第3章 JDK并发包(四)
3.2.5 自定义线程创建:ThreadFactory
- 线程池的主要作用是为了线程复用,也就是避免了线程的频繁创建。
- ThreadFactory是一个接口,它只有一个方法,用来创建线程:
Thread newThread(Runnable r);
- 当线程池需要新建线程时,就会调用这个方法。
- 下面的案例使用自定义的ThreadFactory,一方面记录了线程的创建,另一方面将所有的线程都设置为守护线程,这样,当主线程退出后,将会强制销毁线程池。
public static void main(String[] args) throws InterruptedException {
MyTask task = new MyTask();
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new SynchronousQueue<Runnable>(),
new ThreadFactory(){
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setDaemon(true);
System.out.println("create " + t);
return t;
}
});
for (int i = 0; i < 5; i++) {
es.submit(task);
}
Thread.sleep(2000);
}
3.2.6 我的应用我做主:扩展线程池
- 一个好消息是:ThreadPoolExecutor也是一个可以扩展的线程池。它提供了beforeExecute()、afterExecute()和terminated()三个接口对线程池进行控制。
- 以beforeExecute()、afterExecute()为例,在ThreadPoolExecutor.Worker.runTask()方法内部提供了这样的实现:
boolean ran = false;
beforeExecute(thread, task); //运行前
try {
task.run(); //运行任务
ran = true;
afterExecute(task, null); //运行结束后
++completedTasks;
} catch (RuntimeException ex) {
if (!ran) {
afterExecute(task, ex); //运行结束
}
throw ex;
}
- ThreadPoolExecutor.Worker是ThreadPoolExecutor的内部类,它是一个实现了Runnable接口的类。ThreadPoolExecutor线程池的工作线程也正是Worker实例。Worker.runTask()方法会被线程池以多线程 模式异步调用,即Worker.runTask()会同时被多个线程访问。因此其beforeExecute()、afterExecute()接口也将同时多线程访问。
- 在默认的ThreadPoolExecutor实现中,提供了空的beforeExecute()和afterExecute()实现。在实际应用中,可以对其进行扩展来实现对线程池运行状态的跟踪,输出一些有用的调试信息,以帮助系统故 障诊断,这对于多线程程序错误排查是很有帮助的。下面演示了对线程池的扩展,在这个扩展中,我们将记录每一个任务的执行日志。
public class ExtThreadPool {
public static class MyTask implements Runnable {
public String name;
public MyTask(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println("正在执行" + ":Thread ID:" + Thread.currentThread().getId() + ",Task Name=" + name);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONEDS,
new LinkedBloackingQueue<Runnable>()) {
@Override
