VAE变分自编码器
我在学习VAE的时候遇到了很多问题,很多博客写的不太好理解,因此将很多内容重新进行了整合。
我自己的学习路线是先学EM算法再看的变分推断,最后学VAE,自我感觉这个线路比较好理解。
一.首先我们来宏观了解一下VAE的作用:数据压缩和数据生成。
1.1数据压缩:
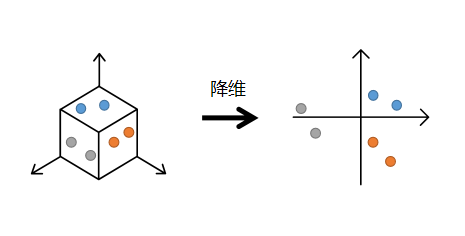
数据压缩也可以成为数据降维,一般情况下数据的维度都是高维的,比如手写数字(28*28=784维),如果数据维度的输入,机器的处理量将会很大, 而数据经过降维以后,如果保留了原有数据的主要信息,那么我们就可以用降维的数据进行机器学习模型的训练和预测,由于数据量大大缩减,训练和预测的时间效率将大为提高。还有一种好处就是我们可以将数据降维至2D或3D以便于观察分布情况。
平常最常用到的就是PCA(主成分分析法:将原来的三维空间投影到方差最大且线性无关的两个方向或者说将原矩阵进行单位正交基变换以保留最大的信息量)。
1.2数据生成:
近年来最火的生成模型莫过于GAN和VAE,这两种模型在实践中体现出极好的性能。
所谓数据的生成,就是经过样本训练后,人为输入或随机输入数据,得到一个类似于样本的结果。
比如样本为很多个人脸,生成结果就是一些人脸,但这些人脸是从未出现过的全新的人脸。又或者输入很多的手写数字,得到的结果也是一些手写数字。而给出的数据可能是一个或多个随机数,或者一个分布。然后经过神经网络,将输入的数据进行放大,得到结果。
1.3相互联系:
那么可能有人有疑问:VAE中数据压缩与数据生成有什么关系呢?
我们刚刚讲过,在数据生成过程中要输入一些数进去,可是这些数字不能是随随便便的数字吧,至少得有一定的规律性才能让神经网络进行学习(就像要去破译密码,总得知道那些个密码符号表示的含义是什么才可以吧)。
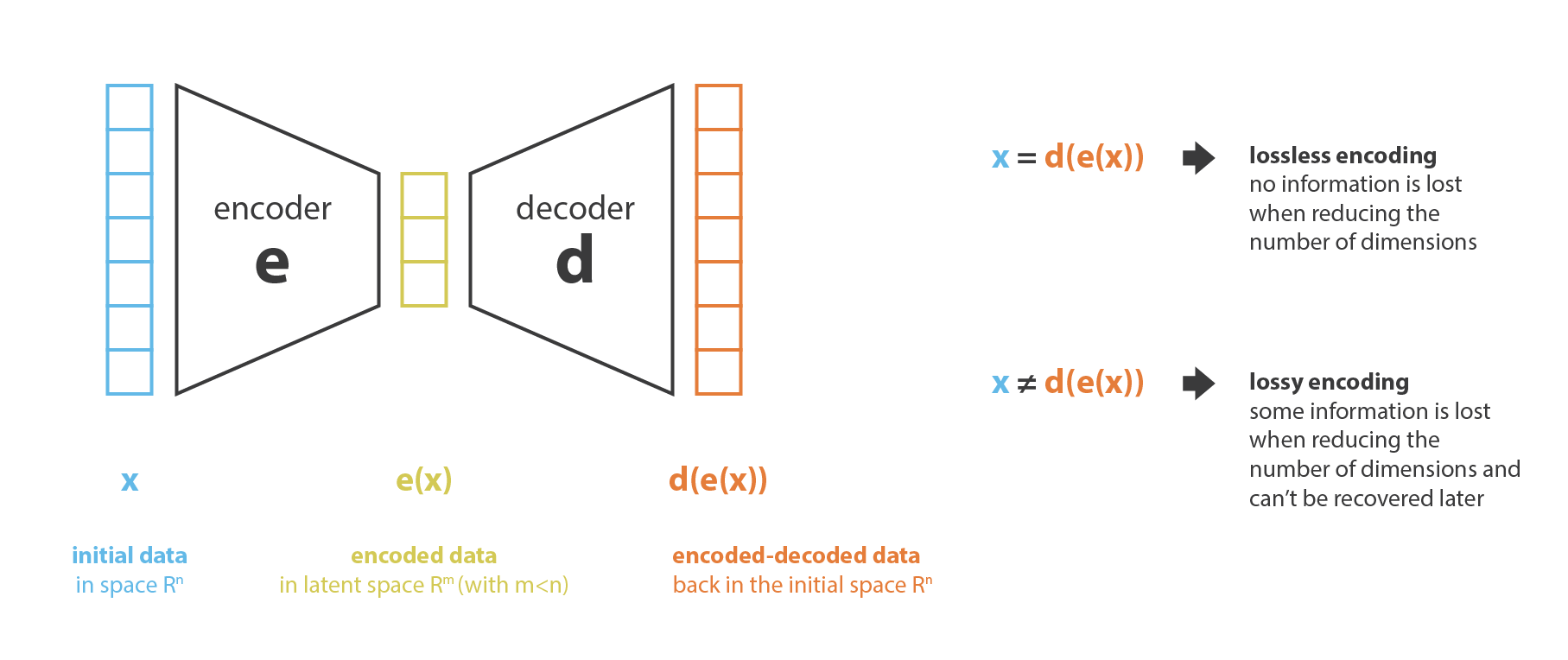
那如何获得输入数字(或者说密码)的规律呢。这就是数据压缩过程我们所要考虑的问题,我们想要获得数据经过压缩后满足什么规律,在VAE中,我们将这种规律用概率的形式表示。在经过一系列数学研究后:我们最终获得了数据压缩的分布规律,这样我们就可以根据这个规律去抽取样本进行生成,生成的结果一定是类似于样本的数据。
关于为什么将用概率来表示,我的理解是:变分自编码器是编码器的进化版本,但传统编码器鲁棒性比较差,以分布的形式引入,加入噪声的影响,使模型生成过程的鲁棒性加强。
1.4举个栗子:
对VAE有了宏观认识后,我们进行下一步学习
(后面的讲解我将以图片为例进行介绍)
