特征提取算法(1)——纹理特征提取算法LBP
模式识别中进行匹配识别或者分类器分类识别时,判断的依据就是图像特征。用提取的特征表示整幅图像内容,根据特征匹配或者分类图像目标。
常见的特征提取算法主要分为以下3类:
- 基于颜色特征:如颜色直方图、颜色集、颜色矩、颜色聚合向量等;
- 基于纹理特征:如Tamura纹理特征、自回归纹理模型、Gabor变换、小波变换、MPEG7边缘直方图等;
- 基于形状特征:如傅立叶形状描述符、不变矩、小波轮廓描述符等;
LBP特征提取算法
LBP(Local Binary Patterns,局部二值模式)是提取局部特征作为判别依据的,一种有效的纹理描述算子,度量和提取图像局部的纹理信息,它具有旋转不变性和灰度不变性等显著的优点,对光照具有不变性。用于纹理特征提取。而且,提取的特征是图像的局部的纹理特征。有多种改进型,LBP结合BP神经网络已经用于人脸识别等领域。
灰度不变性:指的是光照变化是否会对描述产生影响。以上面的8邻域来说,光照变化很难改变中心像素点的灰度值与周围8个像素的大小关系。因为光照是一种区域性质的变化,而不是单像素性质的变化。
1、LBP特征描述
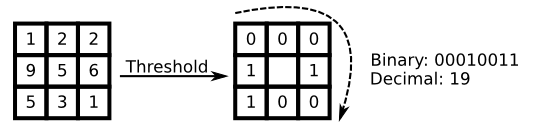
LBP的基本思想是定义于像素的8邻域中(3x3的窗口), 以中心像素的灰度值为阈值, 将周围8 个像素的值与其比较, 如果周围的像素值小于中心像素的灰度值, 该像素位置就被标记为0, 否则标记为1。这样3x3的邻域内的八个点经过比较能够产生8位二进制数(通常转换为十进制,即LBP码,共256种),每个像素得到一个二进制组合, 即得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理信息。
2、LBP的改进版本:
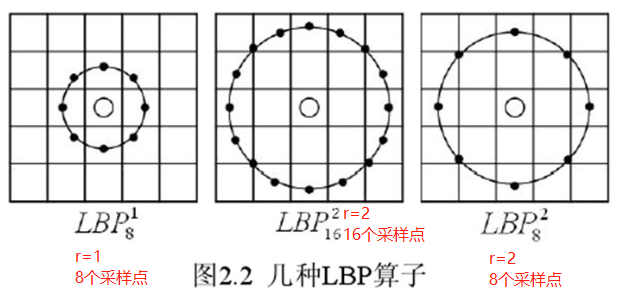
(1)圆形LBP算子
基本的 LBP算子的最大缺陷在于它只覆盖了一个固定半径范围内的小区域,这显然不能满足不同尺寸和频率纹理的需要。为了适应不同尺寸的纹理特征,达到灰度和旋转不变性的要求。将 3×3邻域扩展到任意邻域,并用圆形邻域代替了正方形邻域,改进后的 LBP 算子允许在半径为 R的圆形邻域内有任意多个像素点。从而得到了诸如半径为R的圆形区域内含有P个采样点的LBP算子。
(2)LBP旋转不变模式
从 LBP 的定义可以看出,LBP 算子是灰度不变的,但却不是旋转不变的。图像的旋转就会得到不同的LBP值。
Maenpaa等人又将 LBP算子进行了扩展,提出了具有旋转不变性的 LBP 算子,即不断旋转圆形邻域得到一系列初始定义的 LBP值,取其最小值作为该邻域的 LBP 值。
下图给出了求取旋转不变的 LBP 的过程示意图,图中算子下方的数字表示该算子对应的 LBP值,图中所示的 8 种 LBP模式,经过旋转不变的处理,最终得到的具有旋转不变性的 LBP值为 15。也就是说,图中的 8种 LBP 模式对应的旋转不变的 LBP模式都是 00001111。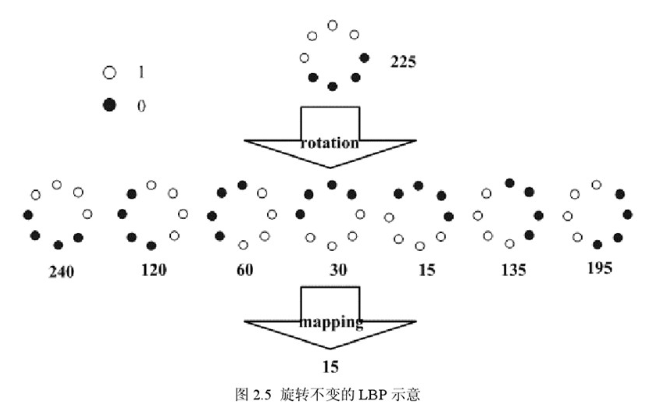
(3)LBP等价模式
一个LBP算子可以产生不同的二进制模式,对于半径为R的圆形区域内含有P个采样点的LBP算子将会产生2p种模式。很显然,随着邻域集内采样点数的增加,二进制模式的种类是急剧增加的。例如:5×5邻域内20个采样点,有220=1,048,576种二进制模式。
如此多的二值模式无论对于纹理的提取还是对于纹理的识别、分类及信息的存取都是不利的。同时,过多的模式种类对于纹理的表达是不利的。例如,将LBP算子用于纹理分类或人脸识别时,常采用LBP模式的统计直方图来表达图像的信息,而较多的模式种类将使得数据量过大,且直方图过于稀疏。因此,需要对原始的LBP模式进行降维,使得数据量减少的情况下能最好的代表图像的信息。
