数据预处理 | 使用 OneHotEncoder 及 get_dummuies 将分类型数据转变成哑变量矩阵
【分类数据的处理】
问题:
在数据建模过程中,很多算法或算法实现包无法直接处理非数值型的变量,如 KMeans 算法基于距离的相似度计算,而字符串则无法直接计算距离
如:
性别中的男和女 [0,1] [1,0]
用户的价值度分为高、中、低
处理方法:
将字符串表示的 分类特征 转换成 数值 类型(哑变量矩阵)
导入数据:
import pandas as pd
from sklearn.preprocessing import OneHotEncoder # 生成数据
df = pd.DataFrame({'id': [3566841, 6541227, 3512441],
'sex': ['male', 'Female', 'Female'],
'level': ['high', 'low', 'middle'],
'score': [1, 2, 3]})

方法 1 :使用 sklearn 库的 OneHotEncoder
# 获得ID列(还保留二维的形式,等一会儿还要拼回去)
id_data = df[['id']]
# 指定要转换的列
test_data = df.iloc[:,1:] # 建立标志转换模型对象(也称为哑编码对象)
onehot_model = OneHotEncoder()
df1 = onehot_model.fit_transform(test_data).toarray() # 拼接
df_all = pd.concat((id_data, pd.DataFrame(df1)), axis=1)

完成转换~
注:
1> 通过 OneHotEncoder 后,得到一个矩阵对象,
# 得到的 df1 是一个矩阵对象 <3x8 sparse matrix of type '<class 'numpy.float64'>'
df1 = onehot_model.fit_transform(test_data)