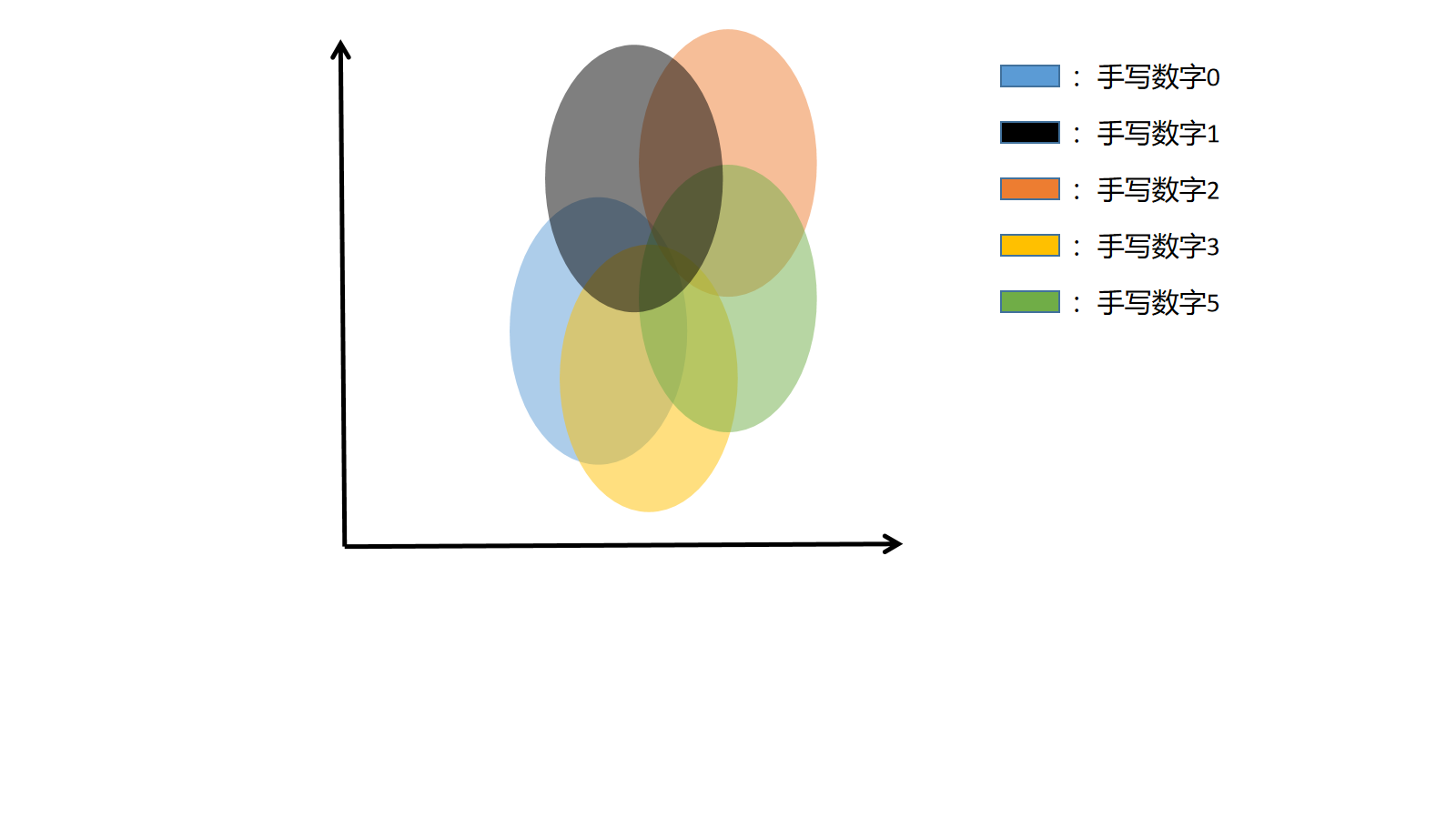
在前面讲解过,将图片进行某种编码,我们将图片编码为2维的高斯分布(也可以不是2维,只是为了好可视化),二维平面的中心就是图片的二维高斯分布的\(\mu\)(1)和\(\mu\)(2),表示椭圆的中心。
注意:这里其实不是椭圆,我们只是把最较大概率的部分框出来。
假设一共有5个图片(手写数字0-4),则在隐空间中一共有5个二维正态分布(椭圆),如果生成过程中在坐标中取的点接近蓝色区域,则说明,最后的生成结果接近数字0,如果在蓝色和黑色交界处,则结果介于0和1之间。
1.5出现的问题:
此时出现了一个问题,如果每个椭圆离得特别远会发生什么,椭圆之间完全没有交集。
假如随机取数据的时候,取的数据不在任何椭圆里,最后的生成的结果将会非常离谱,根本不知道生成模型生成了什么东西,我们称这种现象为过拟合,因此,我们必须要让这些个椭圆尽可能的推叠在一起,并且尽可能占满整个空间的位置,防止生成不属于任何分类的图片。后面我们会介绍如何将椭圆尽可能堆叠。
在解决上面那个问题后,我们就得到了一个较为标准的数据压缩形态,这样我们就可以放心采样进行数据生成。
1.6VAE框架:
到现在为止,VAE框架已经形成:
•隐空间有规律可循,长的像的图片离得近
•隐空间随便拿个点解码之后,得到的点有意义。
•隐空间中对应不同标签的点不会离得很远,但也不会离得太近(因为每个高斯的中心部分因为被采样次数多必须特色鲜明,不能跟别的类别的高斯中心离得太近)(VAE做生成任务的基础)
•隐空间对应相同标签的点离得比较近,但又不会聚成超小的小簇,然而也不会有相聚甚远的情况(VAE做分类任务的基础)
二.理论推导VAE
我们接下来从理论的角度进行讲解:
通过刚刚的讲解,读者一定有一个疑问,怎么去求那么复杂的高斯分布也就是隐空间呢,这个问题与变分推断遇到的几乎一样。
2.1引入变分
在变分推断中,我们想要通过样本x来估计关于z的分布,也就是后验,用概率的语言描述就是:p(z|x)。根据贝叶斯公式:
\]
我们不能直接求p(x)所以直接贝叶斯这个方法报废,于是我们寻找新的方法。
这时我们想到了变分法,用另一个分布Q(z|x)来估计p(z|x,\(\theta\)),变分自编码器的变分就来源于此。
用一个函数去近似另一个函数,可以看作从概率密度函数所在的函数空间到实数域R的一个函数f,自变量是Q的密度函数,因变量是Q与真实后验密度函数的“距离”,而这一个f关于概率密度函数的“导数”就叫做“变分”,我们每次降低这个距离,让Q接近真实的后验,就是让概率密度函数朝着“导数“的负方向进行函数空间的梯度下降。所以叫做变分推断。