为了解决二进制模式过多的问题,提高统计性,Ojala提出了采用一种“等价模式”(Uniform Pattern)来对LBP算子的模式种类进行降维。Ojala等认为,在实际图像中,绝大多数LBP模式最多只包含两次从1到0或从0到1的跳变。因此,Ojala将“等价模式”定义为:当某个LBP所对应的循环二进制数从0到1或从1到0最多有两次跳变时,该LBP所对应的二进制就称为一个等价模式类,除了等价模式以外的模式都归一一类,称为混合模式类。计算跳变的方法:如10010111,首先第一二位10,由1—>0跳变一次;第二、三位00,没有跳变;第三、四位01,由0—>1跳变一次,第四、五位10,由1—>0跳变一次;第五六位01,由0—>1跳变一次;第六七位11,没有跳变;第七八位11,没有跳变;第八位和第一位11,没有跳变;故总共跳变4次。
通过这种改进,二进制模式的种类大大减少,而不会丢失任何信息,模式种类由原来的2^p减少为p*(p-1)+2种。对于3×3邻域内8个采样点来说,二进制模式由原始的256种减少为58种,这使得特征向量的维数更少,并且可以减少高频噪声带来的影响。
1、0次跳变,只有两种,即000..或者1111....
2、1次跳变,两种可能,0—>1或者1—>0:
(1)0开头:0...01、0....011,一共有p-1种;
(2)1开头:1...10、1...100、1..1000、等等,一种有p-1种;
综合,一次跳变有2(p-1)种。
2、两次跳变,0—>1—>0和1—>0—>1
0—>1—>0:第一次跳变位置在第2、第3、........p-1位置时,对应的第二次跳变有p-2种、p-3种....1种的跳变位置,所以共有(p-1)(p-2)/2种模式;
1—>0—>1:相应的也有(p-1)(p-2)/2种;
综合有(p-1)(p-2)种模式
综上一共有2+2(p-1)+(p-1)(p-2)=p(p-1)+2种模式可能。
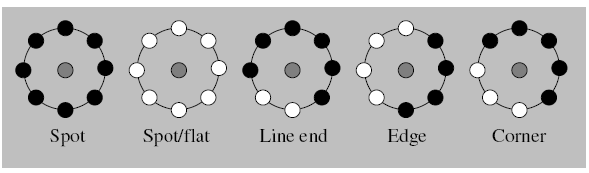
等价模式代表了图像的边缘、斑点、角点等关键模式,等价模式占了总模式中的绝大多数,所以极大的降低了特征维度。利用这些等价模式和混合模式类直方图,能够更好地提取图像的本质特征。
3、LBP特征用于检测的原理
显而易见的是,上述提取的LBP算子在每个像素点都可以得到一个LBP“编码”,那么,对一幅图像(记录的是每个像素点的灰度值)提取其原始的LBP算子之后,得到的原始LBP特征依然是“一幅图片”(记录的是每个像素点的LBP值)。

LBP的应用中,如纹理分类、人脸分析等,LBP特征提取结果还是大小相同的一幅图像,一般都不将LBP图谱作为特征向量用于分类识别,而是采用LBP特征谱的统计直方图作为特征向量用于分类识别。
因为,从上面的分析我们可以看出,这个“特征”跟位置信息是紧密相关的。直接对两幅图片提取这种“特征”,并进行判别分析的话,会因为“位置没有对准”而产生很大的误差。后来,研究人员发现,可以将一幅图片划分为若干的子区域,对每个子区域内的每个像素点都提取LBP特征,然后,在每个子区域内建立LBP特征的统计直方图。如此一来,每个子区域,就可以用一个统计直方图来进行描述;整个图片就由若干个统计直方图组成;
例如:一幅100*100像素大小的图片,划分为10*10=100个子区域(可以通过多种方式来划分区域),每个子区域的大小为10*10像素;在每个子区域内的每个像素点,提取其LBP特征,然后,建立统计直方图;这样,这幅图片就有10*10个子区域,也就有了10*10个统计直方图,利用这10*10个统计直方图,就可以描述这幅图片了。之后,我们利用各种相似性度量函数,就可以判断两幅图像之间的相似性了。
3、对LBP特征向量进行提取的步骤
(1)首先将检测窗口划分为16×16的小区域(cell);
(2)对于每个cell中的一个像素,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数,即得到该窗口中心像素点的LBP值;
(3)然后计算每个cell的直方图,即每个数字(假定是十进制数LBP值)出现的频率;然后对该直方图进行归一化处理。
(4)最后将得到的每个cell的统计直方图进行连接成为一个特征向量,也就是整幅图的LBP纹理特征向量;
然后便可利用SVM或者其他机器学习算法进行分类了。
特征提取算法(1)——纹理特征提取算法LBP的更多相关文章
- 个性化排序算法实践(五)——DCN算法
wide&deep在个性化排序算法中是影响力比较大的工作了.wide部分是手动特征交叉(负责memorization),deep部分利用mlp来实现高阶特征交叉(负责generalizatio ...
