ElasticSearch集群-Windows
概述
ES集群是一个P2类型的分布式系统,除了集群状态管理以外,其他所有的请求都可以发送到集群内任意一台节点上,这个节点可以自己找到需要转发给哪些节点,并且直接跟这些节点通信。所以,从网络架构及服务配置上来说,构建集群需要的配置及其简单。在Elasticsearch2.0之前,无阻碍的网络下,所有配置了相同cluster.name的节点都自动归属到一个集群中。2.0版本之后,基于安全的考虑避免开发环境过于随便造成的麻烦,从2.0版本开始,默认的自动发现方式改为了单播(unicast)方式。配置里提供几台节点的地址,ES将其视作gossip router角色,借以完成集群的发现。由于这只是ES内一个很小的功能,所以gossip router角色并不需要单独配置,每个ES节点都可以担任。所以,采用单播方式的集群,各节点都配置相同的几个节点列表作为router即可。
集群中节点数量没有限制,一般大于等于2个节点就可以看做是集群了。一般处于高性能及高可用方面来考虑一般集群中的节点数量都是3个及3个以上。
集群的相关概念
1.集群cluster
一个集群就是由一个或多个节点组织一起,它们共同有整个的数据,并一起提供索引和搜索功能。一个集群有一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。
2.节点node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确认网络中的哪些服务器对应于elasticsearch集群中的哪些节点;
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中;
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何elasticsearch节点,这是启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
3.分片和复制 shards&replicas
集群的搭建
1.准备三台elasticsearch服务器
2.修改每台服务器配置
node1节点:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-
#必须为本机的ip地址
network.host: 127.0.0.1
#服务器端口号,在同一机器下必须不一样
http.port:
#集群间通讯的端口号,同一机器下必须不一样
transport.tcp.port:
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"] http.cors.enabled: true
http.cors.allow-origin: "*"
node2节点:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-
#必须为本机的ip地址
network.host: 127.0.0.1
#服务器端口号,在同一机器下必须不一样
http.port:
#集群间通信端口号,同一机器下必须不一样
transport.tcp.port: 9301
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"] http.cors.enabled: true
http.cors.allow-origin: "*"
node3节点:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-#本机的ip地址
network.host: 127.0.0.1
#服务器端口号
http.port:
#集群间通信端口号
transport.tcp.port: #设置集群自动发现机器的ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"] http.cors.enabled: true
http.cors.allow-origin: "*"
注意:如果你是复制以前使用过的elasticsearch,需要将三个集群的【data】文件夹分别删除,否则会有异常;
3.分别启动三个集群的服务器elasticsearch.bat
使用如下地址查看集群的状态
http://127.0.0.1:9200/_cat/nodes?v

4.启动elasticsearch-head-master服务
5.添加索引和映射
5.1 请求的url (请求方式PUT)
http://localhost:9200/wn_1
5.2 请求体
{
"mappings": {
"article": {
"properties": {
"id": {
"type": "long",
"store": true,
"index":"not_analyzed"
},
"title": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"ik_max_word"
},
"content": {
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"ik_max_word"
}
}
}
}
}
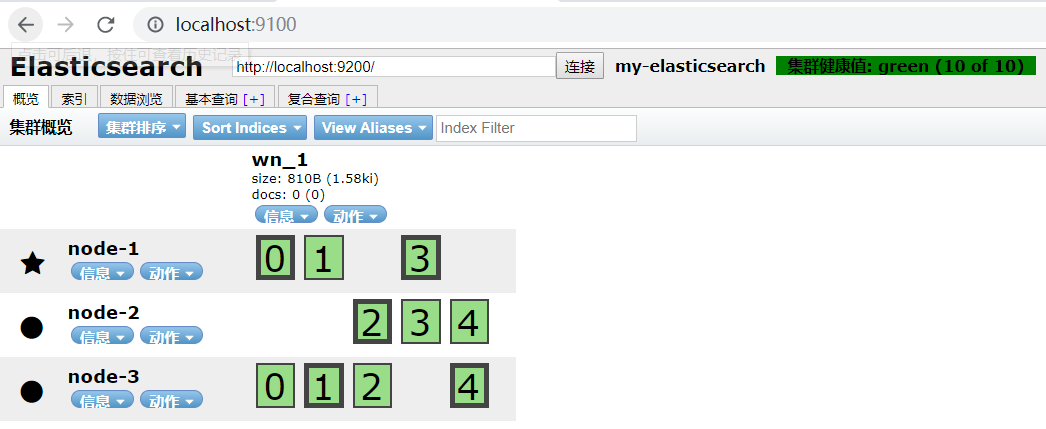
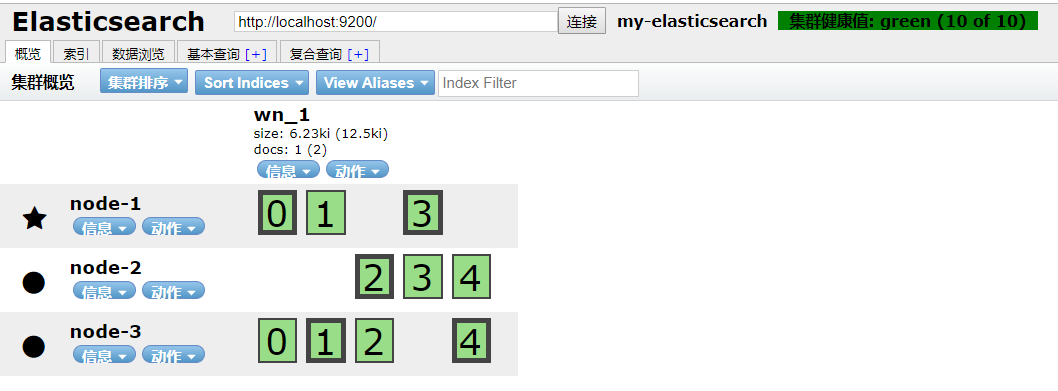
5.3 效果实现
6.添加文档
6.1 请求的url(请求方式post)
http://localhost:9200/wn_1/article/1
6.2 请求体
{
"id":,
"title":"ElasticSearch是一个基于Lucene的搜索服务器",
"content":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTfulweb接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。"
}
6.3 效果实现

ElasticSearch集群-Windows的更多相关文章
- ES2:ElasticSearch 集群配置
ElasticSearch共有两个配置文件,都位于config目录下,分别是elasticsearch.yml和logging.yml,其中,elasticsearch.yml 用来配置Elastic ...
