Hadoop项目实战
这个项目是流量经营项目,通过Hadoop的离线数据项目。
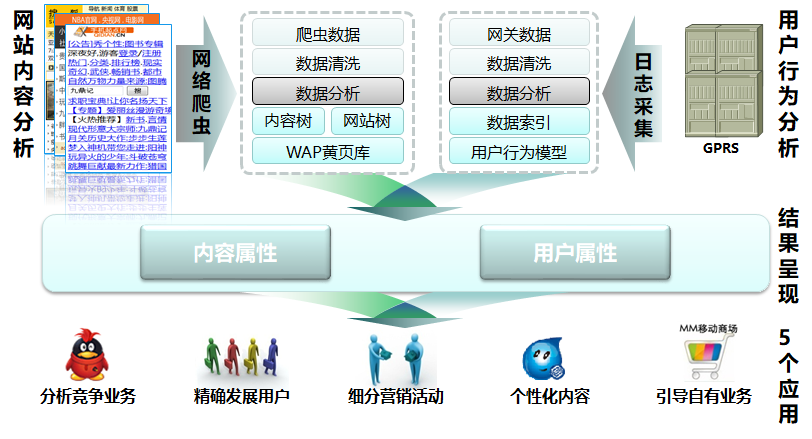
运营商通过HTTP日志,分析用户的上网行为数据,进行行为轨迹的增强。
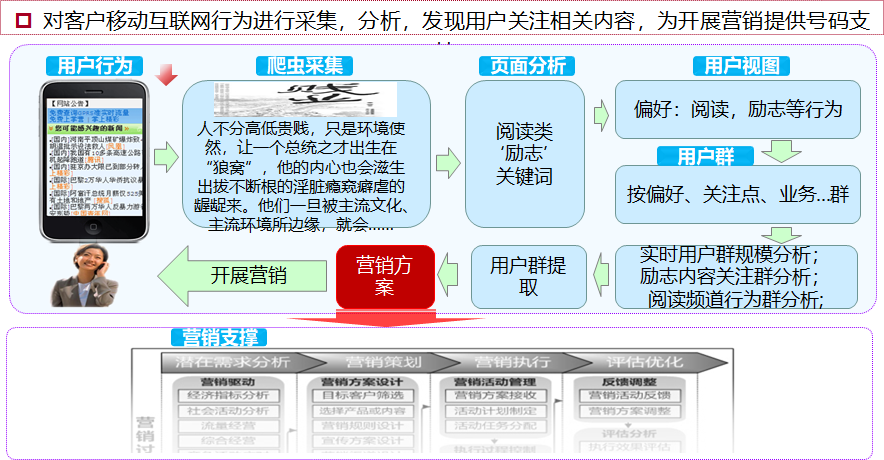
HTTP数据格式为:

流程:


系统架构:
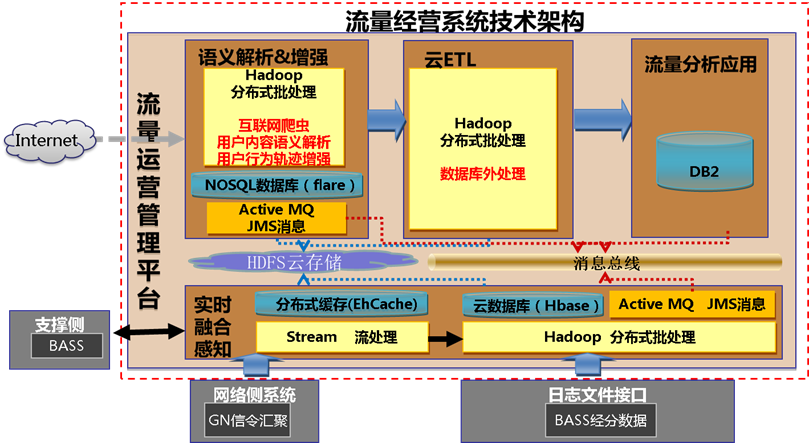
技术选型:

这里只针对其中的一个功能进行说明:
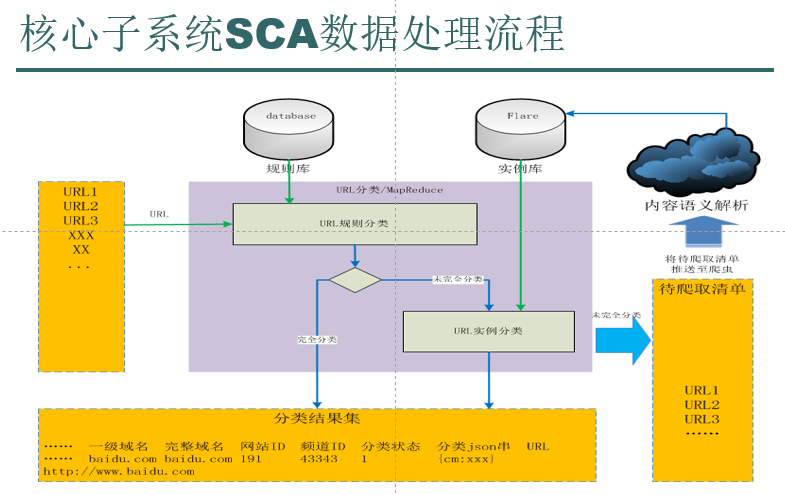
其中规则库是人工填充的,实例库是采用机器学习自动生成的,形式都是<url,info>。
(一)统计流量排名前80%的URL,只有少数的URL流量比特别高,绝大多数的URL流量极低,没有参考价值,应当舍弃。
FlowBean.java:
package cn.itcast.hadoop.mr.flowsum; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable; public class FlowBean implements WritableComparable<FlowBean>{ private String phoneNB;
private long up_flow;
private long d_flow;
private long s_flow; //在反序列化时,反射机制需要调用空参构造函数,所以显示定义了一个空参构造函数
public FlowBean(){} //为了对象数据的初始化方便,加入一个带参的构造函数
public FlowBean(String phoneNB, long up_flow, long d_flow) {
this.phoneNB = phoneNB;
this.up_flow = up_flow;
this.d_flow = d_flow;
this.s_flow = up_flow + d_flow;
} public void set(String phoneNB, long up_flow, long d_flow) {
this.phoneNB = phoneNB;
this.up_flow = up_flow;
this.d_flow = d_flow;
this.s_flow = up_flow + d_flow;
} public String getPhoneNB() {
return phoneNB;
} public void setPhoneNB(String phoneNB) {
this.phoneNB = phoneNB;
} public long getUp_flow() {
return up_flow;
} public void setUp_flow(long up_flow) {
this.up_flow = up_flow;
} public long getD_flow() {
return d_flow;
} public void setD_flow(long d_flow) {
this.d_flow = d_flow;
} public long getS_flow() {
return s_flow;
} public void setS_flow(long s_flow) {
this.s_flow = s_flow;
} //将对象数据序列化到流中
@Override
public void write(DataOutput out) throws IOException { out.writeUTF(phoneNB);
out.writeLong(up_flow);
out.writeLong(d_flow);
out.writeLong(s_flow); } //从数据流中反序列出对象的数据
//从数据流中读出对象字段时,必须跟序列化时的顺序保持一致
@Override
public void readFields(DataInput in) throws IOException { phoneNB = in.readUTF();
up_flow = in.readLong();
d_flow = in.readLong();
s_flow = in.readLong(); } @Override
public String toString() { return "" + up_flow + "\t" +d_flow + "\t" + s_flow;
} @Override
public int compareTo(FlowBean o) {
return s_flow>o.getS_flow()?-1:1;
} }
TopkURLMapper.java:
package cn.itcast.hadoop.mr.llyy.topkurl; import java.io.IOException; import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import cn.itcast.hadoop.mr.flowsum.FlowBean; public class TopkURLMapper extends Mapper<LongWritable, Text, Text, FlowBean> { private FlowBean bean = new FlowBean();
private Text k = new Text(); @Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException { String line = value.toString(); String[] fields = StringUtils.split(line, "\t");
