Python_selenium之获取当前页面的href属性,id属性,图片信息和截全屏
Python_selenium之获取当前页面的href属性,id属性,图片信息和截全屏
一、 获取当前页面的全部信息
1. 图片信息包括图片名称、图片大小等信息
2. 只需将图片信息打印出来(image.text image.size image.tag_name)
二、 获取页面元素的href属性(id同理)
1. 获取当前页面所有的链接信息(以百度首页为例)
2. 运用for循环,然后运用get_attribute(‘href’)
3. 然后将之打印出来即可
三、 截取全屏信息
1. 运用get_screenshot_file()进行截图即可
四、 测试脚本
1. 将以上三种代码写在一起,如下所示:
#coding:utf-8
from selenium import webdriver
import time
driver=webdriver.Firefox()
driver.maximize_window()
driver.implicitly_wait(8)
driver.get("https://www.baidu.com/")
for image in driver.find_elements_by_tag_name("img"):#获取当前页面的图片信息
print image.text
print image.size
print image.tag_name
print "================================"
time.sleep(2)
for link in driver.find_elements_by_xpath("//*[@href]"):#获取当前页面的href
print link.get_attribute('href')
print "================================"
for id in driver.find_elements_by_xpath("//*[@id]"):#获取当前页面的id
print id.get_attribute('id')
print "================================"
driver.get_screenshot_as_file("E:\\work_study\\One.png")#截取当前页面的图片(全屏)。括号里面的路径为保存到本地电脑上面的路径,可随意设置。
driver.quit()
五、 测试结果
1. 如下图所示:
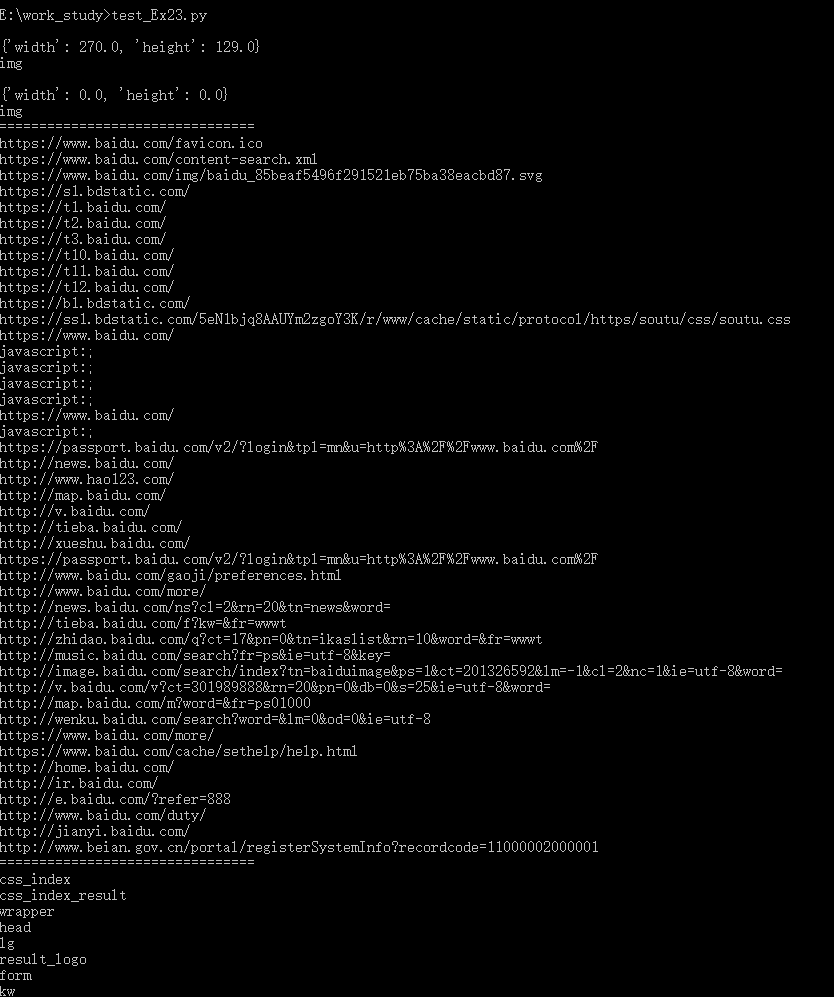
Python_selenium之获取当前页面的href属性,id属性,图片信息和截全屏的更多相关文章
- js获取当前页面的url中id
function UrlSearch() { var name, value; var str = location.href; //获取到整个地址 var num = str.indexOf(&qu ...
