02-爬取http://www.allitebooks.org/网站,获取图片url,书名,简介,作者
import requests
from lxml import etree
from bs4 import BeautifulSoup
import json class BookSpider(object):
def __init__(self):
self.base_url = 'http://www.allitebooks.com/page/{}'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'} self.data_list = [] # 1.构建所有url
def get_url_list(self):
url_list = []
for i in range(1, 10): # 此处爬取的页数按需要确定
url = self.base_url.format(i)
url_list.append(url)
return url_list # 2.发请求
def send_request(self, url):
data = requests.get(url, headers=self.headers).content.decode()
return data # 3.解析数据 xpath
def parse_xpath_data(self, data):
parse_data = etree.HTML(data) # 1.解析出所有的书 book
book_list = parse_data.xpath('//div[@class="main-content-inner clearfix"]/article') # 2.解析出 每本书的 信息
for book in book_list:
book_dict = {}
# 1.书名字
book_dict['book_name'] = book.xpath('.//h2[@class="entry-title"]//text()')[0] # 2.书的图片url
book_dict['book_img_url'] = book.xpath('div[@class="entry-thumbnail hover-thumb"]/a/img/@src')[0] # 3.书的作者
book_dict['book_author'] = book.xpath('.//h5[@class="entry-author"]//text()')[0] # 4.书的简介
book_dict['book_info'] = book.xpath('.//div[@class="entry-summary"]/p/text()')[0] self.data_list.append(book_dict) def parse_bs4_data(self, data): bs4_data = BeautifulSoup(data, 'lxml')
# 1.取出所有的书
book_list = bs4_data.select('article') # 2.解析出 每本书的 信息
for book in book_list:
book_dict = {}
# 1.书名字
book_dict['book_name'] = book.select_one('.entry-title').get_text() # # 2.书的图片url
book_dict['book_img_url'] = book.select_one('.attachment-post-thumbnail').get('src') # # 3.书的作者
book_dict['book_author'] = book.select_one('.entry-author').get_text()[3:]
#
# # 4.书的简介
book_dict['book_info'] = book.select_one('.entry-summary p').get_text()
print(book_dict)
self.data_list.append(book_dict) # 4.保存数据
def save_data(self):
json.dump(self.data_list, open("04book.json", 'w')) # 统筹调用
def start(self): url_list = self.get_url_list() # 循环遍历发送请求
for url in url_list:
data = self.send_request(url)
# self.parse_xpath_data(data)
self.parse_bs4_data(data) self.save_data() BookSpider().start()
运行结果(下面利用了json转换)
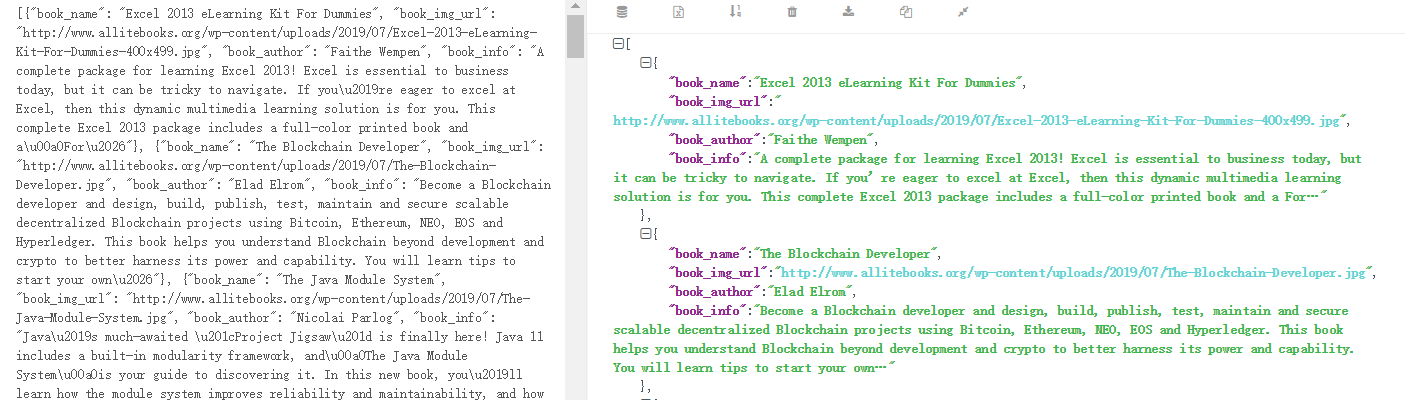
02-爬取http://www.allitebooks.org/网站,获取图片url,书名,简介,作者的更多相关文章
- 02. 爬取get请求的页面数据
目录 02. 爬取get请求的页面数据 一.urllib库 二.由易到难的爬虫程序: 02. 爬取get请求的页面数据 一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用 ...
- Python爬虫实例(一)爬取百度贴吧帖子中的图片
程序功能说明:爬取百度贴吧帖子中的图片,用户输入贴吧名称和要爬取的起始和终止页数即可进行爬取. 思路分析: 一.指定贴吧url的获取 例如我们进入秦时明月吧,提取并分析其有效url如下 http:// ...
