303
解决方案:因为Defgen版本不同,注释数据定义文件对应的行 *Database type:ORACLE,用*在行首注释即可
- CreateProcessAsUser 服务调用
CreateProcessAsUser 函数 如果想通过服务向桌面用户Session 创建一个复杂UI 程序界面,则需要使用CreateProcessAsUser 函数为用户创建一个新进程用来运行相应 ...
- Rust(一)介绍 安装
目录 Rust安装 Rust介绍: Windows 安装步骤: Helle world 创建项目文件夹: 写并执行程序: Rust安装 安装过程简单快捷,直接参照官网即可,Rust安装 Rust介绍: ...