protected void beforeExecute(Thread t, Runnable r) {
System.out.println("准备执行:" + ((MyTask) r).name);
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
System.out.println("执行完成" + ((MyTask) r).name);
}
@Override
protected void terminated() {
System.out.println("线程池退出");
}
};
for (int i = 0; i < 5; i++) {
MyTask task = new MyTask("TASK-GEYM-" + i);
es.execute(task);
Thread.sleep(10);
}
es.shutdown();
}
}
- 上述代码中,扩展了原有的线程池,实现了beforeExecute()、afterExecute()和termininated()三个方法。这个三个方法分别用于记录一个任务的开始、结束和整个线程池的退出。在es.execute(task)中,向线程池提交5个任务,为了有更清晰的日志,我们为每个任务都取了一个不同的名字。
- 在提交完成后,调用shutdown()方法关闭线程池。这是一个比较安全的方法,如果当前正有线程在执行,shutdown()方法并不会立即暴力地终止所有任务,它会等待所有任务执行完成后,再关闭线程池,但它并不会等待所有线程执行完成后再返回,因此,可以简单地理解成shutdown()只是发送了一个关闭信号而已。但在shutdown()方法执行后,这个线程池就不能再接受其他新的任务了。
- 执行上述代码,可以得到类似以下的输出:
准备执行:TASK-GEYM-0
正在执行:Thread ID:11,Task Name=TASK-GEYM-0
准备执行:TASK-GEYM-1
正在执行:Thread ID:12,Task Name=TASK-GEYM-1
准备执行:TASK-GEYM-2
正在执行:Thread ID:13,Task Name=TASK-GEYM-2
准备执行:TASK-GEYM-3
正在执行:Thread ID:14,Task Name=TASK-GEYM-3
准备执行:TASK-GEYM-4
正在执行:Thread ID:15,Task Name=TASK-GEYM-4
执行完成TASK-GEYM-0
执行完成TASK-GEYM-1
执行完成TASK-GEYM-2
执行完成TASK-GEYM-3
执行完成TASK-GEYM-4
线程池退出
3.2.7 合理的选择:优化线程池线程数量
线程池的大小对系统的性能有一定的影响。一般来说,确定线程池的大小需要考虑CPU数量、内存大小等因素。估算线程池大小的经验公式:

在Java中,可以通过:
Runtime.getRuntime().availableProcessors()
- 取得可用的CPU数量。
3.2.8 堆栈去哪里了:在线程池中寻找堆栈
- 下面来看一下简单的案例,首先,我们有一个Runnable接口,它用来计算两个数的商:
public class DivTask implements Runnable {
int a, b;
public DivTask(int a, int b) {
this.a = a;
this.b = b;
}
@Override
public void run() {
double re = a / b;
System.out.println(re);
}
}
- 如果程序运行了这个任务,那么我们期待它可以打印出给定两个数的商。现在我们构造几个这样的任务,希望程序可以为我们计算一组给定数组的商。
public static void main(String[] args) throws InterruptedException, ExecutionException {
ThreadPoolExecutor pools = new ThreadPoolExecutor(0, Integer.MAX_VALUE,
0L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
for (int i = 0; i < 5, i++) {