变分推断和变分自编码器的最终目标是相同的,都是将Q(z|x)尽量去近似p(z|x,\(\theta\)),我们知道有一种距离可以量化两种分布的差异Kullback-Leibler divergence—KL散度,我们要尽量减小KL散度。
2.2KL散度
接下来我们进行公式的推导:
&KL[Q(z \mid x) \| p(z \mid x)]=E_{z \sim Q}[\log Q(z \mid x)-\log p(z \mid x)] \\
&=E_{z \sim Q}[\log Q(z \mid x)-\log p(x \mid z)-\log p(z)]+\log p(x)
\end{aligned}
\]
整理得:
&\log p(x)-KL[Q(z \mid x) \| p(z \mid x)]=E_{z \sim Q(z \mid x)}[\log p(x \mid z)]-KL[Q(z \mid x) \| p(z)]
\end{aligned}
\]
观察这个复杂的式子:
(1)左边第一个是样本的对数似然,第二项是Q和p的KL散度。
(2)右边第一项的意思是:给定的x,我们将其编码为z,然后再重构x的似然函数值的期望。如果这个期望比较大,说明得到的z是x的一个比较好的表示,能够抽取出x的足够多的信息以重构x。如果重构效果很好,说明Q(z|x)足够拟合p(z|x)效果很好,生成效果好。
(3)右边第二项看起来很奇怪,里面出现里p(z)隐变量z的先验分布。这里算的是Q(z|x)与p(z)的距离。还记得前面我们说过存在一个过拟合问题吗,就是Q(z|x)分布及其发散,会生成奇怪的数据,我们要将他们堆叠起来满足一定规律性,然而自然界什么分布最具有普遍性呢?当然是正态分布,因此我们假设z的先验分布服从标准正态分布
\]
很关键的一点是我们一定要清楚每一个样本x都对应一个正态分布Q (z|x)。每一个Q (z|x)都希望尽可能的去靠近正态分布。
这部分关于p(z)的分布与Q(z|x)的关系非常难理解,我的理解是,尽可能地将多个分布堆叠,尽量多的去覆盖整个空间防止取到分布概率非常低的点造成生成奇怪的东西。
2.3ELBO
再次整理上式:
\]
变分推断的目的是:最大化似然函数p(x),假设Q和p已经同分布了,等式左边等于0,因此我们的目标就转移为最大化ELBO。
这里的分析与变分推断完全一样,不理解的话可以去看一下变分推断的具体推导。
\]
接下来我们最大化ELBO:
L2,KL散度的简化
\]
