(Python爬虫04)了解通用爬虫和聚焦爬虫,还是理论知识.快速入门可以略过的
如果现在的你返回N年前去重新学习一门技能,你会咋做? 我会这么干: ...哦,原来这个本事学完可以成为恋爱大神啊, 我要掌握精髓需要这么几个要点一二三四..... 具体的学习步骤是这样的一二三.... 最后肯定比周围的小弟弟妹妹们牛逼,因为高度不一样啊! *理论现行,脑袋决定高度! 如果初学者可以略过直接使用,以后熟悉了再回来看! 我得当大神...
重点在这里: 了解 通用爬虫 和 聚焦爬虫
根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种
通用爬虫:
搜索引擎用的爬虫系统通用搜索引擎(Search Engine)工作原理
:
通用网络爬虫 是 捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
就是尽可能的吧互联网上的网页下载下来,放在本地服务器里形成备份,在对这些网页做相关处理,(提取关键字,去掉广告),最后提供一个用户检索接口!

第一步: 抓取网页:
- 首选选取一部分已有的URL,把这些URL放到待爬取队列。
- 从队列里取出这些URL,然后解析DNS得到主机IP,然后去这个IP对应的服务器里下载HTML页面,保存到搜索引擎的本地服务器。之后把这个爬过的URL放入已爬取队列。
- 分析这些网页内容,找出网页里其他的URL连接,继续执行第二步,直到爬取条件结束。
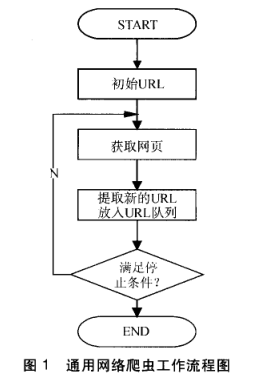
搜索引擎如何获取一个新的网站的URL地址?
- 主动向搜索引擎提交网址: 百度链接提交
- 在其他网站里设置网站的外链。
- 搜索引擎会和DNS服务商进行合作,可以快速收录新的网站。
DNS: 就是把域名解析成IP地址的一种技术! DNS域名解析如果感兴趣我可以写一篇文章专门介绍! 老菜鸟可能会不屑一看.....
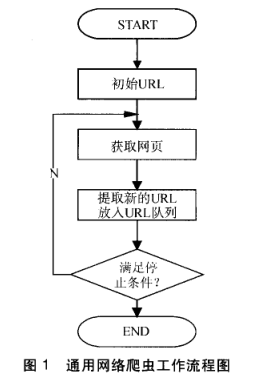
通用爬虫并不是万物皆可爬,它也需要遵守规则:
Robots协议:协议会指明通用爬虫可以爬取网页的权限。Robots.txt 只是一个建议。并不是所有爬虫都遵守,一般只有大型的搜索引擎爬虫才会遵守。 咱们个人写的爬虫,就不管了。
Robots协议(也叫爬虫协议、机器人协议等),全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,例如:
淘宝网:https://www.taobao.com/robots.txt
腾讯网: http://www.qq.com/robots.txt
第二步: 数据存储
搜索引擎通过爬虫爬取到的网页,将数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML是完全一样的。
搜索引擎蜘蛛在抓取页面时,也做一定的重复内容检测,一旦遇到访问权重很低的网站上有大量抄袭、采集或者复制的内容,很可能就不再爬行。
第三步: 预处理
搜索引擎将爬虫抓取回来的页面,进行各种步骤的预处理。
提取文字
中文分词
消除噪音(比如版权声明文字、导航条、广告等……)
索引处理
链接关系计算
特殊文件处理
....
