在线暴躁:<script />问题
WebMagic初探
先放上官网,更多资料可自行查阅:http://webmagic.io/docs/zh/
大致上WebMagic可以分为[Downloader、PageProcessor、Scheduler、Pipeline]四大组件,最外由Spider协调。可以灵活的定制组件功能,我们一次从0到1逐步分析这四大组件
写在前面:本篇目前只分析了爬取基本页面,至于前端渲染页面,后面做补充
Spider集大成者
Spiler协调四个组件。除了PageProcessor是在Spider创建的时候已经指定,
Downloader、Scheduler和Pipeline都可以通过Spider的setter方法来进行配置和更改。
addPipeline() //设置Pipeline,一个Spider可以有多个Pipeline
setDownloader //设置Downloader
setScheduler //设置Scheduler
public static void main(String[] args) {
Spider.create(new LianjiaProcessor())
.addUrl("https://cd.lianjia.com/zufang/")
.thread(5)
.addPipeline(new MyPipeline())
.run();
}
上面这个main方法,是我们今天Demo的一个启动类,可以看到,最外层由Spider进行启动和管理,上面已经指定了两个插件,分别是 [PageProcessor : new LianjiaProcessor()] ,以及 [Pipeline:new MyPipeline()],下面我开始入门
定制PageProcessor
PageProcessor组件可以理解为,这个类基本上包含了爬取一个网站,你需要写的所有代码
package com.example.webmagic.processor;
import com.example.webmagic.pipeline.MyPipeline;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
import java.util.List;
public class LianjiaProcessor implements PageProcessor {
//创建Site对象,设置重试次数以及爬完一个页面另开的间隔时间
private Site site = Site.me().setRetryTimes(3).setSleepTime(200);
@Override
public void process(Page page) {
//会得到一个html页面
Html html = page.getHtml();
//得到所有的房源详情链接,丢入容器,待会儿会依次进行爬取
List<String> urlList = html.css(".content__list--item--title a").links().all();
//将所有的房源详情链接添加到爬取任务队列
page.addTargetRequests(urlList);
//这里我们使用Xpath语法去命中我们想要的数据
//标题
String title = html.xpath("//div[@class='content clear w1150']/p/text()").toString();
page.putField("title", title);
//价格
page.putField("rent", html.xpath("//div[@class='content__aside--title']/span/text()").toString());
//租赁方式 、户型,如:2室1厅1卫 、朝向
page.putField("type", html.xpath("//ul[@class='content__aside__list']/allText()").toString());
//房源基本信息
page.putField("info", html.xpath("//div[@class='content__article__info']/allText()").toString());
//图片信息
page.putField("img", html.xpath("//div[@class='content__article__slide__item']/img").toString());
//做一个判断,在房源列表页title应该是为null,且根据分页规律,将更多要爬取的页面丢入到容器中
if (page.getResultItems().get("title") == null) {
page.setSkip(true);
//分页
for (int i = 1; i <= 100; i++) {
page.addTargetRequest("https://cd.lianjia.com/zufang/pg" + i);
}
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new LianjiaProcessor())
