容器之分类与各种测试(四)——unordered_set和unordered_map
关于set和map的区别前面已经说过,这里仅是用hashtable将其实现,所以不做过多说明,直接看程序
unordered_set
#include<stdexcept>
#include<string>
#include<cstdlib>
#include<cstdio>
#include<algorithm>
#include<iostream>
#include<ctime>
#include<unordered_set>
using namespace std;
long get_a_target_long()
{
long target = 0;
cout<<"target(0~"<<RAND_MAX<<"):";
cin>>target;
return target;
}
string get_a_target_string()
{
long target = 0;
char buf[10];
cout<<"target(0~"<<RAND_MAX<<"):";
cin>>target;
snprintf(buf, 10, "%ld", target);
return string(buf);
}
int compareLongs(const void* a, const void* b)
{
return (*(long*)a - *(long*)b);
} int compareStrings(const void *a, const void *b)
{
if(*(string*)a > *(string*)b)
return 1;
else if(*(string*)a < *(string*)b)
return -1;
else
return 0;
}
void test_unordered_set(long& value)
{
cout << "\ntest_unordered_set().......... \n"; unordered_set<string> c;
char buf[10]; clock_t timeStart = clock();
for(long i=0; i< value; ++i)
{
try {
snprintf(buf, 10, "%d", rand());
c.insert(string(buf));
}
catch(exception& p) {
cout << "i=" << i << " " << p.what() << endl;
abort();
}
}
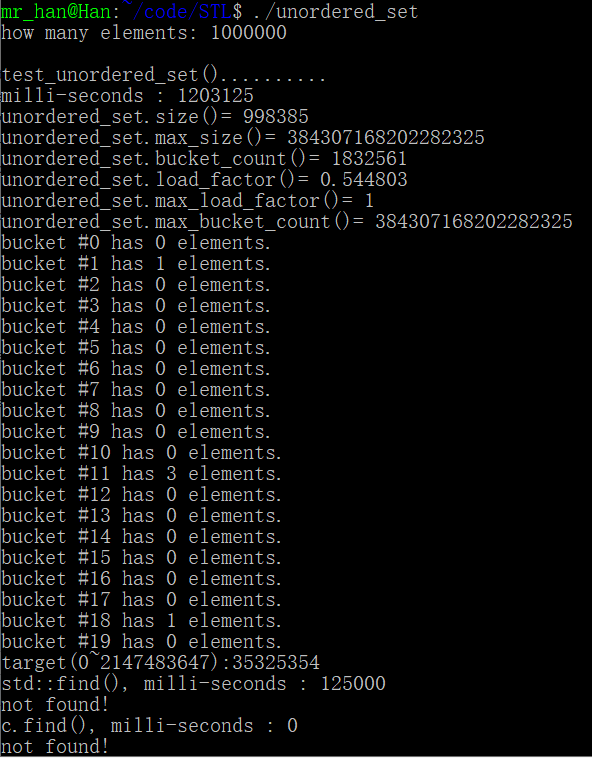
cout << "milli-seconds : " << (clock()-timeStart) << endl;
cout << "unordered_set.size()= " << c.size() << endl; //元素个数
cout << "unordered_set.max_size()= " << c.max_size() << endl; //
cout << "unordered_set.bucket_count()= " << c.bucket_count() << endl;//篮子个数
cout << "unordered_set.load_factor()= " << c.load_factor() << endl; //负载
cout << "unordered_set.max_load_factor()= " << c.max_load_factor() << endl;//最大负载
cout << "unordered_set.max_bucket_count()= " << c.max_bucket_count() << endl; //
for (unsigned i=0; i< 20; ++i) {
cout << "bucket #" << i << " has " << c.bucket_size(i) << " elements.\n";
} string target = get_a_target_string();
{
timeStart = clock();
auto pItem = find(c.begin(), c.end(), target); //比 c.find(...) 慢很多
cout << "std::find(), milli-seconds : " << (clock()-timeStart) << endl;
if (pItem != c.end())
cout << "found, " << *pItem << endl;
else
cout << "not found! " << endl;
} {
timeStart = clock();
auto pItem = c.find(target); //比 std::find(...) 快很多
cout << "c.find(), milli-seconds : " << (clock()-timeStart) << endl;
if (pItem != c.end())
cout << "found, " << *pItem << endl;