- 算法:Astar寻路算法改进,双向A*寻路算法
早前写了一篇关于A*算法的文章:<算法:Astar寻路算法改进> 最近在写个js的UI框架,顺便实现了一个js版本的A*算法,与之前不同的是,该A*算法是个双向A*. 双向A*有什么好处呢 ...
- Atitit.软件中见算法 程序设计五大种类算法
Atitit.软件中见算法 程序设计五大种类算法 1. 算法的定义1 2. 算法的复杂度1 2.1. Algo cate2 3. 分治法2 4. 动态规划法2 5. 贪心算法3 6. 回溯法3 7. ...
- JVM内存管理------GC算法精解(复制算法与标记/整理算法)
本次LZ和各位分享GC最后两种算法,复制算法以及标记/整理算法.上一章在讲解标记/清除算法时已经提到过,这两种算法都是在此基础上演化而来的,究竟这两种算法优化了之前标记/清除算法的哪些问题呢? 复制算 ...
- 缓存算法(页面置换算法)-FIFO、LFU、LRU
在前一篇文章中通过leetcode的一道题目了解了LRU算法的具体设计思路,下面继续来探讨一下另外两种常见的Cache算法:FIFO.LFU 1.FIFO算法 FIFO(First in First ...
- opencv3中的机器学习算法之:EM算法
不同于其它的机器学习模型,EM算法是一种非监督的学习算法,它的输入数据事先不需要进行标注.相反,该算法从给定的样本集中,能计算出高斯混和参数的最大似然估计.也能得到每个样本对应的标注值,类似于kmea ...
- Floyd-Warshall算法,简称Floyd算法
Floyd-Warshall算法,简称Floyd算法,用于求解任意两点间的最短距离,时间复杂度为O(n^3). 使用条件&范围通常可以在任何图中使用,包括有向图.带负权边的图. Floyd-W ...
- 8皇后以及N皇后算法探究,回溯算法的JAVA实现,非递归,循环控制及其优化
上两篇博客 8皇后以及N皇后算法探究,回溯算法的JAVA实现,递归方案 8皇后以及N皇后算法探究,回溯算法的JAVA实现,非递归,数据结构“栈”实现 研究了递归方法实现回溯,解决N皇后问题,下面我们来 ...
- 最短路径算法之二——Dijkstra算法
Dijkstra算法 Dijkstra算法主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止. 注意该算法要求图中不存在负权边. 首先我们来定义一个二维数组Edge[MAXN][MAXN]来存储 ...
随机推荐
- expect替人进行交互
expect是一门独立于shell的语言 用expect 执行写好的脚本 #!/usr/bin/expectspawn ssh root@192.168.40.67 (spawn 是expect ...
- Go语言入门篇-基本类型排序和 slice 排序
参见博客:https://blog.csdn.net/u010983881/article/details/52460998 package main import ( "sort" ...
- uwsgi + nginx 部署python项目(一)
uWSGI uWSGI是一个Web服务器,它实现了WSGI协议.uwsgi.http等协议.Nginx中HttpUwsgiModule的作用是与uWSGI服务器进行交换. 要注意 WSGI / uws ...
- [Bzoj1597][Usaco2008 Mar]土地购买(斜率优化)
题目链接 因为题目说可以分组,并且是求最值,所以斜率优化应该是可以搞的,现在要想怎么排序使得相邻的数在一个组中最优. 我们按照宽$w$从小到大,高$h$从小到大排序.这时发现可以筛掉一些一定没有贡献的 ...
- Redux 关系图解
Redux是一款状态管理库,并且提供了react-redux库来与React亲密配合, 但是总是傻傻分不清楚这2者提供的API和相应的关系.这篇文章就来理一理. Redux Redux 三大核心 Re ...
- 又一Tab切换效果(js实现)
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- mysqldump: [Warning] Using a password on the command line interface can be insecure.
MySQL 5.6 警告信息 command line interface can be insecure 修复 在命令行输入密码,就会提示这些安全警告信息. Warning: Using a pas ...
- luogu P1232 [NOI2013]树的计数
传送门 这题妙蛙 首先考虑构造出一个合法的树.先重新编号,把bfs序整成\(1,2,3...n\),然后bfs序就是按照从上到下从左往右的遍历顺序,所以可以考虑对bfs序分层,可以知道分层方式只会对应 ...
- JSP中九大内置对象及其作用
jsp中有九大内置对象分别为:request,response,session,application,out,pageContext,page,config,exception. request:请 ...
- ubuntu14.04首次安装.md
ubuntu14.04 安装后的工作 1.换软件源 sudo cp /etc/apt/sources.list /etc/apt/sources.list_backup 网易163更新服务器(广东广州 ...