.addUrl("https://cd.lianjia.com/zufang/")
//启用五个线程
.thread(5)
.addPipeline(new MyPipeline())
.run();
}
}
XPath使用心得
刚刚我们在爬取的业务中说道了XPath,下面我们了解一下,我们就以Dmeo中爬取的title为列进行说明
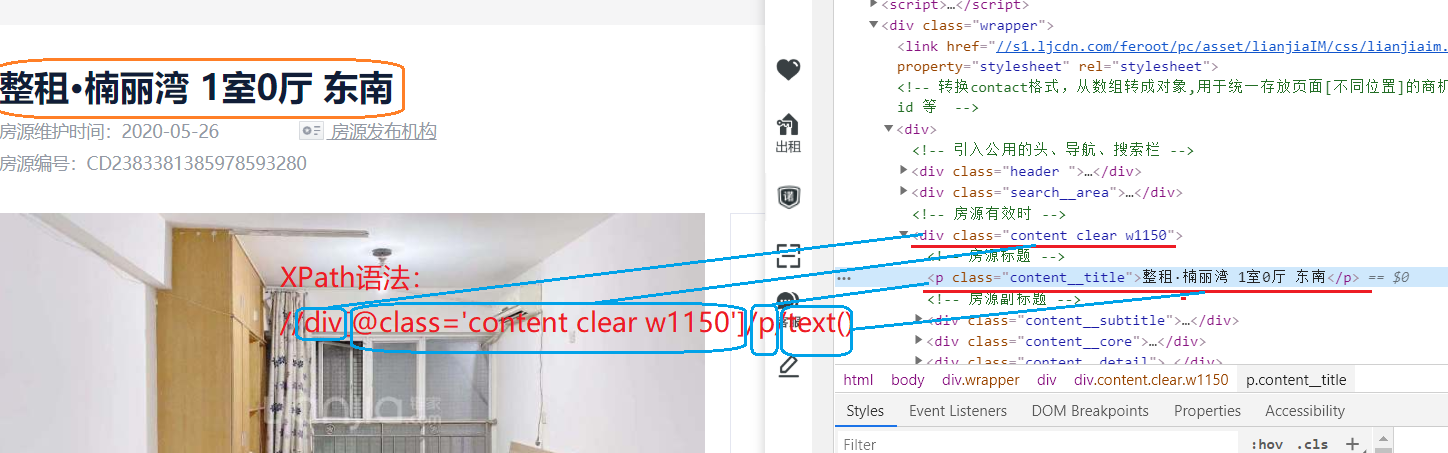
有时候一个选择器定位不到元素,可以通过 父-->子的嵌套关系进行选择,一般用class做选择,当命中的数据有多条是,可以使用allText()API,获得所有数据,反正边dubug边看嘛,哪个值取不到就看看这个选择器是否有问题
Scheduler
前面我们已经看到,我们将所有要爬取的路径抽离出来放到一个 容器中
//得到所有的房源详情链接
List<String> urlList = html.css(".content__list--item--title a").links().all();
//将所有的房源详情链接添加到爬取任务队列
page.addTargetRequests(urlList);
Scheduler是WebMagic中进行URL管理的组件。一般来说,Scheduler包括两个作用:
对待抓取的URL队列进行管理。
对已抓取的URL进行去重。
小规模的爬虫工程,无需定制这个组件,使用默认的即可,至于默认的,做了解内容(来自官方)
类 说明 备注 DuplicateRemovedScheduler 抽象基类,提供一些模板方法 继承它可以实现自己的功能 QueueScheduler 使用内存队列保存待抓取URL PriorityScheduler 使用带有优先级的内存队列保存待抓取URL 耗费内存较QueueScheduler更大,但是当设置了request.priority之后,只能使用PriorityScheduler才可使优先级生效 FileCacheQueueScheduler 使用文件保存抓取URL,可以在关闭程序并下次启动时,从之前抓取到的URL继续抓取 需指定路径,会建立.urls.txt和.cursor.txt两个文件 RedisScheduler 使用Redis保存抓取队列,可进行多台机器同时合作抓取 需要安装并启动redis
在0.5.1版本里,作者对Scheduler的内部实现进行了重构,去重部分被单独抽象成了一个接口:DuplicateRemover,从而可以为同一个Scheduler选择不同的去重方式,以适应不同的需要,目前提供了两种去重方式。
类 说明 HashSetDuplicateRemover 使用HashSet来进行去重,占用内存较大 BloomFilterDuplicateRemover 使用BloomFilter来进行去重,占用内存较小,但是可能漏抓页面
所有默认的Scheduler都使用HashSetDuplicateRemover来进行去重,(除开RedisScheduler是使用Redis的set进行去重)。如果你的URL较多,使用HashSetDuplicateRemover会比较占用内存,所以也可以尝试以下BloomFilterDuplicateRemover1,使用方式:
spider.setScheduler(new QueueScheduler()
.setDuplicateRemover(new BloomFilterDuplicateRemover(10000000)) //10000000是估计的页面数量
)
0.6.0版本后,如果使用BloomFilterDuplicateRemover,需要单独引入Guava依赖包
定制Pipeline
Pipeline其实就是将PageProcessor抽取的结果,继续进行了处理的部分,之前已经说过一个Spider可以定制多个Pipeline,如下所示就可以实现在控制台打印且执行自定义持久化处理
Spider.addPipeline(new ConsolePipeline()).addPipeline(new FilePipeline())
package com.example.webmagic.pipeline;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.IOUtils;
import org.apache.commons.lang3.StringUtils;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.HttpClientBuilder;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
import java.io.File;
import java.util.HashMap;
import java.util.Map;
public class MyPipeline implements Pipeline {
private static final ObjectMapper MAPPER = new ObjectMapper();
@Override
public void process(ResultItems resultItems, Task task) {