try {
if (fields.length > 32 && StringUtils.isNotEmpty(fields[26])
&& fields[26].startsWith("http")) {
String url = fields[26]; long up_flow = Long.parseLong(fields[30]);
long d_flow = Long.parseLong(fields[31]); k.set(url);
bean.set("", up_flow, d_flow); context.write(k, bean);
}
} catch (Exception e) { System.out.println(); }
} }
TopkURLReducer.java:
package cn.itcast.hadoop.mr.llyy.topkurl; import java.io.IOException;
import java.util.Map.Entry;
import java.util.Set;
import java.util.TreeMap; import org.apache.hadoop.hdfs.server.namenode.HostFileManager.EntrySet;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import cn.itcast.hadoop.mr.flowsum.FlowBean; public class TopkURLReducer extends Reducer<Text, FlowBean, Text, LongWritable>{
private TreeMap<FlowBean,Text> treeMap = new TreeMap<>();
private double globalCount = 0; // <url,{bean,bean,bean,.......}>
@Override
protected void reduce(Text key, Iterable<FlowBean> values,Context context)
throws IOException, InterruptedException {
Text url = new Text(key.toString());
long up_sum = 0;
long d_sum = 0;
for(FlowBean bean : values){ up_sum += bean.getUp_flow();
d_sum += bean.getD_flow();
} FlowBean bean = new FlowBean("", up_sum, d_sum);
//每求得一条url的总流量,就累加到全局流量计数器中,等所有的记录处理完成后,globalCount中的值就是全局的流量总和
globalCount += bean.getS_flow();
treeMap.put(bean,url); } //cleanup方法是在reduer任务即将退出时被调用一次
@Override
protected void cleanup(Context context)
throws IOException, InterruptedException { Set<Entry<FlowBean, Text>> entrySet = treeMap.entrySet();
double tempCount = 0; for(Entry<FlowBean, Text> ent: entrySet){ if(tempCount / globalCount < 0.8){ context.write(ent.getValue(), new LongWritable(ent.getKey().getS_flow()));
tempCount += ent.getKey().getS_flow(); }else{
return;
} } } }
TopkURLRunner.java:
package cn.itcast.hadoop.mr.llyy.topkurl; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; import cn.itcast.hadoop.mr.flowsum.FlowBean; public class TopkURLRunner extends Configured implements Tool{ @Override
public int run(String[] args) throws Exception { Configuration conf = new Configuration();
Job job = Job.getInstance(conf); job.setJarByClass(TopkURLRunner.class); job.setMapperClass(TopkURLMapper.class);
job.setReducerClass(TopkURLReducer.class); job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); return job.waitForCompletion(true)?0:1;
} public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new TopkURLRunner(), args);
System.exit(res); } }
(二)将统计的URL导入到数据库中,这是URL规则库,一共就两个字段,URL和info说明,info是人工来实现,贴上标签。