- Jsoup爬取带登录验证码的网站
今天学完爬虫之后想的爬一下我们学校的教务系统,可是发现登录的时候有验证码.因此研究了Jsoup爬取带验证码的网站: 大体的思路是:(需要注意的是__VIEWSTATE一直变化,所以我们每个页面都需要重 ...
- Scrapy实战:爬取http://quotes.toscrape.com网站数据
需要学习的地方: 1.Scrapy框架流程梳理,各文件的用途等 2.在Scrapy框架中使用MongoDB数据库存储数据 3.提取下一页链接,回调自身函数再次获取数据 重点:从当前页获取下一页的链接, ...
- [Python] 快速爬取当前城市所有租房网站房源及配置,一目了然
Python爬取当前城市房源信息,以徐州为例代码效果图请看下方,其他部分请查看附件,一起学习,谢谢 # -*- coding: utf-8 -*- """ @Time : ...
- 没有内涵段子可以刷了,利用Python爬取段友之家贴吧图片和小视频(含源码)
由于最新的视频整顿风波,内涵段子APP被迫关闭,广大段友无家可归,但是最近发现了一个"段友"的app,版本更新也挺快,正在号召广大段友回家,如下图,有兴趣的可以下载看看(ps:我不 ...
- 亚马逊商品页面的简单爬取 --Pyhon网络爬虫与信息获取
1.亚马逊商品页面链接地址(本次要爬取的页面url) https://www.amazon.cn/dp/B07BSLQ65P/ 2.代码部分 import requestsurl = "ht ...
- Python 2.7_爬取CSDN单页面博客文章及url(二)_xpath提取_20170118
上次用的是正则匹配文章title 和文章url,因为最近在看Scrapy框架爬虫 需要了解xpath语法 学习了下拿这个例子练手 1.爬取的单页面还是这个rooturl:http://blog.csd ...
- 最简单的网络图片的爬取 --Pyhon网络爬虫与信息获取
1.本次要爬取的图片的url http://www.nxl123.cn/static/imgs/php.jpg 2.代码部分 import requestsimport osurl = "h ...
随机推荐
- DeWeb进阶 :控件开发 --- 1 完成一个纯html的demo
最近随着DeWeb(以下简称DW)的完善,和群友的应用的深入,已经有网友开始尝试做DeWeb支持控件的开发了! 这太令人兴奋了! 作为DeWeb的开发者,感觉DeWeb的优势之一就是简洁的第三方控件扩 ...
- MYSQL5.7下载安装图文教程
MYSQL5.7下载安装图文教程 一. MYSQL两种安装包格式 MySQL安装文件分为两种,一种是msi格式的,一种是zip格式的.zip格式相当于绿色版,不需要安装,只需解压缩之后就可以使用了,但 ...
- 从环境搭建到回归神经网络案例,带你掌握Keras
摘要:Keras作为神经网络的高级包,能够快速搭建神经网络,它的兼容性非常广,兼容了TensorFlow和Theano. 本文分享自华为云社区<[Python人工智能] 十六.Keras环境搭建 ...
- Git 修改已提交的commit注释
两种情况: 1.已经将代码push到远程仓库 2.还没将代码push到远程仓库,还在本地的仓库中 这两种情况下的修改大体相同,只是第一种情况最后会多一步 下面来说怎么修改 先搞清楚你要修改哪次的提交注 ...
- 添加su权限
在root用户下 visudo amy ALL=(ALL) NOPASSWD:ALL 在amy用户下 vim ~/.bashrc alias sd = "sudo"
- 【JAVA】笔记(3)---封装;如何选择声明静态变量还是实例变量;如何选择声明静态方法还是实例方法;静态代码块与实例代码块的执行顺序与用途;
封装: 1.目的:保证对象中的实例变量无法随意修改/访问,只能通过我们自己设定的入口,出口(set / get)来间接操作:屏蔽类中复杂的结构,使我们程序员在主方法中关联对象写代码时,思路/代码格式更 ...
- 前端jsdebug调试
前端如何像java一样的debug呢? 1.在js页面加入debugger next: function(){ debugger var type=this.quiz[this.progress].s ...
- 洛谷 P5401 - [CTS2019]珍珠(NTT+二项式反演)
题面传送门 一道多项式的 hot tea 首先考虑将题目的限制翻译成人话,我们记 \(c_i\) 为 \(i\) 的出现次数,那么题目的限制等价于 \(\sum\limits_{i=1}^D\lflo ...
- sar 系统活动情况报告
sar(System Activity Reporter系统活动情况报告)是目前 Linux 上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告, 包括:文件的读写情况.系统调用的使用 ...
- 【机器学习与R语言】10- 关联规则
目录 1.理解关联规则 1)基本认识 2)Apriori算法 2.关联规则应用示例 1)收集数据 2)探索和准备数据 3)训练模型 4)评估性能 5)提高模型性能 1.理解关联规则 1)基本认识 购物 ...