else
cout << "not found! " << endl;
}
}
int main()
{
long int value;
cout<<"how many elements: ";
cin>>value;
test_unordered_set(value);
return 0;
}
运行结果
unordered_map
#include<stdexcept>
#include<string>
#include<cstdlib>
#include<cstdio>
#include<algorithm>
#include<iostream>
#include<ctime>
#include<unordered_map>
using namespace std;
long get_a_target_long()
{
long target = 0;
cout<<"target(0~"<<RAND_MAX<<"):";
cin>>target;
return target;
}
string get_a_target_string()
{
long target = 0;
char buf[10];
cout<<"target(0~"<<RAND_MAX<<"):";
cin>>target;
snprintf(buf, 10, "%ld", target);
return string(buf);
}
int compareLongs(const void* a, const void* b)
{
return (*(long*)a - *(long*)b);
} int compareStrings(const void *a, const void *b)
{
if(*(string*)a > *(string*)b)
return 1;
else if(*(string*)a < *(string*)b)
return -1;
else
return 0;
}
void test_unordered_map(long& value)
{
cout << "\ntest_unordered_map().......... \n"; unordered_map<long, string> c;
char buf[10]; clock_t timeStart = clock();
for(long i=0; i< value; ++i)
{
try {
snprintf(buf, 10, "%d", rand());
c[i] = string(buf); //特殊的插入方式
}
catch(exception& p) {
cout << "i=" << i << " " << p.what() << endl;
abort();
}
}
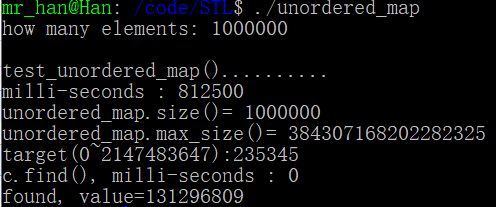
cout << "milli-seconds : " << (clock()-timeStart) << endl;
cout << "unordered_map.size()= " << c.size() << endl; //元素个数
cout << "unordered_map.max_size()= " << c.max_size() << endl; long target = get_a_target_long();
timeStart = clock(); auto pItem = c.find(target);//map 不用 std::find() cout << "c.find(), milli-seconds : " << (clock()-timeStart) << endl;
if (pItem != c.end())
cout << "found, value=" << (*pItem).second << endl;
else
cout << "not found! " << endl;
}
int main()
{
long int value;
cout<<"how many elements: ";
cin>>value;
test_unordered_map(value);
return 0;
}
运行结果
容器之分类与各种测试(四)——unordered_set和unordered_map的更多相关文章
- 容器之分类与各种测试(四)——unordered-multiset
unordered-multiset是不定序关联式容器,其底部是通过哈希表实现功能. (ps:黑色框就是bucket,白色框即为bucket上挂载的元素) 为了提高查找效率,bucket(篮子)的数量 ...
- 容器之分类与各种测试(四)——multiset
multiset是可重复关键字的关联式容器,其与序列式容器相比最大的优势在于其查找效率相当高.(牺牲空间换取时间段) 例程 #include<stdexcept> #include< ...
- 容器之分类与各种测试(四)——map
map和set的区别在于,前者key和value是分开的,前者的key不会重复,value可以重复:后者的key即为value,后者的value不允许重复.还有,map在插入时可以使用 [ ]进行(看 ...