这里面的Q(z|x)是一个样本特有的分布,我们希望Q(z|x)去近似正态分布。而且Q (z|x)可以是一个多元的高斯分布。
将L2化简(化简步骤复杂,不要求理解)
\]
\]
这里的 d 是隐变量 Z 的维度(或者说高斯分布的维度),而 μ(i) 和 σ(i) 分别代表一般正态分布的均值向量和方差向量的第 i 个分量。
L1,期望部分的简化
假设p ( x ∣ z )服从伯努利分布:
原论文里面写出,encoder过程使用高斯分布P(z|X),decoder过程使用伯努利分布或者高斯分布p(x|z),在这里我们使用伯努利分布进行分析。
\]
\]
再decoder过程中,我们将z输入,通过MLP得到y,再将y带入伯努利的概率分布公式中,从而得到
这里面y是decoder的生成结果
\]
过程如下图所示(图中展示的是decoder过程的高斯分布):
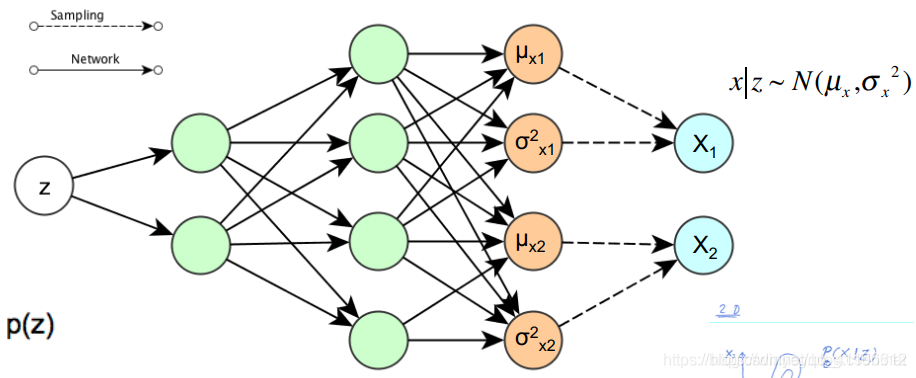
非常巧合的是,如果输出是一个伯努利分布,满足:
\]
BCE是原样本x和生成结果y的BCE_Loss
观察我们要求的L1部分,现在我们将 log p ( x ∣ z ) 进行化简(BCE_loss),现在该求期望了。
但是对于对数似然期望的求解会是一个十分复杂的过程,所以采用MC算法,将L1等价于:
\]
\]
\]
将上面求的 log( x | z )代入上式就的到最后结果。
2.4公式整合
将上面的L1和L2相加得到ELBO的计算式,最大化ELBO即可。
为了方便读者理解和阅读,在这里,我把公式进行了归纳。
下面展示的是原始公式:
E L B O=E_{z \sim Q(z \mid x)}[\log p(x \mid z)]-K L[Q(z \mid x) \| p(z)] \\
K L\left[Q(z \mid x) \| p(z)=\frac{1}{2} \sum_{i=1}^{d}\left(\mu_{(i)}^{2}+\sigma_{(i)}^{2}-\log \sigma_{(i)}^{2}-1\right)\right. \\
\log p(X \mid z)=\sum_{i=1}^{D} x_{i} \log y_{i}+\left(1-x_{i}\right) \log \left(1-y_{i}\right)=B C E \\
\mathrm{E}_{Q(z \mid x)}(\log (p(x \mid z))) \approx \frac{1}{L} \sum_{l=1}^{L} \log p\left(x \mid z^{(l)}\right)
\end{array}\right.
