轻松上手nodeJs爬取想要页面的数据
开始之前请先确保自己安装了Node.js环境!!!!!!!!
1.在项目文件夹安装两个必须的依赖包
npm install superagent -S
SuperAgent(官网是这样解释的)
-----SuperAgent is light-weight progressive ajax API crafted for flexibility, readability, and a low learning curve after being frustrated with many of the existing request APIs. It also works with Node.js!
-----superagent 是一个轻量的,渐进式的ajax api,可读性好,学习曲线低,内部依赖nodejs原生的请求api,适用于nodejs环境下
npm install cheerio -S
2.Cheerio
-----cheerio是nodejs的抓取页面模块,为服务器特别定制的,快速、灵活、实施的jQuery核心实现。适合各种Web爬虫程序。相当于node.js中的jQuery
3.新建 crawler.js 文件
在里面输入
1 //导入依赖包
2 const http = require("http");
3 const path = require("path");
const url = require("url");
const fs = require("fs");
const superagent = require("superagent");
const cheerio = require("cheerio");
superagent
.get("https://www.zhipin.com/job_detail/?city=100010000&source=10&query=%E5%89%8D%E7%AB%AF")
.end((error, response) => {
//获取页面文档数据
var content = response.text;
//cheerio也就是nodejs下的jQuery 将整个文档包装成一个集合,定义一个变量$接收
var $ = cheerio.load(content);
//定义一个空数组,用来接收数据
var result = [];
//分析文档结构 先获取每个li 再遍历里面的内容(此时每个li里面就存放着我们想要获取的数据)
$(".job-list li .job-primary").each((index, value) => {
//地址和类型为一行显示,需要用到字符串截取
//地址
let address = $(value).find(".info-primary").children().eq(1).html();
//类型
let type = $(value).find(".info-company p").html();
//解码
address = unescape(address.replace(/&#x/g, '%u').replace(/;/g, ''));
type = unescape(type.replace(/&#x/g, '%u').replace(/;/g, ''))
//字符串截取
let addressArr = address.split('<em class="vline"></em>');