将上面的运行结果通过sqoop导入到数据库中,然后通过数据库读取再跑mapreduce程序。
DBLoader.java:数据库的工具类。
package cn.itcast.hadoop.mr.llyy.enhance;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.HashMap; public class DBLoader { public static void dbLoader(HashMap<String, String> ruleMap) { Connection conn = null;
Statement st = null;
ResultSet res = null; try {
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection("jdbc:mysql://weekend01:3306/urlcontentanalyse", "root", "root");
st = conn.createStatement();
res = st.executeQuery("select url,info from urlrule");
while (res.next()) {
ruleMap.put(res.getString(1), res.getString(2));
} } catch (Exception e) {
e.printStackTrace(); } finally {
try{
if(res!=null){
res.close();
}
if(st!=null){
st.close();
}
if(conn!=null){
conn.close();
} }catch(Exception e){
e.printStackTrace();
}
} } public static void main(String[] args) {
DBLoader db = new DBLoader();
HashMap<String, String> map = new HashMap<String,String>();
db.dbLoader(map);
System.out.println(map.size());
} }
LogEnhanceOutputFormat.java:默认是TextOutputFormat,这里我需要实现将不同的结果输到不同的文件中,而不是_SUCCESS中,所以我需要重写一个format。
package cn.itcast.hadoop.mr.llyy.enhance; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class LogEnhanceOutputFormat<K, V> extends FileOutputFormat<K, V> { @Override
public RecordWriter<K, V> getRecordWriter(TaskAttemptContext job)
throws IOException, InterruptedException { FileSystem fs = FileSystem.get(new Configuration());
FSDataOutputStream enhancedOs = fs.create(new Path("/liuliang/output/enhancedLog"));
FSDataOutputStream tocrawlOs = fs.create(new Path("/liuliang/output/tocrawl")); return new LogEnhanceRecordWriter<K, V>(enhancedOs,tocrawlOs);
} public static class LogEnhanceRecordWriter<K, V> extends RecordWriter<K, V>{
private FSDataOutputStream enhancedOs =null;
private FSDataOutputStream tocrawlOs =null; public LogEnhanceRecordWriter(FSDataOutputStream enhancedOs,FSDataOutputStream tocrawlOs){ this.enhancedOs = enhancedOs;
this.tocrawlOs = tocrawlOs; } @Override
public void write(K key, V value) throws IOException,
InterruptedException { if(key.toString().contains("tocrawl")){
tocrawlOs.write(key.toString().getBytes());
}else{
enhancedOs.write(key.toString().getBytes());
} } @Override
public void close(TaskAttemptContext context) throws IOException,
InterruptedException { if(enhancedOs != null){
enhancedOs.close();
}
if(tocrawlOs != null){
tocrawlOs.close();
} } } }
然后再从所有原始日志中抽取URL,查询规则库,如果由info标签,则追加在原始日志后面。否则,这个URL就是带爬取URL,后面追加tocrawl,这两种不同情况要输出到不同文件中。