除了HTML文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们在搜索结果中也经常会看到这些文件类型。
但搜索引擎还不能处理图片、视频、Flash 这类非文字内容,也不能执行脚本和程序。
第四步: 提供检索服务,网站排名
搜索引擎排名:
PageRank值:根据网站的流量(点击量/浏览量/人气)统计,流量越高,网站也越值钱,排名越靠前。- 竞价排名:谁给钱多,谁排名就高。
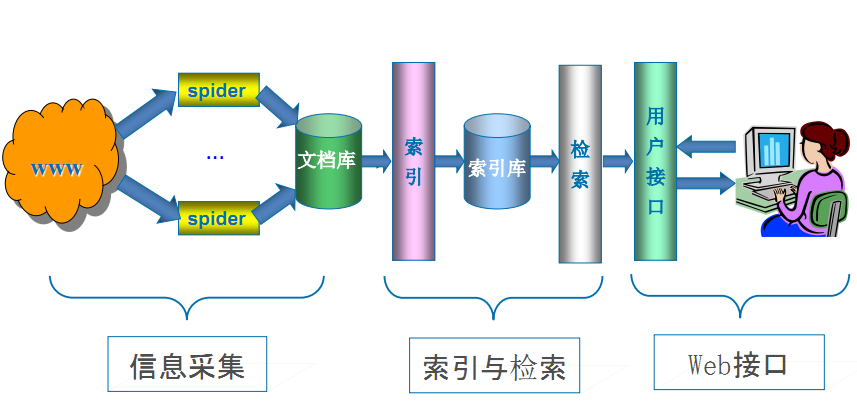
搜索引擎在对信息进行组织和处理后,为用户提供关键字检索服务,将用户检索相关的信息展示给用户。
同时会根据页面的PageRank值(链接的访问量排名)来进行网站排名,这样Rank值高的网站在搜索结果中会排名较前,当然也可以直接使用 Money 购买搜索引擎网站排名,简单粗暴。
通用爬虫的缺点:
- 只能提供和文本相关的内容(HTML、Word、PDF)等等,但是不能提供多媒体文件(音乐、图片、视频)和二进制文件(程序、脚本)等等。
- 通用搜索引擎所返回的结果都是网页,而大多情况下,网页里90%的内容对用户来说都是无用的
- 不能针对不同背景领域的人提供不同的搜索结果。
- 不能理解人类语义上的检索。通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询,无法准确理解用户的具体需求。
为了解决这个问题,聚焦爬虫出现了:
聚焦爬虫
聚焦爬虫: 爬虫程序员写的针对某种内容的爬虫。
面向主题爬虫,面向需求爬虫:会针对某种特定的内容去爬取信息,而且会保证信息和需求尽可能相关。
我们程序员要学习的,就是聚焦爬虫
(Python爬虫04)了解通用爬虫和聚焦爬虫,还是理论知识.快速入门可以略过的的更多相关文章
- Python通用爬虫,聚焦爬虫概念理解
通用爬虫:百度.360.搜狐.谷歌.必应....... 原理: (1)抓取网页 (2)采集数据 (3)数据处理 (4)提供检索服务 百度爬虫:Baiduspider 通用爬虫如何抓取新网站? (1)主 ...
- 070.Python聚焦爬虫数据解析
一 聚焦爬虫数据解析 1.1 基本介绍 聚焦爬虫的编码流程 指定url 基于requests模块发起请求 获取响应对象中的数据 数据解析 进行持久化存储 如何实现数据解析 三种数据解析方式 正则表达式 ...
- Spider-Python爬虫之聚焦爬虫与通用爬虫的区别
为什么要学习爬虫? 学习爬虫,可以私人订制一个搜索引擎. 大数据时代,要进行数据分析,首先要有数据源. 对于很多SEO从业者来说,从而可以更好地进行搜索引擎优化. 什么是网络爬虫? 模拟客户端发送网络 ...
- python高级—— 从趟过的坑中聊聊爬虫、反爬以及、反反爬,附送一套高级爬虫试题
前言: 时隔数月,我终于又更新博客了,然而,在这期间的粉丝数也就跟着我停更博客而涨停了,唉 是的,我改了博客名,不知道为什么要改,就感觉现在这个名字看起来要洋气一点. 那么最近到底咋不更新博客了呢?说 ...