\]
经过代入推导整理得:
E L B O=\frac{1}{L} \sum_{l=1}^{L} \sum_{i=1}^{D} x_{i} \log y_{i}+\left(1-x_{i}\right) \log \left(1-y_{i}\right)-\frac{1}{2} \sum_{i=1}^{d}\left(\mu_{(i)}^{2}+\sigma_{(i)}^{2}-\log \sigma_{(i)}^{2}-1\right) \\
\mathbf{y}=\operatorname{sigmoid}\left(\mathbf{W}_{2} \tanh \left(\mathbf{W}_{1} \mathbf{z}+\mathbf{b}_{1}\right)+\mathbf{b}_{2}\right)
\end{array}\right.
\]
w1,w2,b1,b2是decoder神经网络参数。
我们观察这个ELBO,发现里面的μ(i) 和 σ(i) 我们是不知道的。
也就是现在我们已经知道如何去算LOSS了,而且知道数学本质是什么,但是最初的那个问题还没有解决,也就是隐变量的分布Q(z|x)我们仍旧不清楚。
我们只知道用 Q ( z | x ) 去拟合 P( z | x )并且给出了一个数学公式判断拟合效果。但是我们不会求Q(z|x)。
如果了解过变分推断就知道,在变分推断里面用平均场理论直接硬推出了Q的迭代公式,但是如果z的变量数很多,平均场理论的就不太行了。
因此我们将眼光看向神经网络,神经网络时代,我们喜欢用一个网络去拟合各种数值,当然,我们也可以用网络去不断迭代计算μ(i) 和 σ(i)。
接下来给出μ(i) 和 σ(i)的神经网络框架:
\log Q(\mathbf{z} \mid \mathbf{x}) &=\log \mathcal{N}\left(\mathbf{z} ; \boldsymbol{\mu}, \boldsymbol{\sigma}^{2} \mathbf{I}\right) \\
\text { where } \boldsymbol{\mu} &=\mathbf{W}_{5} \mathbf{h}+\mathbf{b}_{5} \\
\log \boldsymbol{\sigma}^{2} &=\mathbf{W}_{4} \mathbf{h}+\mathbf{b}_{4} \\
\mathbf{h} &=\tanh \left(\mathbf{W}_{3} \mathbf{z}+\mathbf{b}_{3}\right)
\end{aligned}
\]
我们分别用两个网络分别去算 μ 和 σ 。
注意:这里有一点非常关键,一个样本或者说一个图片对应一个正态分布,这样才能在后面的生成过程找到对应的生成结果。
如下图所以:
这张图片来自知乎变分自编码器VAE
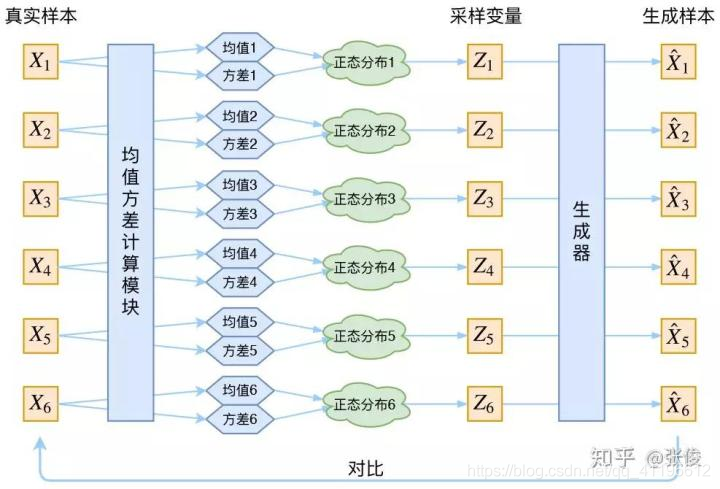
2.5参数更新
ok,现在我们把整个ELBO都求出来了,下一步是什么呢?
当然是进行参数更新,这里我们采用随机梯度下降进行参数更新。
但是在生成过程中,z是在分布中随机进行采样的,这样会导致无法进行求导,进而前面求Q( z | x )的网络参数无法进行更新,那么该如何解决这个问题呢?
因此我们需要用到一种新的技巧:重参数化
再次回顾我们为什么要进行重参数,因为在训练过程中,由于z的采样,导致梯度断裂,在BP的过程中,误差需要穿过一个采样层,该操作不连续且没有梯度。SGD可以处理随机输入,但不能处理随机操作!解决方法称为 “重新参数化”,先采样ϵ ∼ N ( 0 , I ) ,然后让:
\]
所以“重参数化”的目的就是为了让模型可以求导,进而可以用SGD求解。
三.对于VAE的一些理解
到目前为止,相比大家对VAE已经基本认识了,下面我从直观的角度上进行一些讲解(当然这些不是我自己想出来的,在经过大量阅读文献和大佬的博客归纳出来的内容)
3.1 Question1
读者肯定在思考一个问题(其实是我一直在思考的):为什么需要p(z|x)尽可能的接近正态分布呢?