- js获取当前页面的url网址信息小汇总
在WEB开发中,时常会用到javascript来获取当前页面的url网址信息,在这里是我的一些获取url信息的小总结. 下面我们举例一个URL,然后获得它的各个组成部分:http://i.cnblog ...
- ASP.net获取当前页面的文件名,参数,域名等方法
ASP.net后台获取当前页面的文件名 System.IO.Path.GetFileName(Request.Path).ToString(); 获取当前页面文件名,参数,域名等方法 假设当前页完整地 ...
- 转载: js jquery 获取当前页面的url,获取frameset中指定的页面的url(有修改)
转载网址:http://blog.csdn.net/bestlxm/article/details/6800077 js jquery 怎么获取当前页面的url,获取frameset中指定的页面的ur ...
- 获取当前页面的URL信息
以前在做网站的时候,经常会遇到当前页的分类高亮显示,以便让用户了解当前处于哪个页面.之前一直是在每个不同页面写方法.工程量大,也不便于修改.一直在想有什么简便的方法实现.后来在网上查到可以用获取当前U ...
- C#获取当前页面的url
C#获取当前页面的url string a= Request.ApplicationPath; // / string b = Request.CurrentExecutionFilePath; // ...
- PHP中$_SERVER获取当前页面的完整URL地址
PHP中$_SERVER获取当前页面的完整URL地址,其实很简单,主要是通过$_SERVER超全局变量来实现的. 具体PHP中$_SERVER获取当前页面的完整URL地址如下. #测试网址: ...
- js获取当前页面的URL并且截取?之后的数据,返回json
js获取当前页面的URL并且截取'?'之后的数据,返回json格式的数据 最近想要把学到的东西整理一下,以后方便查找,也是一种自我累积,如果有错误或者更好的,欢迎提出! 这篇文档主要是写关于获取页面的 ...
- react获取当前页面的url参数
react获取当前页面的url参数,必须在url路由对应的组件上获取,在子组件上获取不到,为undefined,获取形如 /news/:id 的后面的参数 id this.props.match. ...
随机推荐
- [Exception Spring 1] - Attribute value must not be null
java.lang.IllegalArgumentException: Attribute value must not be null at org.springframework.util.Ass ...
- 利用Redis撤销JSON Web Token产生的令牌
利用Redis撤销JSON Web Token产生的令牌 作者:chszs.版权全部.未经允许,不得转载.博主主页:http://blog.csdn.net/chszs 早先的博文讨论了在Angula ...
- Javascript 中使用Json的四种途径
1.jQuery插件支持的转换方式: 复制代码代码如下: $.parseJSON( jsonstr ); //jQuery.parseJSON(jsonstr),可以将json字符串转换成json对象 ...
- php_memcahed telnet远程操作方法
一.存储命令 存储命令的格式: <command name> <key> <flags> <exptime> <bytes> <dat ...
- linux释放内存命令
1.首先查看linux内存使用 #free -m 2.把内存数据同步到硬盘#sync 3.修改 /proc/sys/vm/drop_caches文件 #echo 3 > /proc/sys/vm ...
- Impala中多列转为一行
之前有一位朋友咨询我,Impala中怎样实现将多列转为一行,事实上Impala中自带函数能够实现,不用自己定义函数. 以下我開始演示: -bash-4.1$ impala-shell Starting ...
- 利用dd命令制作u盘iso镜像
现在安装系统都是用u盘安装,那么制作u盘的iso镜像就是必须的了.现在此类工具倒是不少,但是,好用的不多,有的还收费.唉,还是用dd吧,老配方,老味道. 首先:要df -h一下,看看u盘的盘符,类似 ...
- linux 查看可执行文件动态链接库相关信息(转)
转自 http://blog.sina.com.cn/s/blog_67eb1f2f0100mgd8.html ldd <可执行文件名> 查看可执行文件链接了哪些 系统动态链 ...
- matplotlib之极坐标系的极角网格线(thetagrids)的显示刻度
极坐标系的极角网格线(thetagrids)的显示刻度 #!/usr/bin/env python3 #-*- coding:utf-8 -*- ########################### ...
- Macbook小问题
Macbook小问题 有时候 AppStore 和 Safari,QQ等 无法上网,但 chrome 却是正常的.解决办法:终端输入如下命令,其实是在 kill 掉网卡进程. sudo killall ...