pools.submit(new DivTask(100, i));
}
}
- 上述代码将DivTask提交到线程池,从这个for循环来看,我们应该会得到5个结果,分别是100除以给定的i后的商。但如果你真的运行程序,你得到的全部结果是:
33.0
50.0
100.0
25.0
- 线程池吃掉了除以0的异常。
- 向线程池讨回异常堆栈的方法。
- 一种最简单的方法,就是放弃submit(),改用execute()。
pools.execute(new DivTask(100, i));
- 或者你使用下面的方法改造submit():
Future re = pools.submit(new DivTask(100, i));
re.get();
上面这两种方法可以得到部分堆栈信息,如下所示。


扩展我们的ThreadPoolExecute线程池,让它在调度任务之前,先保存一下提交任务线程的堆栈信息。如下所示:
public class TraceThreadPoolExecutor extends ThreadPoolExecutor {
public TraceThreadPoolExecutor(int corePoolSize, int maximumPoolSize,
long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
@Override
public void execute(Runnable task) {
super.execute(wrap(task, clientTrace(), Thread.currentThread().getName()));
}
@Override
public Future<?> submit(Runnable task) {
return super.submit(wrap(task, clientTrace(), Thread.currentThread().getName()));
}
private Exception clientTrace() {
return new Exception("Client stack trace");
}
private Runnable wrap(final Runnable task, final Exception clientStack, String clientThreadName) {
return new Runnable() {
@Override
public void run() {
try {
task.run();
} catch (Exception e) {
clientStack.printStackTrace();
throw e;
}
}
}
}
}
- wrap()方法的第2个参数为一个异常,里面保存着提交任务的线程的堆栈信息。该方法将我们传入的Runnable任务进行一层包装,使之能处理异常信息。当任务发生异常时,这个异常会被打印。
- 可以使用TraceThreadPoolExecutor来尝试执行这段代码了:
public static void main(String[] args) {
ThreadPoolExecutor pools = new TraceThreadPoolExecutor(0, Integer.MAX_VALUE,
0L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
//错误堆栈中可以看到是在哪里提交的任务
for (int i = 0; i < 5; i++) {
pools.execute(new DivTask(100, i));
}
}
- 执行上述代码,就可以得到以下信息:


3.2.9 分而治之:Fork/Join框架
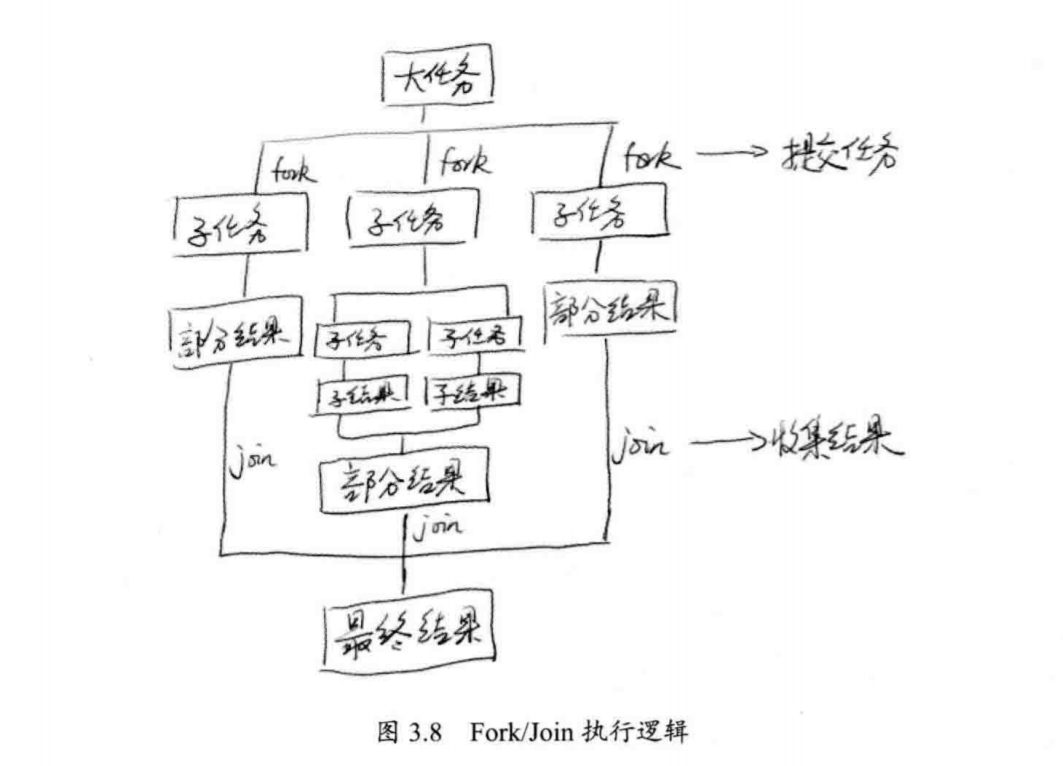
使用fork()后系统多了一个执行分支(线程),所以需要等待这个执行分支执行完毕,才有可能得到最终的结果,因此join()就表示等待。
使用Fork/Join进行数据处理时的总体结构如图3.8所示。
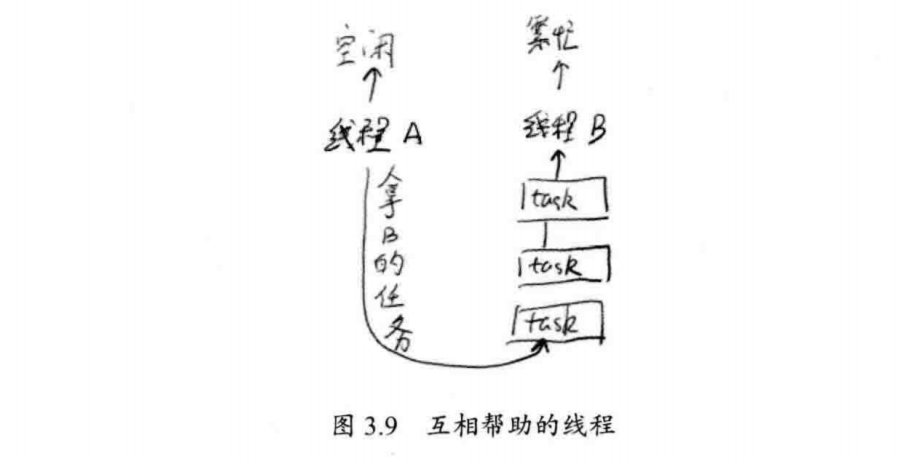
如图3.9所示,显示线程互相帮助的过程。