- Python爬虫合集:花6k学习爬虫,终于知道爬虫能干嘛了
爬虫Ⅰ:爬虫的基础知识 爬虫的基础知识使用实例.应用技巧.基本知识点总结和需要注意事项 爬虫初始: 爬虫: + Request + Scrapy 数据分析+机器学习 + numpy,pandas,ma ...
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- 5个python爬虫教材,让小白也有爬虫可写,含视频教程!
认识爬虫 网络爬虫,如果互联网是一张蜘蛛网,网络爬虫既是一个在此网上爬行的蜘蛛,爬了多少路程即获取到多少数据. python写爬虫的优势 其实以上功能很多语言和工具都能做,但是用python爬 ...
- 【网络爬虫】【python】网络爬虫(二):网易微博爬虫软件开发实例(附软件源码)
对于urllib2的学习,这里先推荐一个教程<IronPython In Action>,上面有很多简明例子,并且也有很详尽的原理解释:http://www.voidspace.org.u ...
- 小白学 Python 爬虫(4):前置准备(三)Docker基础入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- 大数据框架-YARN
YARN(Yet Another Resource Negotiator): 是一种新的 Hadoop 资源管理器 [ResourceManager:纯粹的调度器,基于应用程序对资源的需求进行调度的, ...
- 一点一点看JDK源码(五)java.util.ArrayList 后篇之sort与Comparator
一点一点看JDK源码(五)java.util.ArrayList 后篇之sort与Comparator liuyuhang原创,未经允许禁止转载 本文举例使用的是JDK8的API 目录:一点一点看JD ...
- Knowledge Point 20180308 Dead Code
不知道有没有前辈注意过,当你编写一段“废话式的代码时”会给出一个Dead Code警告,点击警告,那么你所写的废物代码会被编译器消除,那么如果你不理睬这个警告呢?编译后会是什么样的呢?下面我们写点代码 ...
- 关于chrome浏览器不能更新js的问题
今天写程序时,突然发现无论我怎么改本地js,用chrome打开时,均是改动之前的效果,F12查看Sources时发现js文件并没有被改动.由此引发的问题,经查询解决方法如下: F12后按F1,出现Se ...
- angularjs脏机制
Angular 每一个绑定到UI的数据,就会有一个 $watch 对象. watch = { name:'', //当前的watch 对象 观测的数据名 getNewValue:function($s ...
- java端连接zookeeper出现unknowHostException错误
连接zookeeper出现异常:unknowHostException 出现这种错误一开始以为是zookeeper的配置文件出了问题,所以一直在找配置文件的问题,但是zookeeper在虚拟机里面是可 ...
- django模板的变量,标签,过滤器和自定义过滤器,注释
模板的作用是计算并输出: {{ 变量}} 当模版引擎遇到点如book.title,会按照下列顺序解析: 1.字典book['title'] 2.先属性后方法,将book当作对象,查找属性title,如 ...
- Python学习 :迭代器&生成器
列表生成式 列表生成式的操作顺序: 1.先依次来读取元素 for x 2.对元素进行操作 x*x 3.赋予变量 Eg.列表生成式方式一 a = [x*x for x in range(10)] pri ...
- 『Python题库 - 简答题』 Python中的基本概念 (121道)
## 『Python题库 - 简答题』 Python中的基本概念 1. Python和Java.PHP.C.C#.C++等其他语言的对比? 2. 简述解释型和编译型编程语言? 3. 代码中要修改不可变 ...
- 中国大学MOOC-C程序设计(浙大翁恺)—— 单词长度
题目内容: 你的程序要读入一行文本,其中以空格分隔为若干个单词,以‘.’结束.你要输出这行文本中每个单词的长度.这里的单词与语言无关,可以包括各种符号,比如“it's”算一个单词,长度为4.注意,行中 ...