3.1.1解答:
我们先想一下什么时候重构误差最小呢(也就是前面的BCE_loss),当然是对z进行采样的时候方差为0,直接取均值的时候误差可以做到最小,这样几乎就是屏蔽了噪声的影响,但是这样的话变分自编码器和编码器将会没有区别,将样本编码为概率分布将没有意义,为了防止这个情况发生,或者说为了防止前面的encoder算σ(i)的时候全都计算成0,我们让p(z|x)向标准正态看齐,也就是限制σ(i),让他接近1。
3.1.2还有一种理解是:
VAE作为生成模型就是在潜变量的空间里面,寻找训练集投影集中的地方然后采样就行了,只不过需要通过约束训练集投影在集中在零向量附近,要不然因为高维空间的稀疏性,随便选择,模型重构结果肯定很差。
我的理解是会造成过拟合。
如果p(z|x)变成正态分布了,我们看看会发生什么:
\]
很神奇,p(Z)满足了标准正态分布,也就是我们进行生成的时候,保证了z的随机性,或者说保证了生成能力。
所以前面我们可以最小化下面这个式子理解为保证模型的生成能力。
\]
3.2VAE的对抗性
我们的公式中的终极目标是最大化ELBO,既要最大化前面的期望,又要最小化后面的KL散度
\]
我们来分析一下这个过程,假如刚开始,期望很大,也就是模型的生成能力比较弱,我们就会适当降低噪声(KL loss 增加),使得拟合起来容易一些(重构误差开始下降)。
反之,如果生成模型训练得还不错时(重构误差小于 KL loss),这时候噪声就会增加(KL loss 减少),使得拟合更加困难了(重构误差又开始增加),这时候生成模型就要想办法提高它的生成能力了。
但是最终得到的Q(z|x)一定不是正态分布,因为模型刚开始训练,loss集中在重构误差上,只有到重构误差比较小的时候,KL_loss才会有作用,可以将kl_loss理解为一个正则化项。
3.3 Question2
有个问题:既然隐含变量z的最终目标是往正态分布(0,1)走,那为什么不一开始就按照正态分布采样然后只训练右边似然估计的网络呢,为什么还要设计并且计算左边的呢?
解答:
我们并不能说标准正态分布是 z 的“最终”目标。
让 z 往标准正态看齐,只是为了方便对 z 采样。不妨这么看,对于一个没有训练过的 encoder(左侧网络),它会把每个 X 胡乱映射成不同的后验分布 p(z|X) ,东边一坨,西边一坨的。整个训练的过程就是把所有这些 p(z|X) 往 N(0, 1) 拉拢,但是呢,又不太可能可能完美“重合”,因为 decoder(右侧网络)是要通过采样 z 还原 X 的。