Map<String, Object> data = new HashMap<>();
data.put("url", resultItems.getRequest().getUrl());
data.put("title", resultItems.get("title"));//标题
data.put("rent", resultItems.get("rent"));//租金
String[] types = StringUtils.split(resultItems.get("type"), ' ');
data.put("rentMethod", types[0]);//租赁方式
data.put("houseType", types[1]);//户型,如:2室1厅1卫
data.put("orientation", types[2]);//朝向
String[] infos = StringUtils.split(resultItems.get("info"), ' ');
for (String info : infos) {
if (StringUtils.startsWith(info, "看房:")) {
//拿到看房信息
data.put("time", StringUtils.split(info, ':')[1]);
} else if (StringUtils.startsWith(info, "楼层:")) {
//拿到楼层信息
data.put("floor", StringUtils.split(info, ':')[1]);
}
}
String imageUrl = StringUtils.split(resultItems.get("img"), '"')[3];
//图片从命名
String newName = StringUtils
.substringBefore(StringUtils
.substringAfterLast(resultItems.getRequest().getUrl(),
"/"), ".") + ".jpg";
try {
this.downloadFile(imageUrl, new File("E:\\code\\images\\" + newName));
data.put("image", newName);
String json = MAPPER.writeValueAsString(data);
FileUtils.write(new File("E:\\code\\data.json"), json + "\n", "UTF-8",
true);
} catch (Exception e) {
e.printStackTrace();
}
}
//图片下载
public void downloadFile(String url, File dest) throws Exception {
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse response =
HttpClientBuilder.create().build().execute(httpGet);
try {
FileUtils.writeByteArrayToFile(dest,
IOUtils.toByteArray(response.getEntity().getContent()));
} finally {
response.close();
}
}
}
在上面我们的定制Pipeline中,我们将数据持久化到了Json文件,对应图片也保存到本地磁盘,如果是想持久化到第三方数据库,导入依赖进行持久化即可
Downloader
WebMagic的默认Downloader基于HttpClient。一般来说,你无须自己实现Downloader,当然这也是官方说明,不过HttpClientDownloader也预留了几个扩展点,以满足不同场景的需求。
你可能希望通过其他方式来实现页面下载,例如使用
SeleniumDownloader来渲染动态页面。
上面这种方式是爬取基本页面的方式,至于现在JS框架那么多,我们得想法子啊
爬取渲染页面待补充
...
在线暴躁:<script />问题的更多相关文章
- Bootstrap在线引用css和js
百度在线调用 <script src="http://libs.baidu.com/bootstrap/3.0.3/js/bootstrap.min.js"></ ...
- 一些js在线引用文档
1.jquery在线引用: <script src="https://code.jquery.com/jquery-3.1.1.min.js"></script& ...
- BootStrap jQuery 在线cdn
Bootstrap 3.3.0 js 文件 <script src="http://cdn.bootcss.com/bootstrap/3.3.0/js/bootstrap.min.j ...
- Javascript中关于cookie的那些事儿
Javascript-cookie 什么是cookie? 指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密).简单点来说就是:浏览器缓存. cookie由什 ...