LogEnhanceMapper.java:
package cn.itcast.hadoop.mr.llyy.enhance; import java.io.IOException;
import java.util.HashMap; import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; /**
*
*
* 读入原始日志数据,抽取其中的url,查询规则库,获得该url指向的网页内容的分析结果,追加到原始日志后
*
* @author duanhaitao@itcast.cn
*
*/ // 读入原始数据 (47个字段) 时间戳 ..... destip srcip ... url .. . get 200 ...
// 抽取其中的url查询规则库得到众多的内容识别信息 网站类别,频道类别,主题词,关键词,影片名,主演,导演。。。。
// 将分析结果追加到原始日志后面
// context.write( 时间戳 ..... destip srcip ... url .. . get 200 ...
// 网站类别,频道类别,主题词,关键词,影片名,主演,导演。。。。)
// 如果某条url在规则库中查不到结果,则输出到带爬清单
// context.write( url tocrawl)
public class LogEnhanceMapper extends
Mapper<LongWritable, Text, Text, NullWritable> { private HashMap<String, String> ruleMap = new HashMap<>(); // setup方法是在mapper task 初始化时被调用一次
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
DBLoader.dbLoader(ruleMap);
} @Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException { String line = value.toString(); String[] fields = StringUtils.split(line, "\t");
try {
if (fields.length > 27 && StringUtils.isNotEmpty(fields[26])
&& fields[26].startsWith("http")) {
String url = fields[26];
String info = ruleMap.get(url);
String result = "";
if (info != null) {
result = line + "\t" + info + "\n\r";
context.write(new Text(result), NullWritable.get());
} else {
result = url + "\t" + "tocrawl" + "\n\r";
context.write(new Text(result), NullWritable.get());
} } else {
return;
}
} catch (Exception e) {
System.out.println("exception occured in mapper.....");
}
} }
LogEnhanceRunner.java:
package cn.itcast.hadoop.mr.llyy.enhance; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class LogEnhanceRunner extends Configured implements Tool{ @Override
public int run(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(LogEnhanceRunner.class); job.setMapperClass(LogEnhanceMapper.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class); job.setOutputFormatClass(LogEnhanceOutputFormat.class); FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); return job.waitForCompletion(true)?0:1;
} public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new LogEnhanceRunner(),args);
System.exit(res);
} }
这里不写reduce也行。
MapReduce实现Top K问题:https://blog.csdn.net/u011750989/article/details/11482805?locationNum=5
Hadoop项目实战的更多相关文章
- Hadoop项目实战-用户行为分析之应用概述(三)
1.概述 本课程的视频教程地址:<项目工程准备> 本节给大家分享的主题如下图所示: 下面我开始为大家分享今天的第三节的内容——<项目工程准备>,接下来开始分享今天的内容. 2. ...
- Hadoop项目实战-用户行为分析之应用概述(二)
1.概述 本课程的视频教程地址:<项目整体概述> 本节给大家分享的主题如下图所示: 下面我开始为大家分享第二节的内容——<项目整体概述>,下面开始今天的分享内容. 2.内容 从 ...