直觉地看,这也是一个竞争过程,我们可以把 p(z|X) 与 N(0,1) 的KL散度看作“吸引力”,而对重构的要求是“排斥力”。
3.4隐变量空间z到底是什么东西?
在我看来,隐变量空间是提取了样本的多个特征,将特征转化为概率的分布,以概率的方式描述潜在空间观察。
举一个例子,假设我们在编码维数为6的大型人脸数据集上训练了一个自编码器模型。理想的自编码器将学习人脸的描述性属性,如肤色、是否戴眼镜等,以试图用一些压缩的表示来描述观察。

我们可能更倾向于将每个潜在属性表示为可能值的范围。例如,如果输入蒙娜丽莎的照片,你会为微笑属性分配什么样的单值?使用变分自编码器,我们可以用概率术语来描述潜在属性。
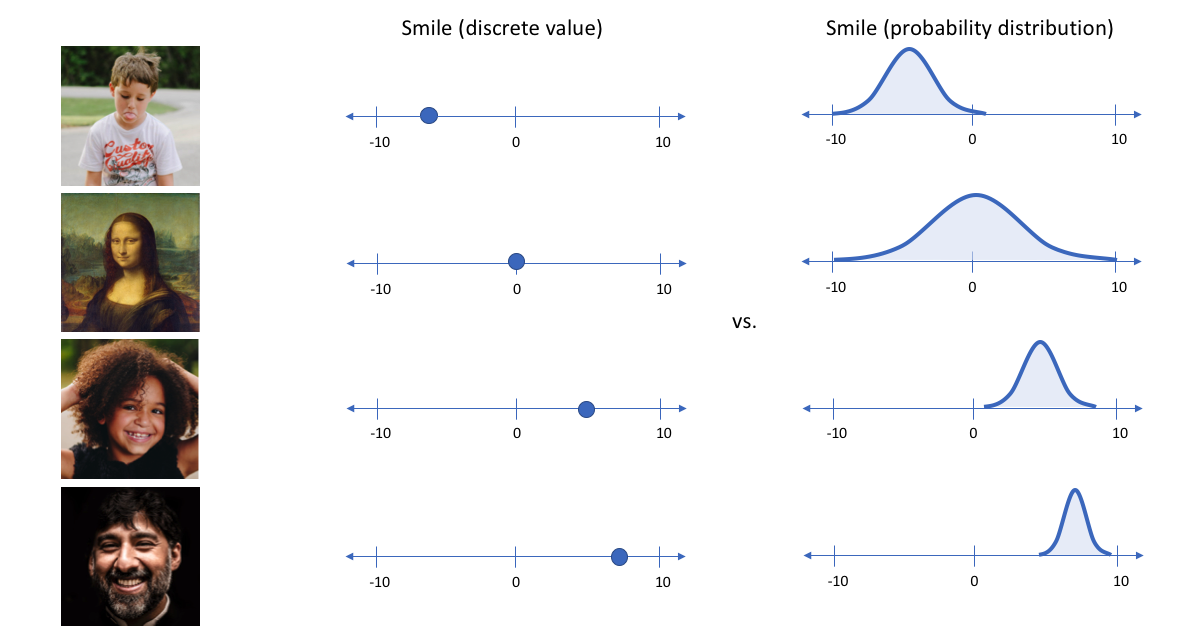
通过这种方法,我们现在将给定输入的每个潜在属性表示为概率分布。当从潜在状态解码时,我们将从每个潜在状态分布中随机采样,生成一个向量作为解码器模型的输入。
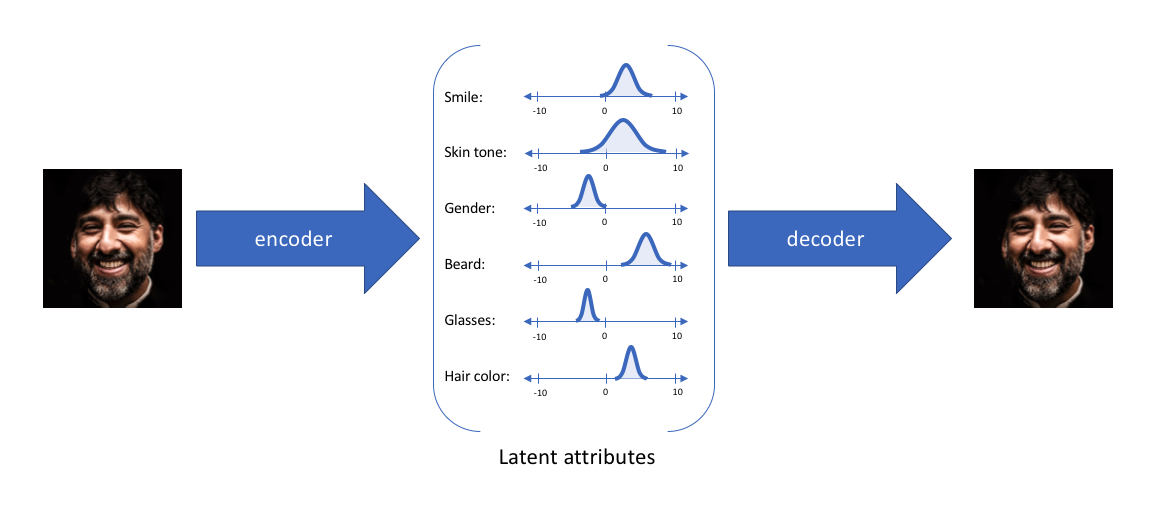
注意:对于变分自编码器,编码器模型有时被称为识别模型(recognition model ),而解码器模型有时被称为生成模型。
通过构造我们的编码器模型来输出可能值的范围(统计分布),我们将随机采样这些值以供给我们的解码器模型,我们实质上实施了连续,平滑的潜在空间表示。对于潜在分布的所有采样,我们期望我们的解码器模型能够准确重构输入。因此,在潜在空间中彼此相邻的值应该与非常类似的重构相对应。
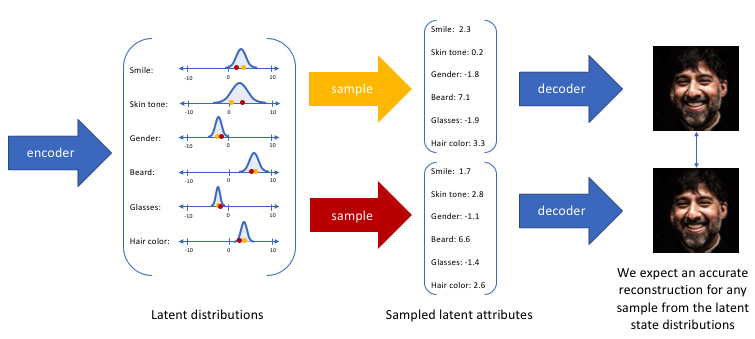
四.写在最后
这篇文章是我进行学习时的一些想法和总结,当然里面肯定还是存在不少问题,博主目前大二,对于很多知识的理解都不太到位,如果有误,尽请指出,希望不会对读者进行误导。
放一些文章供大家参考:
1.这个里面有pytorch的代码
2.比较直观的一种理解
3.重点关注对VAE的理解
VAE变分自编码器的更多相关文章
- VAE变分自编码器实现
变分自编码器(VAE)组合了神经网络和贝叶斯推理这两种最好的方法,是最酷的神经网络,已经成为无监督学习的流行方法之一. 变分自编码器是一个扭曲的自编码器.同自编码器的传统编码器和解码器网络一起,具有附 ...