- 读javascript高级程序设计17-在线检测,cookie,子cookie
一.在线状态检测 开发离线应用时,往往在离线状态时把数据存在本地,而在联机状态时再把数据发送到服务器.html5提供了检测在线状态的方法:navigator.onLine和online/offline ...
- 数据校验validator 与 DWZ
在做系统时经常会用到数据校验,数据校验可以自己写,也可以用现在成的,现在记录下两种类库使用方法, <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 ...
- Jquery 回到顶部
转:http://www.cnblogs.com/DemoLee/archive/2012/04/20/2459082.html 用jQuery实现渐隐渐显的返回顶部效果(附多图) 先来看几个图片 ...
- 数据验证validator 与 DWZ
在进行系统经常使用的数据验证.数据验证可以编写自己的,它也可以用来作为现在.现在,记录这两个库的使用, validator <!DOCTYPE HTML PUBLIC "-//W3C/ ...
- vue 基础-->进阶 教程(1): 基础(数据绑定)
第一章 建议学习时间4小时 课程共3章 前面的nodejs教程并没有停止更新,因为node项目需要用vue来实现界面部分,所以先插入一个vue教程,以免不会的同学不能很好的完成项目. 本教程,将从零 ...
随机推荐
- 爬虫(十二):图形验证码的识别、滑动验证码的识别(B站滑动验证码)
1. 验证码识别 随着爬虫的发展,越来越多的网站开始采用各种各样的措施来反爬虫,其中一个措施便是使用验证码.随着技术的发展,验证码也越来越花里胡哨的了.最开始就是几个数字随机组成的图像验证码,后来加入 ...
- 【学术篇】SPOJ GEN Text Generator AC自动机+矩阵快速幂
还有5天省选才开始点字符串这棵技能树是不是太晚了点... ~题目の传送门~ AC自动机不想讲了QAQ.其实很久以前是学过然后打过板子的, 但也仅限于打过板子了~ 之前莫名其妙学了一个指针版的但是好像不 ...
- laravel多字段模糊匹配
use App\Models\Resume; $resume = Resume::query(); $content = $request->input('content'); $resume ...
- RabbitMQ:从零开始
目录 一.介绍 二.安装 三.基本配置 四.Java Demo 五.基础API使用 六.ACK机制 七.消息的持久化 八.消息的公平分发 九.消息的优先级 十.消息的路由分发 十一.Spring集成 ...
- Ubuntu 图形桌面死机重启(机器不重启)
Ubuntu的图形界面容易死机,如果正在跑程序的话又不能重启.这时候可以通过终端来_重启_图形界面. 首先按Alt+Ctrl+F1进入终端界面.查看图形界面的进程: ps -t tty7 查看到名为X ...
- hbase-2.0.4集群部署
hbase-2.0.4集群部署 1. 集群节点规划: rzx1 HMaster,HRegionServer rzx2 HRegionServer rzx3 HRegionServer 前提:搭建好ha ...
- react-devtools超级简单安装教程
有时候看网上各路大神,写如何安装react-devtools,大神就是大神,好多步骤一笔带过,导致一些学习者看的一脸懵逼,今天我给大家讲超级简单的react-devtools安装步骤,相信看过的小伙伴 ...
- (转载)js引擎的执行过程(二)
概述 js引擎执行过程主要分为三个阶段,分别是语法分析,预编译和执行阶段,上篇文章我们介绍了语法分析和预编译阶段,那么我们先做个简单概括,如下: 语法分析: 分别对加载完成的代码块进行语法检验,语法正 ...
- docker核心技术(2)
鸟瞰容器生态系统 一谈到容器,大家都会想到 Docker. Docker 现在几乎是容器的代名词.确实,是 Docker 将容器技术发扬光大.同时,大家也需要知道围绕 Docker 还有一个生态系统. ...
- Neo4j原生语句cc
Cypher语句 Cypher语句是Neo4j的图查询语言.以下例子来自Neo4j Browser,启动后在命令栏输入:play cypher即可1. 创建一个节点: 语法:CREATE (node- ...