let typeArr = type.split('<em class="vline"></em>');
//将获取的数据以对象的形式添加到数组中
result.push({
title: $(value).find(".name .job-title").text(),
money: $(value).find(".name .red").text(),
address: addressArr,
company: $(value).find(".info-company a").text(),
type: typeArr,
position: $(value).find(".info-publis .name").text(),
txImg: $(value).find(".info-publis img").attr("src"),
time: $(value).find(".info-publis p").text()
});
// console.log(typeof $(value).find(".info-primary").children().eq(1).html());
});
//将数组转换成字符串
result = JSON.stringify(result);
//将数组输出到json文件里 刷新目录 即可看到当前文件夹多出一个boss.json文件(打开boss.json文件,ctrl+A全选之后 ctrl+K,再Ctrl+F即可将json文件自动排版)
fs.writeFile("boss.json", result, "utf-8", (error) => {
//监听错误,如正常输出,则打印null
if (error == null) {
console.log("恭喜您,数据爬取成功!请打开json文件,先Ctrl+A,再Ctrl+K,最后Ctrl+F格式化后查看json文件(仅限Visual Studio Code编辑器)");
}
});
});
4.更改数据(如果是静态页面上面的操作基本上就已经完成了 直接node .\cralwer.js,但是现实中很多都不是)
1.在游览器中输入想要爬取的地址
例如:https://www.zhipin.com/job_detail/?city=100010000&source=10&query=%E5%89%8D%E7%AB%AF
2.进入控制台选中body copy element
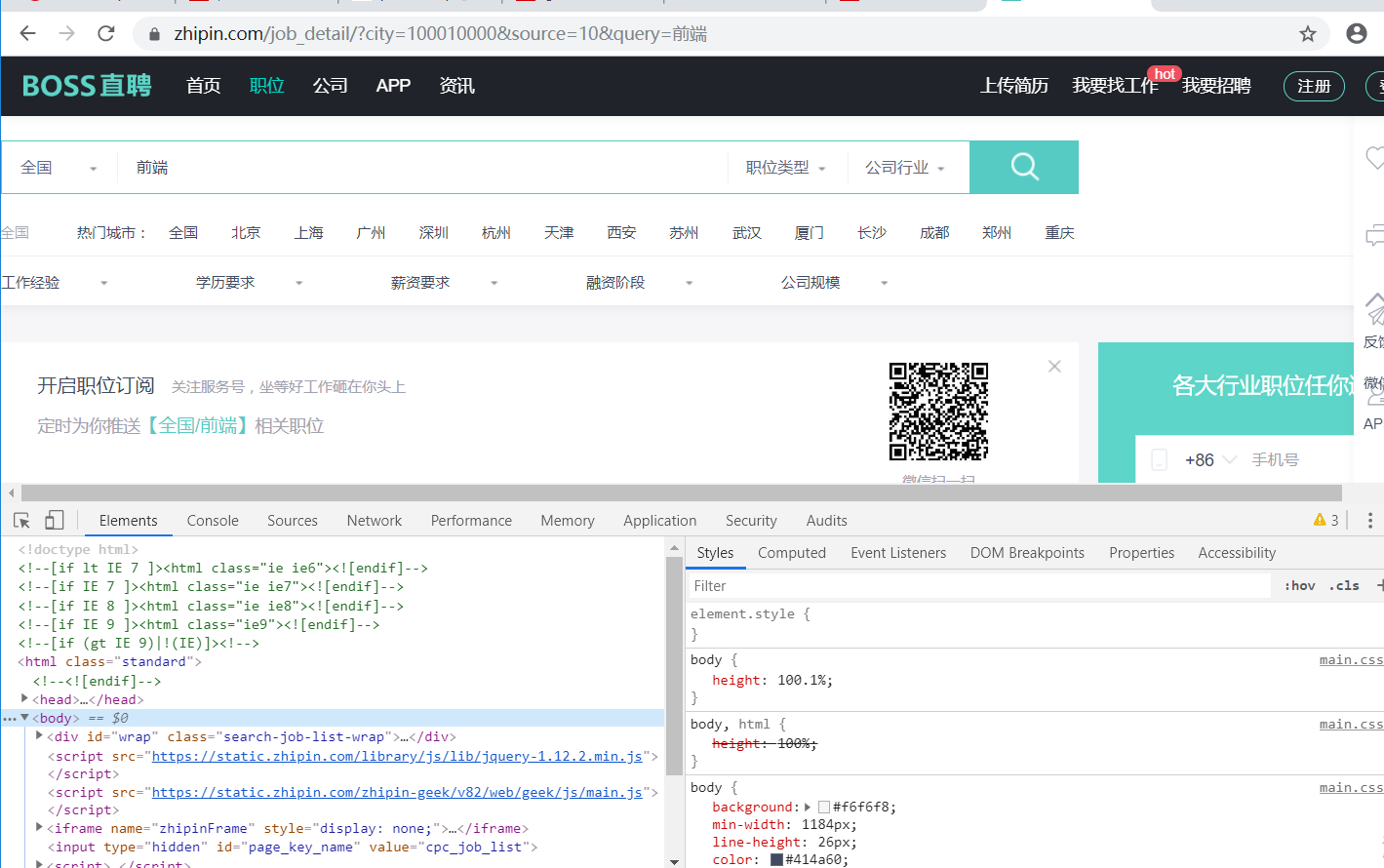
3.在编辑器中粘贴即可
5.在服务器环境下运行这个网页

7.复制这个地址栏地址
然后粘贴在文件 cralwer.js .get()中
8. 在终端中运行
node .\cralwer.js
最后 本文借鉴于https: //blog.csdn.net/twodogya/article/details/80204322
轻松上手nodeJs爬取想要页面的数据的更多相关文章
- [爬虫]采用Go语言爬取天猫商品页面
最近工作中有一个需求,需要爬取天猫商品的信息,整个需求的过程如下: 修改后端广告交易平台的代码,从阿里上传的素材中解析url,该url格式如下: https://handycam.alicdn.com ...
- Python 2.7_爬取CSDN单页面利用正则提取博客文章及url_20170114
年前有点忙,没来的及更博,最近看爬虫正则的部分 巩固下 1.爬取的单页面:http://blog.csdn.net/column/details/why-bug.html 2.过程 解析url获得网站 ...