- Elasticsearch集群 管理
第7章 深入Elasticsearch集群 启动一个Elasticsearch节点时,该节点会开始寻找具有相同集群名字并且可见的主节点.如 果找到主节点,该节点加入一个已经组成了的集群:如果没有找到, ...
- 【Elasticsearch】深入Elasticsearch集群
7.1 节点发现启动Elasticsearch的时候,该节点会寻找有相同集群名字且课件的主节点,如果有加入,没有自己成为主节点,负责发现的模块两个目的 选出主节点以及发现集群的新节点7.1.1发现的类 ...
- ElasticSearch实战系列一: ElasticSearch集群+Kinaba安装教程
前言 本文主要介绍的是ElasticSearch集群和kinaba的安装教程. ElasticSearch介绍 ElasticSearch是一个基于Lucene的搜索服务器,其实就是对Lucene进行 ...
- Elasticsearch集群搭建教程及生产环境配置
Elasticsearch 是一个极其强大的搜索和分析引擎,其强大的部分在于能够对其进行扩展以获得更好的性能和稳定性. 本教程将提供有关如何设置 Elasticsearch 集群的一些信息,并将添加一 ...
- Ubuntu 14.04中Elasticsearch集群配置
Ubuntu 14.04中Elasticsearch集群配置 前言:本文可用于elasticsearch集群搭建参考.细分为elasticsearch.yml配置和系统配置 达到的目的:各台机器配置成 ...
- elasticsearch 集群
elasticsearch 集群 搭建elasticsearch的集群 现在假设我们有3台es机器,想要把他们搭建成为一个集群 基本配置 每个节点都要进行这样的配置: cluster.name: ba ...
- 我的ElasticSearch集群部署总结--大数据搜索引擎你不得不知
摘要:世上有三类书籍:1.介绍知识,2.阐述理论,3.工具书:世间也存在两类知识:1.技术,2.思想.以下是我在部署ElasticSearch集群时的经验总结,它们大体属于第一类知识“techknow ...
- Elasticsearch集群中处理大型日志流的几个常用概念
之前对于CDN的日志处理模型是从logstash agent==>>redis==>>logstash index==>>elasticsearch==>&g ...
随机推荐
- NMI计算
NMI计算 NMI(Normalized Mutual Information)标准化互信息,常用在聚类中,度量两个聚类结果的相近程度.是社区发现(community detection)的重要衡量指 ...
- LeetCode 第27题--移除元素
1. 题目 2.题目分析与思路 3.代码 1. 题目 给定 nums = [3,2,2,3], val = 3, 函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2. 你不需要考虑数组 ...
- render()到底渲染的什么?
1.格式 render(request,"xx.html",{"xx": xx}) 2.本质 通过模板语言动态渲染字符串(HTML文件) 注意: 1.HTML文 ...
- Unity3d游戏角色描边
本文发布于游戏程序员刘宇的个人博客,欢迎转载,请注明来源https://www.cnblogs.com/xiaohutu/p/10834491.html 游戏里经常需要在角色上做描边,这里总结一下平时 ...
- Java对接微信公众号模板消息推送
内容有点多,请耐心! 最近公司的有这个业务需求,又很凑巧让我来完成: 首先想要对接,先要一个公众号,再就是开发文档了:https://developers.weixin.qq.com/doc/offi ...
- 创建dynamics CRM client-side (十) - 用JS来获取form type
用户可以用以下代码来获取 form type 更多的信息可以查阅https://docs.microsoft.com/en-us/powerapps/developer/model-driven-ap ...
- Windows下安装Hadoop、Spark和HBase
1.Hadoop 安装Hadoop:下载hadoop-2.7.1.tar.gz,并解压到你想要的目录下,我放在D:\Library\hadoop-2.7.1. 配置Hadoop环境变量:HADOOP_ ...
- MAVEN报错Cannot access alimaven / idea data注解不好使
BUG 记录 报错页面的代码和截图: Cannot access alimaven (maven.aliyun.com/nexus/conte…..... 解决方法: 报错页面的代码和截图: JAR ...
- linux--->linux 各个文件夹及含义
1./bin 是binary的缩写 存放linux常用命令 2./lib 该目录用来存放系统动态链接共享库,几乎所有的应用程序都会用到该目录下的共享库. 3./dev 该目录包含了Linux系统中使用 ...
- MySQL 高可用之主从复制
MySQL主从复制简介 Mysql的主从复制方案,都是数据传输的,只不过MySQL无需借助第三方工具,而是自带的同步复制功能,MySQL的主从复制并不是磁盘上文件直接同步,而是将binlog日志发送给 ...