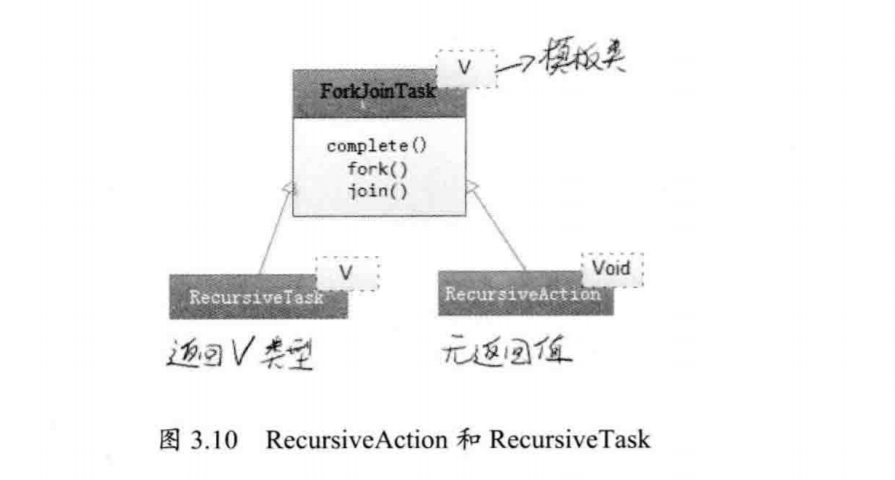
下面看一下ForkJoinPool的一个重要的接口:
public <T> ForkJoinPool<T> submit(ForkJoinTask<T> task)
你可以向ForkJoinPool线程池提交一个ForkJoinTask任务。所谓ForkJoinTask任务就是支持fork()分解以及join()等待的任务。ForkJoinTask有两个重要的子类,RecursiveAction和RecursiveTask。它们分别表示没有返回值的任务和可以携带返回值得任务。图3.10显示了这个类的作用和区别。
下面我们简单地展示Fork/Join框架的使用,这里用来计算数列求和。
public class CountTask extends RecursiveTask<Long> {
private static final int THRESHOLD = 10000;
private long start;
private long end;
public CountTask(long start, long end) {
this.start = start;
this.end = end;
}
public Long compute() {
long sum = 0;
boolean canCompute = (end - start) < THRESHOLD;
if (canCompute) {
for (long i = start; i <= end; i++) {
sum += i;
}
} else {
//分成100个小任务
long step = (start + end) / 100;
ArrayList<CountTask> subTasks = new ArrayList<CountTask>();
long pos = start;
for (int i = 0; i < 100; i++) {
long lastOne = pos + step;
if (lastOne > end) lastOne = end;
CountTask subTask = new CountTask(pos, lastOne);
pos += step + 1;
subTasks.add(subTask);
subTask.fork();
}
for (CountTask t : subTasks) {
sum += t.join();
}
}
return num;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
CountTask task = new CountTask(0, 200000L);
ForkJoinTask<Long> result = forkJoinPool.submit(task);
try {
long res = result.get();
System.out.println("sum =" + res);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}


第3章 JDK并发包(四)的更多相关文章
- 第3章 JDK并发包(三)
3.2 线程复用:线程池 一种最为简单的线程创建和回收的方法类似如下代码: new Thread(new Runnable() { @Override public void run() { // d ...
- 第3章 JDK并发包(五)
3.3 不要重复发明轮子:JDK的并发容器 3.3.1 超好用的工具类:并发集合简介 JDK提供的这些容器大部分在java.util.concurrent包中. ConcurrentHashMap:这 ...
- 第3章 JDK并发包(二)
3.1.2 重入锁的好搭档:Condition条件 它和wait()和notify()方法的作用是大致相同的.但是wait()和notify()方法是和synchronized关键字合作使用的,而Co ...
- 第3章 JDK并发包(一)
3.1 多线程的团队协作:同步控制 3.1.1 synchronized的功能扩展:重入锁 重入锁可以完全替代synchronized关键字. 重入锁使用java.util.concurrent.lo ...