2> 矩阵进行 toarray() 后,得到 array 对象, 得到的 array 要进一步转化成 DataFrame,才能使用 pd.concat 完成拼接
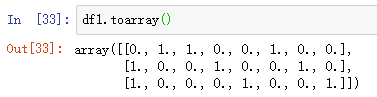
df1 = pd.DataFrame(df1.toarray())
df_all = pd.concat([id_data,df1],axis=1)
方法二:使用 pandas 的 get_dummuies
此方法只会对非数值类型的数据做转换
id_data = df.id
test_data = df.iloc[:,1:] test_data_dum = pd.get_dummies(test_data) # 核心代码
df_dum = pd.concat([id_data, test_data_dum],axis=1)
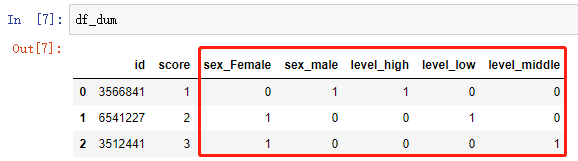
保留数值型特征 score,对非数值型的 sex 和 level 进行了转换
数据预处理 | 使用 OneHotEncoder 及 get_dummuies 将分类型数据转变成哑变量矩阵的更多相关文章
- 机器学习实战基础(十一):sklearn中的数据预处理和特征工程(四) 数据预处理 Preprocessing & Impute 之 处理分类特征:编码与哑变量
处理分类特征:编码与哑变量 在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的 ...
- sklearn preprocessing 数据预处理(OneHotEncoder)
1. one hot encoder sklearn.preprocessing.OneHotEncoder one hot encoder 不仅对 label 可以进行编码,还可对 categori ...
- Python数据预处理:机器学习、人工智能通用技术(1)
Python数据预处理:机器学习.人工智能通用技术 白宁超 2018年12月24日17:28:26 摘要:大数据技术与我们日常生活越来越紧密,要做大数据,首要解决数据问题.原始数据存在大量不完整.不 ...
- 吴裕雄 python 机器学习——数据预处理二元化OneHotEncoder模型
from sklearn.preprocessing import OneHotEncoder #数据预处理二元化OneHotEncoder模型 def test_OneHotEncoder(): X ...
- 机器学习实战基础(十二):sklearn中的数据预处理和特征工程(五) 数据预处理 Preprocessing & Impute 之 处理分类特征:处理连续性特征 二值化与分段
处理连续性特征 二值化与分段 sklearn.preprocessing.Binarizer根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量.大于阈值的值映射为1,而小于或等于阈值的值 ...
- 数据准备<3>:数据预处理
数据预处理是指因为算法或者分析需要,对经过数据质量检查后的数据进行转换.衍生.规约等操作的过程.整个数据预处理工作主要包括五个方面内容:简单函数变换.标准化.衍生虚拟变量.离散化.降维.本文将作展开介 ...
- 【sklearn】数据预处理 sklearn.preprocessing
数据预处理 标准化 (Standardization) 规范化(Normalization) 二值化 分类特征编码 推定缺失数据 生成多项式特征 定制转换器 1. 标准化Standardization ...
- 第一章:AI人工智能 の 数据预处理编程实战 Numpy, Pandas, Matplotlib, Scikit-Learn
本课主题 数据中 Independent 变量和 Dependent 变量 Python 数据预处理的三大神器:Numpy.Pandas.Matplotlib Scikit-Learn 的机器学习实战 ...
- sklearn学习笔记(一)——数据预处理 sklearn.preprocessing
https://blog.csdn.net/zhangyang10d/article/details/53418227 数据预处理 sklearn.preprocessing 标准化 (Standar ...
随机推荐
- Arm开发板+Qt学习之路
从2015.11.13日开始接触arm开发板,开始学习Qt,到现在已经四个月零17天了,从一个拿到开发板一无所知的小白,到现在能够在开发板上进行开发,有付出有收获. 之前一直没有时间将这个过程中的一些 ...
- 移动app
什么是移动App开发[重点] 苹果上的软件是如何开发出来的:使用IOS平台的开发工具和开发语言进行设计开发的!苹果上的开发语言:OC.Swift 安卓平台上的软件又是如何开发出来的:使用Java这么语 ...
- STM32存储器映射和寄存器映射
存储器映射 对于Cortex-M3来讲,有一块4G大小的存储器空间.存储器映射指的是芯片厂商为这个空间分配地址的操作.这4G空间被均匀地划分为8个大小为512MB的存储块(block),并且每个块都各 ...
- C#实现的Table的Merge,以及实现Table的Copy和Clone
C#实现的对两个Table进行Merge,两表必须存在至少一个公共栏位作为连接项,否则连接就失去了意义.如下是对两个table进行Merge的详细代码: private void button1_Cl ...
- gcc 将两个文件合成一个文件(c)
一个文件是: 一个文件是: 两个文件的作用是输出一段文字,其中一个文件调用了另一个文件 gcc 命令为: -c 生成了object 文件,-o 生成了可执行文件,并且合成.
- P2024 NOI2001 种类冰茶鸡
展开 题目描述 动物王国中有三类动物 A,B,C,这三类动物的食物链构成了有趣的环形.A 吃 B,B 吃 C,C 吃 A. 现有 N 个动物,以 1 - N 编号.每个动物都是 A,B,C 中的一种, ...
- 码云配合git入门命令总结学习
目录 码云配合git入门命令总结学习 基本设置 基本命令总结学习 准备工作以及基本思路 基本命令 码云搭建仓库步骤 准备前工作 具体操作方法 远程仓库基本命令 标签相关命令 所有命令总结 基本命令总结 ...
- css的网页布局案例
常见行布局: 导航使用position:fixed固定住 导航会脱离文档流,不占据空间 导致下面的元素上移,因此需要将下面的元素的padding-top设置成导航的高度 <!DOCTYPE ht ...
- Angular2的环境构筑
1.nodejs安装 https://nodejs.org/en/download/ 2.环境变量设定 Path->\node-v10.16.3-win-x64 3.在cmd下输 ...
- opencv —— erode、dilate 腐蚀与膨胀
腐蚀与膨胀是形态学滤波.其中,腐蚀是最小值滤波,膨胀是最大值滤波,即分别选取内核中的最小值与最大值赋值给锚点.若内核为 N×1 或 1×N 形状,可用于横纵方向直线检测. 膨胀:dilate 函数 v ...