- Hadoop项目实战-用户行为分析之应用概述(一)
1.概述 本课程的视频教程地址:<Hadoop 回顾> 好的,下面就开始本篇教程的内容分享,本篇教程我为大家介绍我们要做一个什么样的Hadoop项目,并且对Hadoop项目的基本特点和其中 ...
- Hadoop项目实战-用户行为分析之编码实践
1.概述 本课程的视频教程地址:<用户行为分析之编码实践> 本课程以用户行为分析案例为基础,带着大家去完成对各个KPI的编码工作,以及应用调度工作,让大家通过本课程掌握Hadoop项目的编 ...
- Hadoop项目实战-用户行为分析之分析与设计
1.概述 本课程的视频教程地址:<用户行为分析之分析与设计> 下面开始本教程的学习,本教程以用户行为分析案例为基础,带着大家对项目的各个指标做详细的分析,对项目的整体设计做合理的规划,让大 ...
- hadoop项目实战--ETL--(二)实现自动向mysql中添加数据
四 项目开发 1 创建数据库db_etl,新建两张表user 和oder.表结构如第一部分图所示. 2 编写python脚本,实现自动向mysql中插入数据. 新建python 项目,目录结构如下图 ...
- hadoop项目实战--ETL--(一)项目分析
项目描述 一 项目简介 在远程服务器上的数据库中有两张表,user 和order,现需要对表中的数据做分析,将分析后的结果再存到mysql中.两张表的结构如下图所示 现需要分析每一天user和,ode ...
- hadoop项目实战--ETL--(三)实现mysql表到HIVE表的全量导入与增量导入
一 在HIVE中创建ETL数据库 ->create database etl; 二 在工程目录下新建MysqlToHive.py 和conf文件夹 在conf文件夹下新建如下文件,最后的工程目录 ...
- 深入浅出Hadoop Mahout数据挖掘实战(算法分析、项目实战、中文分词技术)
Mahout简介 Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目, 提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建 ...
随机推荐
- Python程序员技能表—446家知名企业的Py招聘信息(转载)
Python程序员技能表—446家知名企业的Py招聘信息 转载: python 正在学习python或者想学习python的可以加群:330637182 正在学习python或者想学习python的可 ...
- [Angular] Extract Implementation Details of ngrx from an Angular Application with the Facade Pattern
Extracting away the implementation details of ngrx from your components using the facade pattern cre ...
- CUDA编程札记
const int N = 33 * 1024; const int threadsPerBlock = 256; const int blocksPerGrid = imin( 32, (N+thr ...
- ASP.NET MVC & Web API Brief Introduction
Pure Web Service(ASMX): Starting back in 2002 with the original release of .NET, a developer could f ...
- 建站笔记1:centos6.5下安装mysql
近期买了个域名,想要玩玩自己建站点:接下来遇到的问题都会一次记录下来.以备自己以后复习查看: 首先建站方案选择: wordPress +centos6.5 +mysql; server买的:搬瓦工最低 ...
- 使用VisualSVN建立SVN服务器
原地址:http://blog.csdn.net/happyjiang2009/article/details/5719988 以前使用官方Subversion搭建SVN版本控制环境,感觉很繁琐,需要 ...
- Android 底部TabActivity(1)——FragmentActivity
先看看效果图: 第一篇Tab系列的文章首先实现这样的风格的底部Tab:背景条颜色不变,我们是用了深灰的颜色,图标会发生对应的变化.当选中某个标签后该标签的背板会由正常的颜色变为不正常,哈哈,是变为加深 ...
- Java之内部类(1) - 为什么需要内部类
为什么需要内部类 一般来说,内部类继承自某个类或实现某个接口,内部类的代码操作创建它的外围类的对象.所以可以认为内部类提供了某种进入其外围类的窗口. 内部类必须要回答的一个问题是:如果只是需要一个对接 ...
- 为Drupal7.22添加富编辑器 on Ubuntu 12.04
怀揣着为中小企业量身定做一整套开源软件解决方案的梦想开始了一个网站的搭建.http://osssme.org/ 基本上就是按照Drupal7宝典里描述的进行设置的. 1. 下载wysiwyg 2. ...
- springmvc 数据回显功能
按下 修改数据之后 修改功能实现-转向修改页面 2)控制层实现准备数据,并转向修改页面 ~ PersonController.java package cn.itcast.springmvc.cont ...