- Java 并发编程实践基础 读书笔记: 第三章 使用 JDK 并发包构建程序
一,JDK并发包实际上就是指java.util.concurrent包里面的那些类和接口等 主要分为以下几类: 1,原子量:2,并发集合:3,同步器:4,可重入锁:5,线程池 二,原子量 原子变量主要 ...
- Java并发程序设计(四)JDK并发包之同步控制
JDK并发包之同步控制 一.重入锁 重入锁使用java.util.concurrent.locks.ReentrantLock来实现.示例代码如下: public class TryReentrant ...
- 3 JDK并发包
JDK内部提供了大量实用的API和框架.本章主要介绍这些JDK内部功能,主要分为3大部分: 首先,介绍有关同步控制的工具,之前介绍的synchronized就是一种同步控制手段,将介绍更加丰富的多线程 ...
- Java多线程--JDK并发包(2)
Java多线程--JDK并发包(2) 线程池 在使用线程池后,创建线程变成了从线程池里获得空闲线程,关闭线程变成了将线程归坏给线程池. JDK有一套Executor框架,大概包括Executor.Ex ...
- Java多线程--JDK并发包(1)
Java多线程--JDK并发包(1) 之前介绍了synchronized关键字,它决定了额一个线程是否可以进入临界区:还有Object类的wait()和notify()方法,起到线程等待和唤醒作用.s ...
随机推荐
- 利用cuteftp上传并修改网站上内容
1.下载cuteftp 2.在host中输入网址(如:219.142.121.2) 3.username中输入(如:BNULS) 4.passpord中输入:(如410teamgood) 5.端口输入 ...
- bash的默认组合键
组合键 组合按键 执行结果 Ctrl+C 终止目前的命令 Ctrl+D 输入结束(EOF),例如邮件结束的时候 Ctrl+M 就是Enter啦! Ctrl+S 暂停屏幕输出 Ctrl+Q 恢复屏幕输出 ...
- HashMap 源码赏析 JDK8
一.简介 HashMap源码看过无数遍了,但是总是忘,好记性不如烂笔头. 本文HashMap源码基于JDK8. 文章将全面介绍HashMap的源码及HashMap存在的诸多问题. 开局一张图,先来看看 ...
- swiper如何禁止左右箭头切换
swiper做项目时,需求 带着左右两边的箭头, 场景1:swiper自动切换,此时左右箭头点击时不能切换 场景2:swiper手动切换,左右箭头可以实现切换,通过翻阅api 终于找到 <s ...
- 消息队列rabbitmq的五种工作模式(go语言版本)
前言:如果你对rabbitmq基本概念都不懂,可以移步此篇博文查阅消息队列RabbitMQ 一.单发单收 二.工作队列Work Queue 三.发布/订阅 Publish/Subscribe 四.路由 ...
- mysql 行增删改查
一.增 ); ),(); insert into student(name, age) select name, age from info; 二.删 delete from db1; delete ...
- Java框架之MyBatis 06-全局配置-mapper映射-分步查询
MyBatis MyBatis是Apache的一个开源项目iBatis, iBatis一词来源于“internet”和“abatis”的组合,是一个基于Java的持久层框架. iBatis 提供的持 ...
- Shell命令整理
Shell命令 一.认识Shell 在Linux系统中,Shell充当着用户与Linux内核的桥梁,俗称壳保护着Linux内核,同时也负责完成用户与内核之间的交互. 当用户需要与内核交互时,将命令传递 ...
- python多层数组合成一个数组后循环打印出数组内的每一项元素的方法
a=[1,2,3,4] b=[5,6,7,8] c=[a,b] def test(c): for i in c: return i print(test(c)) 以上代码执行后打印出来的结果是 预期目 ...
- 链接拼接的方法(用于解决同一个脚本返回两种不同的url链接的问题)
实例一: 上图所示 爬虫返回的链接有一部分带有http前缀,有一部分没有,且也不知道具体哪些链接会出现没有前缀的情况 后面如果通过返回链接进行再次访问,那么肯定会出现报错的问题 思路: 判断 返回值内 ...