- 容器之分类与各种测试(四)——set
set和multiset的去别在于前者的key值不可以重复,所以用随机数作为其元素进行插入时,遇到重复元素就会被拒绝插入(但是程序不会崩溃). 例程 #include<stdexcept> ...
- 容器之分类与各种测试(四)——unordered-multimap
unordered-multiset与unordered-multimap的区别和multiset与multimap的区别基本相同,所以在定义和插入时需要注意 key-value 的类型. 例程 #i ...
- 容器之分类与各种测试(四)——multimap
multiset和multimap的具体区别在于,前者的key值就是自己存储的value,后者的key与value是分开的不相关的. 例程 #include<stdexcept> #inc ...
- 容器之分类与各种测试(三)——stack
stack是栈,其实现也是使用了双端队列(只要不用双端队列的一端,仅用单端数据进出即完成单端队列的功能),由于queue和stack的实现均是使用deque,没有自己的数据结构和算法,所以这俩也被称为 ...
- 容器的分类与各种测试(二)——vector部分用法
向量 vector 是一种对象实体, 能够容纳许多其他类型相同的元素, 因此又被称为容器. 与string相同, vector 同属于STL(Standard Template Library, 标准 ...
- 容器之分类与各种测试(三)——queue
queue是单端队列,但是在其实现上是使用的双端队列,所以在queue的实现上多用的是deque的方法.(只要用双端队列的一端只出数据,另一端只进数据即可从功能上实现单端队列)如下图 例程 #incl ...
随机推荐
- 前端---梳理 http 知识体系 1
最近看了http相关的知识点,觉得还是有必要整理下,这样对自己的网络知识体系也有帮助. http 是什么 http叫超文本传输协议,可以拆成超文本.传输.协议来理解 协议 http 是一个用在计算机里 ...
- python编程中的流程控制
内容概要 成员运算 身份运算 流程控制 详细 1.成员运算 定义:判断某个个体在不在某个群体内 关键词:in(在) /// not in(不在) 例: num_list = [1, 2, 3, 4, ...
- vue脚手架配置代理
vue.config.js配置具体代理规则 module.exports = { devServer: { proxy: { '/api1': { // 匹配所有以 '/api1'开头的请求路径 ta ...
- 1.在项目中使用D3.js
在项目中使用D3.js D3.js(全称:Data-Driven Documents)是一个基于数据操作文档的JavaScript库.D3帮助您使用HTML.SVG和CSS使数据生动起来.D3对web ...
- Obsidian中如何记录自己的灵感?
在生活中当中你是否会在某个瞬间产生一个想法,但没过多久就想不起来了,正所谓灵感转瞬即逝,那我们不妨在灵感出现的时候顺手将他记录下来.记录的过程要求简单.方便且不会花费我们太多时间,下面我们介绍一下如何 ...
- PCB各层介绍
在PCB设计中用得比较多的图层: mechanical 机械层 keepout layer 禁止布线层 Signal layer 信号层 Internal plane layer 内部电源/接地层 t ...
- 本地以sysdba 身份登录数据库实例时,报错ORA-01031 权限不足
在linux 操作系统的数据库服务器上,使用"sqlplus / as sysdba" 登录Oracle 10.2 数据库实例时,登录失败,显示ORA-01031: 权限不足. ...
- IO流(一)
内容概要: Java以流的形式处理所有输入和输出.流是随通信路径从源移动到目的地的字节序列. 内存与存储设备之间传输数据的通道 流的分类: 按方向 输入流:将存储空间中的内容读到内存中 硬盘--& ...
- 13-Semi-supervised Learning
半监督学习(semi-supervised learning) 1.introduction 2.Semi-supervised Learning for Generative Model 3.Low ...
- MYSQL数据库重新初始化
前言 我们在日常开发过程中,可能会遇到各种mysql服务无法启动的情况,各种百度谷歌之后,依然不能解决的时候,可以考虑重新初始化mysql.简单说就是重置,"恢复出厂设置".重置之 ...