- 以豌豆荚为例,用 Scrapy 爬取分类多级页面
本文转载自以下网站:以豌豆荚为例,用 Scrapy 爬取分类多级页面 https://www.makcyun.top/web_scraping_withpython17.html 需要学习的地方: 1 ...
- 大神:python怎么爬取js的页面
大神:python怎么爬取js的页面 可以试试抓包看看它请求了哪些东西, 很多时候可以绕过网页直接请求后面的API 实在不行就上 selenium (selenium大法好) selenium和pha ...
- Python 2.7_爬取CSDN单页面博客文章及url(二)_xpath提取_20170118
上次用的是正则匹配文章title 和文章url,因为最近在看Scrapy框架爬虫 需要了解xpath语法 学习了下拿这个例子练手 1.爬取的单页面还是这个rooturl:http://blog.csd ...
- python 爬取天猫美的评论数据
笔者最近迷上了数据挖掘和机器学习,要做数据分析首先得有数据才行.对于我等平民来说,最廉价的获取数据的方法,应该是用爬虫在网络上爬取数据了.本文记录一下笔者爬取天猫某商品的全过程,淘宝上面的店铺也是类似 ...
- 通过scrapy,从模拟登录开始爬取知乎的问答数据
这篇文章将讲解如何爬取知乎上面的问答数据. 首先,我们需要知道,想要爬取知乎上面的数据,第一步肯定是登录,所以我们先介绍一下模拟登录: 先说一下我的思路: 1.首先我们需要控制登录的入口,重写star ...
- Java爬虫系列四:使用selenium-java爬取js异步请求的数据
在之前的系列文章中介绍了如何使用httpclient抓取页面html以及如何用jsoup分析html源文件内容得到我们想要的数据,但是有时候通过这两种方式不能正常抓取到我们想要的数据,比如看如下例子. ...
- Python3爬取王者官方网站英雄数据
爬取王者官方网站英雄数据 众所周知,王者荣耀已经成为众多人们喜爱的一款休闲娱乐手游,今天就利用python3 爬虫技术爬取官方网站上的几十个英雄的资料,包括官方给出的人物定位,英雄名称,技能名称,CD ...
随机推荐
- REINDEX - 重建索引
SYNOPSIS REINDEX { DATABASE | TABLE | INDEX } name [ FORCE ] DESCRIPTION 描述 REINDEX 基于存储在表上的数据重建索引, ...
- windows server 2008R2 配置tomcat服务开机自启动
一.配置环境 操作系统:Windows server 2008 R2 软件包:jdk_1.7.rar 二.安装操作 1,右击解压jdk_1.7.rar:解压后双击运行jdk-7u79-windows- ...
- kotlin中实现匿名内部类
1.常规的方式实现匿名内部类 valueAnimator.addUpdateListener(object :AnimatorUpdateListener { override fun onAnima ...
- demo板 apt-get install stress
demo 那个网口 没有绑定mac 大电脑绑定了mac 大电脑上网认证系统:http://1.1.1.2 大电脑mac:6C-4B-90-3C-D5-7B 将demo板的mac改为大电脑mac ifc ...
- spring的统一进行异常处理
public class ExceptionHandler extends SimpleMappingExceptionResolver { private static final Logger l ...
- Python"sorted()"和".sort()"的区别
sorted(A-LIST)会返回一个新的object,不改变**A-LIST*本身. A-LIST.sort()会直接改变A-List,不产生新的object.
- springBoot03- springboot+jpa+thymeleaf增删改查
参考http://www.mooooc.com/springboot/2017/09/23/spring-boot-jpa-thymeleaf-curd.html 数据库: CREATE TABLE ...
- 远程仓库(GitHub)的使用
1.注册登录 在 GitHub 上注册登录 暂时忽略不讲 2.创建新的远程仓库 在GitHub网站上创建新的仓库.不管你是先在本地创建仓库还是先在远程创建仓库,要想把代码提交到远程仓库都是要先手动创建 ...
- 26 October in 614
Practice tower 有 \(N\,(2\le N\le 600000)\) 块砖,要搭一个 \(N\) 层的塔,要求:如果砖 \(A\) 在砖 \(B\) 上面,那么 \(A\) 不能比 \ ...
- 汇编指令ADD
格式: ADD OPRD1,OPRD2 功能: 两数相加(不带进位) 例子: add ax,bx add ax,ax 解释: