【论文考古】知识蒸馏 Distilling the Knowledge in a Neural Network
论文内容
G. Hinton, O. Vinyals, and J. Dean, “Distilling the Knowledge in a Neural Network.” 2015.
如何将一堆模型或一个超大模型的知识压缩到一个小模型中,从而更容易进行部署?
训练超大模型是因为它更容易提取出数据的结构信息(为什么?)
知识应该理解为从输入到输出的映射,而不是学习到的参数信息
模型的泛化性来源于错误答案的相对概率大小(一辆宝马被误判为卡车的概率大于被误判为萝卜的概率),而泛化性是学习的终极目标
基本构架:学习高温Softmax之后的值
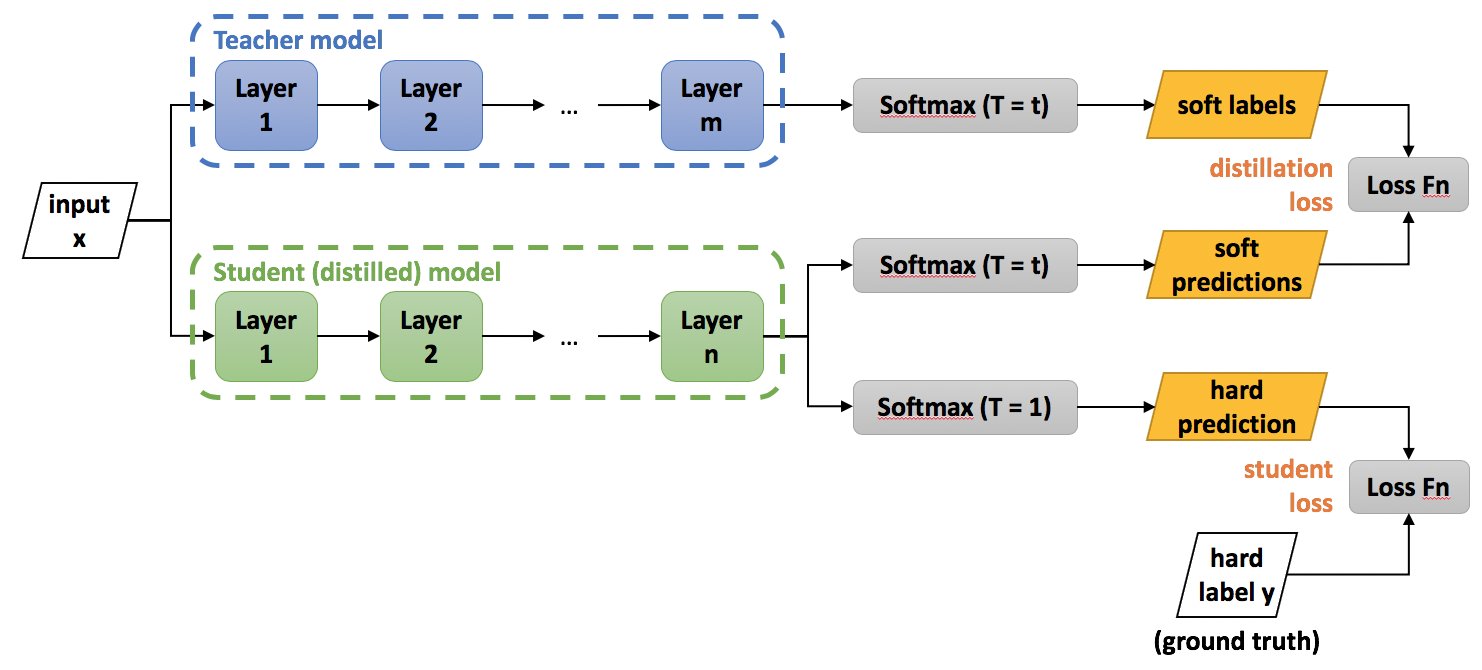
超大数据集下如何训练?
论文给出的方法:用专家模型独立训练容易混淆的数据,在准确率略微提高的基础上,将训练时间从许多周缩短为几天
模型集合是一个针对所有数据的generalist model和许多针对相近数据的专家模型。训练专家模型时,用generalist model的参数进行初始化(这样可以防止过拟合),训练数据一半是相近数据的集合,一半是随机选取的其他数据
(correct for the biased training set by incrementing the logit of the dustbin class by the log of the proportion by which the specialist class is oversampled 应该如何理解?)
分配不同种类到专家模型:将容易混淆的预测进行聚类,从而分配到专家模型
最后对包含专家模型的一组神经网络进行知识蒸馏,提炼成一个同样大小的单一神经网络,方便部署
实际效果
泛化性的检验:在MNIST数据集中,仅靠知识蒸馏,能识别出缺失的某张图片吗?
金句启发
把dropout和分布式学习相结合?
Dropout can be viewed as a way of training an exponentially large ensemble of models that share weights.
FL的特点在于数据不能共享,所以不能在服务器端做模型融合。能不能做一个分布式的知识蒸馏,用专家模型解决异构数据的难点?
【论文考古】知识蒸馏 Distilling the Knowledge in a Neural Network的更多相关文章
- 【DKNN】Distilling the Knowledge in a Neural Network 第一次提出神经网络的知识蒸馏概念
原文链接 小样本学习与智能前沿 . 在这个公众号后台回复"DKNN",即可获得课件电子资源. 文章已经表明,对于将知识从整体模型或高度正则化的大型模型转换为较小的蒸馏模型,蒸馏非常 ...
- Distilling the Knowledge in a Neural Network
url: https://arxiv.org/abs/1503.02531 year: NIPS 2014   简介 将大模型的泛化能力转移到小模型的一种显而易见的方法是使用由大模型产生的类概率作 ...
- 1503.02531-Distilling the Knowledge in a Neural Network.md
原来交叉熵还有一个tempature,这个tempature有如下的定义: \[ q_i=\frac{e^{z_i/T}}{\sum_j{e^{z_j/T}}} \] 其中T就是tempature,一 ...
- 论文阅读笔记十八:ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation(CVPR2016)
论文源址:https://arxiv.org/abs/1606.02147 tensorflow github: https://github.com/kwotsin/TensorFlow-ENet ...
- 论文阅读笔记六十四: Architectures for deep neural network based acoustic models defined over windowed speech waveforms(INTERSPEECH 2015)
论文原址:https://pdfs.semanticscholar.org/eeb7/c037e6685923c76cafc0a14c5e4b00bcf475.pdf 摘要 本文研究了利用深度神经网络 ...
- 论文翻译:2020_Acoustic Echo Cancellation Based on Recurrent Neural Network
论文地址:https://ieeexplore.ieee.org/abstract/document/9306224 基于RNN的回声消除 摘要 本文提出了一种基于深度学习的语音分离技术的回声消除方法 ...
- 论文笔记:Person Re-identification with Deep Similarity-Guided Graph Neural Network
Person Re-identification with Deep Similarity-Guided Graph Neural Network 2018-07-27 17:41:45 Paper: ...
- Deeplearning知识蒸馏
Deeplearning知识蒸馏 merge paddleslim.dist.merge(teacher_program, student_program, data_name_map, place, ...
- 论文解读(GCC)《GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training》
论文信息 论文标题:GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training论文作者:Jiezhong Qiu, Qibi ...
随机推荐
- linux获取 GPG 密钥失败
实质性问题就是自己系统没有yum的GPG密钥 查看自己系统版本 cat /etc/issue 登陆mirrors.163.com 找到自己系统对应的密钥 RPM-GPG-KEY-CentOS-3 ...
- Java 集合详解 | 一篇文章解决Java 三大集合
更好阅读体验:Java 集合详解 | 一篇文章搞定Java 三大集合 好看的皮囊像是一个个容器,有趣的灵魂像是容器里的数据.接下来讲解Java集合数据容器. 文章篇幅有点长,还请耐心阅读.如只是为了解 ...
- 整理全网最全K8S集群管理工具、平台
整理常见的整理全网最全K8S集群管理工具.平台解决方案. 1 Rancher Rancher中文官网:https://docs.rancher.cn/ 2 KubeSphere 官网:https:// ...
- node.js request请求url错误:证书已过期 Error: certificate has expired
场景: node:8.9.3版本 报错代码: Error: certificate has expired at TLSSocket.<anonymous> (_tls_wrap.js:1 ...
- Go语言切片一网打尽,别和Java语法傻傻分不清楚
前言 我总想着搞清楚,什么样的技术文章才算是好的文章呢?因为写一篇今后自己还愿意阅读的文章并不容易,暂时只能以此为目标努力. 最近开始用Go刷一些题,遇到了一些切片相关的细节问题,这里做一些总结.切片 ...
- dfs时间复杂度分析
前言 之前一直想不明白dfs的时间复杂度是怎么算的,前几天想了下大概想明白了,现在记录一下. 存图方式都是链式前向星或邻接矩阵.主要通过几道经典题目来阐述dfs时间复杂度的计算方法. $n$是图中结点 ...
- python 单元测试 执行测试
1.在unittest框架中执行测试用例: if __name__ == "__main__": unittest.main() # unittest框架会把以test_开头的实例 ...
- 如何在pyqt中自定义无边框窗口
前言 之前写过很多关于无边框窗口并给窗口添加特效的博客,按照时间线罗列如下: 如何在pyqt中实现窗口磨砂效果 如何在pyqt中实现win10亚克力效果 如何在pyqt中通过调用SetWindowCo ...
- js-reduce方法源码
// 数组中的reduce方法源码复写 //先说明一下reduce原理:总的一句,reduce方法主要是把数组遍历, //然后把数组的每个元素传入回调函数中,回调函数怎么处理,就会的到什么样的效果 A ...
- SimpleDateFormat简介及替代方案
简介 SimpleDateFormat是一个时间格式化工具,可以将字符串格式化时间Date类型,也可以将Date类型格式化为字符串String类型,但其线程不安全. 常用方法 public final ...