- Variational Auto-encoder(VAE)变分自编码器-Pytorch
import os import torch import torch.nn as nn import torch.nn.functional as F import torchvision from ...
- (转) 变分自编码器(Variational Autoencoder, VAE)通俗教程
变分自编码器(Variational Autoencoder, VAE)通俗教程 转载自: http://www.dengfanxin.cn/?p=334&sukey=72885186ae5c ...
- 变分自编码器(Variational Autoencoder, VAE)通俗教程
原文地址:http://www.dengfanxin.cn/?p=334 1. 神秘变量与数据集 现在有一个数据集DX(dataset, 也可以叫datapoints),每个数据也称为数据点.我们假定 ...
- 4.keras实现-->生成式深度学习之用变分自编码器VAE生成图像(mnist数据集和名人头像数据集)
变分自编码器(VAE,variatinal autoencoder) VS 生成式对抗网络(GAN,generative adversarial network) 两者不仅适用于图像,还可以 ...
- 变分自编码器(Variational auto-encoder,VAE)
参考: https://www.cnblogs.com/huangshiyu13/p/6209016.html https://zhuanlan.zhihu.com/p/25401928 https: ...
- 基于变分自编码器(VAE)利用重建概率的异常检测
本文为博主翻译自:Jinwon的Variational Autoencoder based Anomaly Detection using Reconstruction Probability,如侵立 ...
- 变分推断到变分自编码器(VAE)
EM算法 EM算法是含隐变量图模型的常用参数估计方法,通过迭代的方法来最大化边际似然. 带隐变量的贝叶斯网络 给定N 个训练样本D={x(n)},其对数似然函数为: 通过最大化整个训练集的对数边际似然 ...
- 基于图嵌入的高斯混合变分自编码器的深度聚类(Deep Clustering by Gaussian Mixture Variational Autoencoders with Graph Embedding, DGG)
基于图嵌入的高斯混合变分自编码器的深度聚类 Deep Clustering by Gaussian Mixture Variational Autoencoders with Graph Embedd ...
随机推荐
- IDEA 修改之前保存的git地址的账号和密码
1.打开控制面板 快捷键 win+R,然后输入control,打开控制面板 2.用户账户 3.管理windows凭据 4.点击里面的git就可以修改了
- UDP&串口调试助手用法(1)
一览 UDP 串口 常用 功能概述 概览 支持UDP通信协议: 广播.单播.组播 支持串口通信 配置了常用的配置,常用的进制转化: 2进制,8进制,10进制,和16进制之间的转换 配置了 计算器,加减 ...
- 【LeetCode】225. Implement Stack using Queues 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 日期 题目地址:https://leetcode.c ...
- 【LeetCode】747. Largest Number At Least Twice of Others 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 寻找两次最大值 排序 大顶堆 日期 题目地址:htt ...
- 1076 - Get the Containers
1076 - Get the Containers PDF (English) Statistics Forum Time Limit: 2 second(s) Memory Limit: 32 ...
- 【C/C++笔记】友元类函数
最近学了友元,有三个用法: 1友元函数 2友元类 3友元类函数 我发现友元类函数的用法要比上两个用法要严格,不按格式写会各种出错,要把两个类都拆开来写,共分4步. 第一步: class A; //有 ...
- P4081 [USACO17DEC]Standing Out from the Herd P
知识点: 广义 SAM 原题面 Luogu 「扯」 随便「口胡」一下居然「过」了. 比较考验「代码能力」,第一次感觉「大模拟」没有白写((( 还有这个「符号」实在是太「上头」了. 前置知识 在线构造广 ...
- Exponential family of distributions
目录 定义 性质 极大似然估计 最大熵 例子 Bernoulli 指数分布 正态分布 Choi H. I. Lecture 4: Exponential family of distributions ...
- MySQL数据操作与查询笔记 • 【第3章 DDL 和 DML】
全部章节 >>>> 本章目录 3.1 使用 DDL 定义数据库表结构 3.1.1 SQL 简介 3.1.2 维护数据库和创建数据表 3.2 使用 DDL 维护数据库表结构 ...
- SpringBoot 之 实现登录功能及登录拦截器
增加登录退出控制器: # src/main/java/com/wu/controller/LoginController.java @Controller public class LoginCont ...